Orchestrate AI insights into action
Aviation-Grade Document AI. Precision That Performs.
June 11, 2025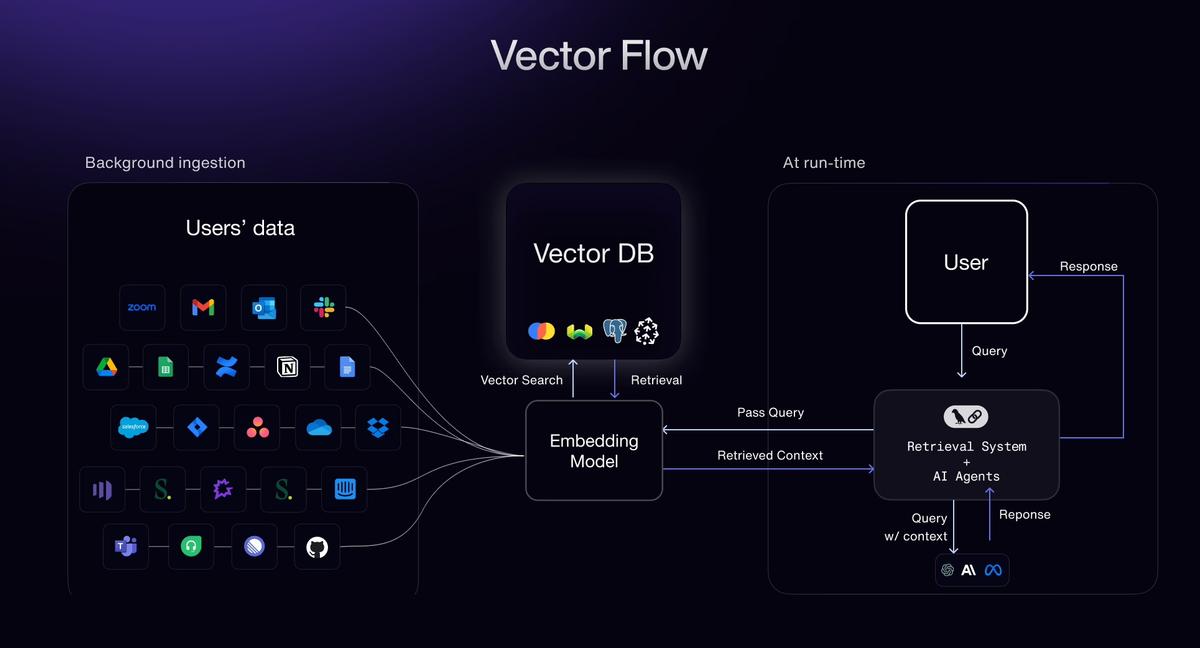
Introduction: Aviation’s Document Deluge and the Accuracy Imperative
The aviation industry is inundated with critical documents – Airworthiness Certificates, Illustrated Parts Catalogs (IPCs), maintenance manuals, FAA Service Bulletins/Airworthiness Directives, logbooks, and more. These unstructured, high-volume documents are the lifeblood of aviation operations and compliance. For example, a single U.S. commercial aircraft can produce up to 7,500 pages of new documents per year to meet DOT and FAA requirements. Ensuring that AI systems can reliably interpret and utilize this mountain of data is non-negotiable. In building aviation-grade AI, one principle stands out: the quality of AI outputs is only as good as the accuracy of the underlying data extraction. In other words, if your document data extraction is flawed, even the most advanced AI model will propagate those errors – a classic “garbage in, garbage out” scenario. AI leads and technical teams must therefore prioritize high-precision document data extraction as the foundation of any aviation AI pipeline.
Unstructured Data in Aviation: Challenges and Necessity
Aviation enterprises depend on unstructured documents for everything from regulatory compliance to daily operations. Consider just a few examples:
- Regulatory Documents: Airworthiness certificates, FAA Service Bulletins (SB) and Airworthiness Directives (AD) bulletins, safety certifications, and incident reports are mandatory and audited frequently. Any incorrect detail can result in compliance violations or grounded aircraft.
- Technical Manuals: Maintenance Manuals and IPCs contain intricate part numbers, assembly diagrams, and procedures that engineers and mechanics rely on. These often span thousands of pages and come in varied formats (scanned PDFs, legacy prints), making automated parsing difficult.
- Operational Logs: Pilot logbooks, maintenance logs, and work orders capture ongoing operational data. They are usually free-form and handwritten or typed, adding another layer of complexity for extraction.
- Procurement & Inventory Docs: Illustrated Parts Catalogs and parts lists, Requests for Quotation (RFQs), purchase orders, and warranty records are used for parts procurement and inventory management. Errors in extracting part numbers or quantities can lead to costly inventory mistakes.
Dealing with this document deluge is challenging because the data is unstructured – trapped in natural language descriptions, tables, and forms. It’s estimated that 80% of enterprise data is unstructured, hiding in PDFs, emails, and scanned forms. Aviation firms know this pain well: according to IDC, employees can spend ~30% of their time simply searching for and consolidating information across documents. The consequence of poor data quality is severe – IBM has estimated that bad data costs the U.S. economy around $3.1 trillion annually. In aviation, the stakes are even higher: misfiled or misread maintenance records can ground a fleet, and an incorrect part number can mean a failed repair or a safety risk. High-volume, high-stakes documents demand extraction accuracy of the highest order.
Garbage In, Garbage Out: Why Precision Extraction Matters
Modern AI models – whether it’s an LLM (Large Language Model) answering maintenance questions or an anomaly detection system flagging compliance issues – are only as good as the data fed into them. If an OCR engine misreads “O-ring part 65-45764-10” as “O-ring part 65-45764-1O” (confusing a zero for an ‘O’), an AI system could fail to find critical part history, or worse, output an incorrect recommendation. High-precision data extraction isn’t just a nice-to-have; it’s a prerequisite for any accurate AI outcome in aviation. This is especially true for retrieval-augmented generation (RAG) pipelines and search applications. In a RAG setup, an LLM like GPT-4o is augmented with factual snippets from your document database. If those snippets are extracted incorrectly or with missing context, the LLM will inevitably produce faulty answers, no matter how sophisticated or large the model is. Likewise, search and analytics systems will give false results if the underlying index was fed noisy data. In short, downstream AI performance degrades quickly when upstream extraction accuracy falters – regardless of model size or prowess. Ensuring near-ground-truth accuracy at the data ingestion stage is the only way to trust the insights later produced by your aviation AI solutions.
Beyond Generic Tools: The Case for Aviation-Specific Document AI
Not all document processing is equal. Generic document AI tools (the kind often optimized for invoices or simple forms) struggle with the complexity of aviation documents. Aviation documents often contain dense tables, multi-level assemblies, specialized terminology (part codes, ATA chapters, etc.), and even handwritten annotations. A one-size-fits-all OCR or form parser will miss nuances – for example, it might read an Illustrated Parts Catalog page as a jumble of text, whereas an aviation-trained model knows how to segment out part numbers, nomenclature, effectivity ranges, and assembly hierarchies.
Domain-Specific Precision: Our aviation-focused Document AI was designed from the ground up for this complexity. It doesn’t treat an IPC page like just any table – it understands the part-level structure and relationships. For instance, when extracting a Boeing IPC, the model captures the line-item part breakdown including parent-child assemblies(e.g. recognizing that part 65-45764-10 is a component under parent assembly 69-33484-2, which in turn is under a higher assembly 65-38196-5). This preservation of hierarchy is critical: it means your AI doesn’t just know the parts, but how they fit together in the aircraft. Generic tools simply don’t offer this level of contextual structuring.


Accuracy Leadership: Specialized training yields superior accuracy. Our Document AI achieves over 98% accuracy at the field level, and 99%+ at the character level on aviation documents. In other words, more than 98 out of 100 extracted fields (such as “Part Number”, “Serial Number”, “Install Date”, etc.) are exactly correct – a rate unattainable by most off-the-shelf OCR services on these document types. Character-level accuracy exceeding 99% means even in long part numbers or alphanumeric codes, errors are extremely rare. This level of precision is the result of domain-specific OCR models, NLP validation checks, and continuous fine-tuning on aviation data. It far surpasses what a generic invoice processor would achieve when thrown at, say, a maintenance log or an FAA compliance form. In this niche, our solution is the accuracy leader, purpose-built for aviation’s demands.
Moreover, compliance metadata and form-specific details are handled gracefully. Unlike a generic tool that might skip over a non-standard form field, an aviation Document AI knows to extract fields like “Type Certificate Number” from an Airworthiness Certificate or the “Effectivity” section from a Service Bulletin, because these are crucial in context. By focusing on part-level details, form-level context, and regulatory metadata, the solution ensures no critical data is left behind. This focus on aviation complexity is what sets specialized Document AI apart – it speaks the language of aviation documents, whereas generic models remain tongue-tied.
Aviation Document AI by the Numbers
To illustrate the performance and capabilities of our aviation-grade Document AI, here are some key metrics and features:
- Field-Level Accuracy > 98% – Essential data fields (part IDs, dates, compliance checkboxes, etc.) are correctly captured with over 98% accuracyfile-q7xvjvhip1lffe4hbnkuac, even across varied document layouts. This dramatically reduces the need for human correction.
- Character-Level OCR Accuracy > 99% – Thanks to robust OCR (and use of native text layers when available), character recognition is virtually error-freefile-q7xvjvhip1lffe4hbnkuac. For example, serial numbers or part codes tens of characters long are reproduced exactly, preserving critical identifiers.
- Boeing IPC Support (Assemblies Captured) – Currently supports Boeing IPC documents, parsing out every line item. The extractor understands IPC schema: it pulls fields like Figure number, Item number, Part Number, Nomenclature, Units Per Assembly, and Effectivity ranges. Crucially, it captures parent/child assembly relationships, reconstructing the hierarchy of parts in each assembly. This means your AI can answer queries about how components are nested or identify all sub-parts under a given assembly – capabilities unattainable with generic parsers.
- Scale – 1,000 Pages Concurrently – The system has been field-tested at an ingestion throughput of 1k pages in parallel, by running 5 concurrent batches of 200 pages eachfile-q7xvjvhip1lffe4hbnkuac. In practice, this means an entire library of manuals or a year’s worth of logbooks can be processed in minutes. High throughput ensures that even high-volume backlogs or real-time document streams (like a sudden dump of new maintenance records) can be handled without choking.
- Real-Time Document Splitting & Classification – Large PDF manuals or combined document sets are automatically split into individual documents or sections for targeted processingfile-q7xvjvhip1lffe4hbnkuac. An AI-based document classifier first determines the document type (e.g. distinguishing an Illustrated Parts Catalog from a Maintenance Manual or an Airworthiness certificate) to route it to the correct extraction pipelinefile-q7xvjvhip1lffe4hbnkuac. This classification has near-100% recall, ensuring no document is misidentified or skipped. Splitting and classification happen on the fly, enabling continuous feeds of mixed document types to be processed accurately in real time.
- Structured Output for Easy Integration – The extracted data isn’t just raw text – it’s output as structured records (JSON, XML, etc.) complete with metadata like document type, section headers, and even page references. This document structure capture means you retain context: every data point knows where it came from (page X of manual Y, section Z). Such structure is invaluable when feeding the data into other systems or audits.
In sum, the combination of ultra-high accuracy and domain-tailored features (like assembly hierarchy capture) makes this solution uniquely capable of handling aviation documents at scale. Next, let’s see how these capabilities plug into an AI pipeline.
Technical Pipeline Overview: From Documents to AI-Ready Data
To build an effective AI pipeline for aviation data, we recommend a staged approach. Here’s an overview of the pipeline, from raw document ingestion to delivering vectors for AI models:
- Ingestion (PDFs and Scans): Accept documents from various sources – whether high-resolution scans, PDFs with embedded text, or images. The pipeline can ingest scanned paper records and apply advanced OCR if needed, or directly parse text from digital PDFs (leveraging the text layer for 99.9% accuracy when available. The ingestion stage normalizes file formats and queues documents for processing. It’s designed to handle bulk uploads and streaming inputs, initiating downstream jobs as soon as new files arrive (supporting event-driven processing for real-time systems).
- Classification: Next, an AI-powered classifier identifies each document’s type and purposefile-q7xvjvhip1lffe4hbnkuac. For example, it labels documents as “Airworthiness Certificate”, “IPC – Boeing 737”, “Maintenance Task Card”, “FAA AD Bulletin”, etc. This step is crucial because extraction logic is often template-specific. High classification accuracy (with near 100% recall) ensures that each document is routed to the correct extraction model or rule set. If a document contains multiple sections (e.g., a merged PDF with several forms), this stage also segments those sections by type.
- Automated Splitting: Large manuals or PDFs that contain multiple documents are automatically split into logical unitsfile-q7xvjvhip1lffe4hbnkuac. For instance, a 500-page maintenance manual might be split by chapter or task, or an IPC PDF covering multiple sections will be split by section/figure. Likewise, a stack of scanned logbook pages will be separated into individual page images for parallel processing. Splitting the input serves two purposes: it allows parallel extraction (massively speeding up processing) and ensures that context boundaries are respected (so that each chunk can be treated independently for downstream tasks like embedding). This is done in real-time; as soon as a large file is ingested, the system begins splitting it and feeding pages/sections into the extraction stage concurrently.
- High-Accuracy Extraction: This is the core stage where the Document AI extraction engine kicks in. Using a combination of template-specific OCR models, NLP parsers, and validation checks, the system extracts structured data with aviation-grade accuracy. Key fields are pulled out according to the document type – for an IPC: part numbers, nomenclature, assembly references, etc.; for a maintenance log: dates, actions taken, mechanic notes; for a regulatory form: certificate IDs, expirations, signatures, etc. Contextual integrity is maintained: the output preserves which section or table a field came from, and fields are linked (for example, all line-items under a Figure or all entries under a certain date). The result is a structured dataset representing the document’s information. With accuracy >98% at field-level, very minimal human review is needed, and any confidence drops or anomalies can be flagged for inspection.
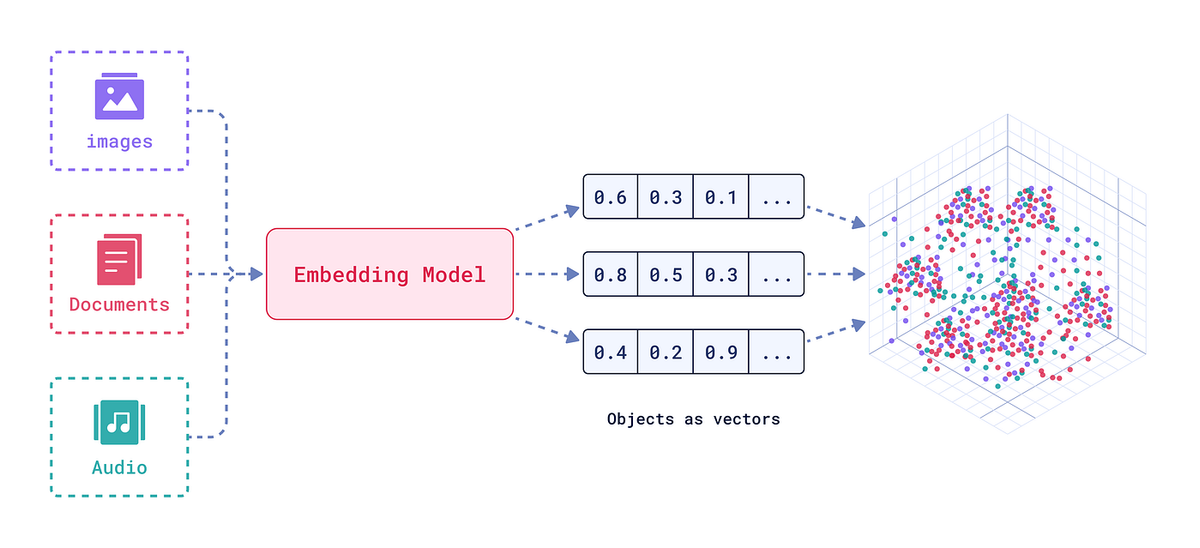
- Embedding & Vectorization: Once textual data is extracted, it can be transformed into vector embeddings for AI consumption. The pipeline integrates with major embedding models – you can plug in your model of choice (e.g. OpenAI’s text embedding APIs, Sentence-BERT, or other transformer-based encoders) to convert each document chunk or data record into a high-dimensional vector. We support custom chunking strategies here: for example, you might embed each paragraph or each section separately to optimize downstream retrieval. The system can automatically chunk large text fields (like long manual paragraphs) into snippet sizes ideal for your LLM context window, or you can define chunking rules (by sentence, by subsection, etc.). This flexibility ensures that the embeddings capture meaningful pieces of information without truncating context. By the end of this step, each document (or document section) is represented by one or more embedding vectors, typically accompanied by metadata (document ID, section title, source reference).
- Vector Database Injection: Finally, the vectors and metadata are injected into a vector database of your choice. The solution works out-of-the-box with popular vector stores like Redis (with RediSearch vectors), Pinecone, or Elastic (Elastic’s vector search capability), among others. This means the extracted knowledge from documents becomes immediately searchable via similarity search or usable in retrieval-augmented generation. For instance, you can now query your document collection with natural language and retrieve the most relevant chunks in vector space, or your AI assistant can fetch relevant maintenance manual sections to answer a question. The pipeline ensures that along with each vector, the original text and document reference are stored, so when a vector match is found, you can trace it back to the source document/page. Real-time updates are supported as well – if new documents come in, their embeddings can be inserted on the fly, keeping the vector DB and your AI’s knowledge base up-to-date.
This pipeline ensures a smooth flow from raw unstructured inputs to AI-ready, structured information. Each stage is optimized for aviation use cases – from understanding domain-specific document formats to scaling out processing across thousands of pages concurrently. The end result is a knowledge-rich vector database that powers search, analytics, or large language models with accurate, context-rich data.
Ensuring Scalable Performance and Reliability
Architecting for aviation-scale document processing means handling both high throughput and high reliability. On the throughput side, as noted, our Document AI can ingest and process documents in parallel – successfully processing 1,000 pages concurrently in recent field testsfile-q7xvjvhip1lffe4hbnkuac. This was achieved with a horizontal scaling approach: multiple extraction workers operating on different batches of pages simultaneously. The system is cloud-native and can autoscale with load, meaning whether you have 100 pages or 100,000 pages to parse, it can allocate resources to meet the demand. For an AI team, this scalability translates to minimal waiting time between data ingestion and insight – critical when you need to, say, onboard a new aircraft’s documentation library into your analytics platform quickly.
Reliability comes from more than just raw accuracy; it’s also about capturing structure and context correctly. For example, document structure capture ensures that when the data is used downstream, you know the context. If a vector search pulls up a snippet about “torque value: 50 Nm”, the system knows which maintenance manual and section that came from, and it can retrieve the entire section or page image on demand. This is invaluable for validation and for end-users to trust the AI output – they can always refer back to the original document snippet that the AI used. Our pipeline’s structured outputs include these contextual markers by design.
Additionally, the solution has been tested on real-world document variations. Aviation documents can be messy – scans with stamps, handwriting, or slightly different layouts between manufacturers. The Document AI uses ensemble OCRapproaches (combining multiple OCR engines and a voting mechanism) when dealing with noisy scans, and it employs validation rules (like checksum checks on part numbers, date format checks, etc.) to catch any extraction anomalies. This means even when pushing throughput limits, the system maintains a high bar for accuracy. In internal benchmarks with Boeing IPCs, the OCR character accuracy was measured at 99.9% on documents with an existing text layer, and only marginally lower on pure scanned images thanks to advanced OCR models. By capturing domain-specific structure (like table of contents of manuals, or sections in logbooks), the system can also split and recover from errors gracefully – e.g., if one page is particularly bad quality, it’s isolated and flagged rather than derailing a whole batch.
For AI engineering teams, these capabilities remove a major headache: you can trust the data coming out of your document pipeline. You’re not left cleaning up OCR errors or writing ad-hoc regexes for each new document type. The focus can instead shift to building powerful AI applications (like predictive maintenance models, knowledge graph construction, or compliance auditing tools) on top of this reliable data layer.
The Impact on Downstream AI: RAG, LLMs, and Search
It’s worth re-emphasizing how this high-precision extraction feeds downstream AI tasks. Consider Retrieval-Augmented Generation (RAG): here, a large language model (LLM) is supplemented with relevant documents or snippets fetched from a knowledge base. If your knowledge base is an aviation document vector DB built from sloppy extraction, the LLM might be given irrelevant or incorrect text – leading it to generate an inaccurate or hallucinated answer. By contrast, feeding the LLM with clean, accurate snippets from our Document AI pipeline means the model can generate responses that are grounded in truth. We have observed that by boosting field-level accuracy above 98%, we significantly improve the precision of retrieval hits (fewer false matches) and thereby the quality of answers in an aviation Q&A setting. In essence, the LLM can focus on its job of understanding and composing answers, rather than internally struggling with garbled input. The result is far more reliable AI assistance for engineers and decision-makers.
The same logic applies to plain semantic search or question-answering systems that don’t involve generation. For example, an airline might build a search portal for maintenance technicians to query past repair records or manuals. If the index behind that search is built on accurately extracted data, the search results are trustworthy – the returned records genuinely contain the query terms or relevant info. If not, the search might miss critical documents (low recall) or surface wrong ones (false positives), eroding user confidence. High-precision extraction ensures that when you search for “fuel pump AD compliance”, you actually get the relevant Airworthiness Directive document and related compliance records, not a bunch of noise.
No matter how advanced your AI models are – even if you employ a state-of-the-art 175-billion-parameter transformer – their outputs can be led astray by bad input data. In the context of aviation, where safety and regulatory compliance are on the line, this isn’t just a minor inconvenience; it’s a serious risk. That’s why we insist on a top-tier extraction layer. It acts as the single source of truth, converting your unstructured documents into a clean, queryable, AI-ready repository of knowledge.
Conclusion: Laying the Foundation for Aviation-Grade AI Success
For AI leads and technical teams in the aviation sector, the message is clear: invest in data accuracy at the start of your AI pipeline. High-volume, complex aviation documents are a formidable source of truth – and extracting their data with near-perfect fidelity is the only way to unlock that truth for your AI systems. Skimping on extraction quality is a false economy; any savings will be negated by poor AI performance later, or worse, a critical insight missed due to a bad data point. By deploying an aviation-specialized Document AI with ~98-99%+ accuracy, you establish a rock-solid foundation for all downstream applications, from predictive maintenance and fleet optimization to compliance auditing and intelligent assistants.
In summary, high-precision Document AI is the linchpin of aviation-grade AI. It turns mountains of unstructured paperwork into reliable, structured data. With that in place, your LLMs, knowledge graphs, and analytics dashboardscan soar – delivering accurate, actionable insights that drive safety and efficiency in operations. Without it, even the most powerful AI will stumble on the shaky input. As the aviation industry embraces digital transformation and AI, those who build upon a base of clean, precise data extraction will have a decisive advantage. It’s like having an ultra-reliable compass before a flight – you wouldn’t take off without one, and likewise, no AI journey should start without trustworthy data. By embedding a high-accuracy Document AI solution into your pipeline – complete with domain-tuned models, robust OCR, and seamless integration to vector databases – you ensure your aviation AI initiatives are cleared for takeoff with confidence and precision.
Aviation Maintenance Trends That May Gain Momentum in Uncertain Circumstances
Aircraft are staying in service longer, supply chains are a powder keg, and the tech is evolving overnight. Discover the maintenance trends gaining momentum and what they mean for operators trying to stay airborne and profitable.

April 14, 2026
ePlane AI's Unlock $500M in Quoting Opportunity with Automation! | Free Webinar
See how sales operators are automating RFQ extraction, eliminating manual data entry errors, and scaling their quoting operations with precision and consistency to unlock revenue.
April 10, 2026
Mission Control: High‑Performance Intelligence Infrastructure for Mission‑Critical Decision Velocity
Every leader I speak with across aerospace, manufacturing, or construction says the same thing:
Our systems are getting smarter, but our decisions aren’t getting faster or safer at the pace operations demand.
In high‑integrity environments, the gap between data and decisions is where risk accumulates. As operations grow more complex, distributed, and time‑sensitive, organizations need intelligence systems that are not just fast but verifiable, deterministic, and secure by design.
This is the engineering philosophy behind Mission Control, our high‑performance intelligence infrastructure built for real‑time, audit‑ready, cryptographically secure decision velocity.

February 2, 2026
ePlane AI at MRO Americas 2026 | The Future of Maintenance, Supply Chain, and Operational Intelligence
MRO Americas is where the aviation maintenance ecosystem aligns on what’s next — and in 2026, the conversation is shifting decisively toward operational intelligence, automation, and data‑driven decisioning. This year, ePlane AI is joining the industry in Orlando to demonstrate how deterministic, agentic intelligence is reshaping maintenance, supply chain, and technical operations.

