Orchestrer les insights d’IA pour les transformer en actions
Documents aéronautiques : IA. Une précision performante.
novembre 06, 2025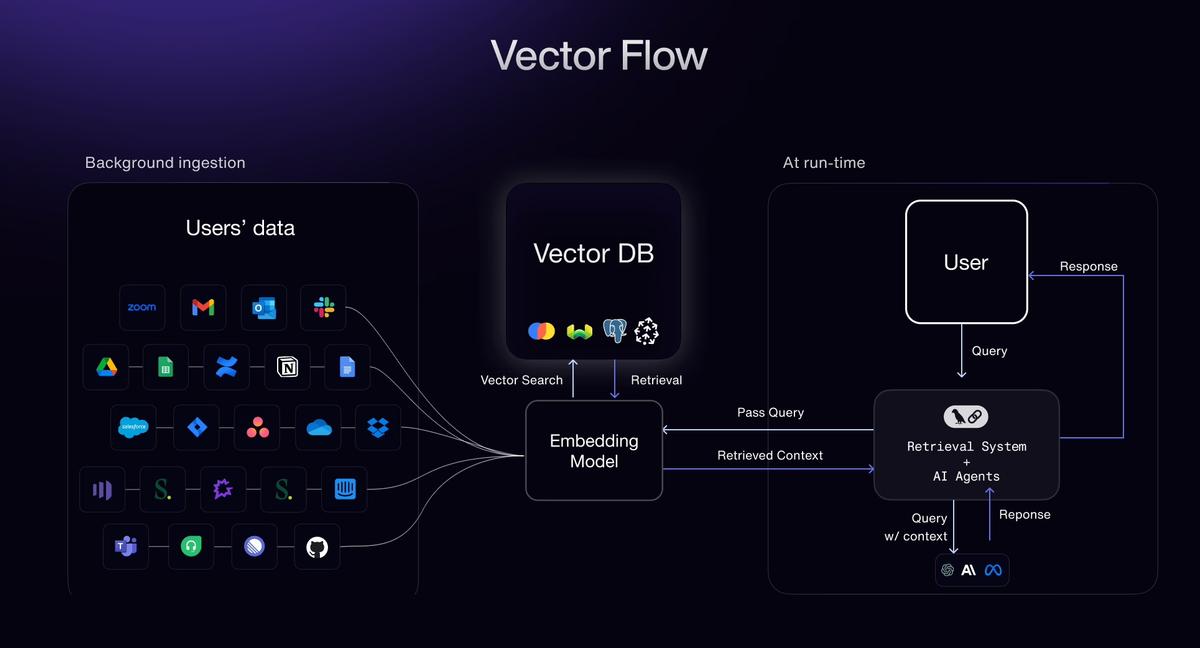
Introduction : Le déluge de documents dans l'aviation et l'impératif de précision
L'industrie aéronautique est submergée de documents essentiels : certificats de navigabilité, catalogues de pièces illustrés (IPC), manuels de maintenance, bulletins de service/consignes de navigabilité de la FAA, carnets de vol, etc. Ces documents non structurés et volumineux sont essentiels aux opérations aériennes et à la conformité. Par exemple, un seul avion commercial américain peut produire jusqu'à7 500 pages de nouveaux documents par anpour répondre aux exigences du DOT et de la FAA. Il est impératif de garantir que les systèmes d'IA puissent interpréter et exploiter de manière fiable cette montagne de données.aviation-grade AI, un principe ressort :la qualité des résultats de l'IA n'est aussi bonne que la précision de l'extraction des données sous-jacentesEn d'autres termes, si l'extraction des données de votre document est défectueuse, même le modèle d'IA le plus avancé propagera ces erreurs – un scénario classique de « garbage in, garbage out ». Les responsables de l'IA et les équipes techniques doivent donc prioriserextraction de données de documents de haute précisioncomme fondement de tout pipeline d’IA aéronautique.
Données non structurées dans l'aviation : défis et nécessité
Les entreprises aéronautiques dépendent de documents non structurés pour tout, de la conformité réglementaire aux opérations quotidiennes. Prenons quelques exemples :
- Documents réglementaires :Certificats de navigabilité, FAABulletins de service (SB) et Consignes de navigabilité (CN)Les bulletins, les certifications de sécurité et les rapports d'incident sont obligatoires et font l'objet d'audits réguliers. Toute information erronée peut entraîner des violations de conformité ou l'immobilisation d'un avion.
- Manuels techniques : Manuels d'entretien et IPCcontiennent des numéros de pièces complexes, des schémas d'assemblage et des procédures sur lesquels les ingénieurs et les mécaniciens s'appuient. Ces documents s'étendent souvent sur des milliers de pages et se présentent sous des formats variés (PDF numérisés, impressions anciennes), ce qui complique leur analyse automatisée.
- Journaux opérationnels :Les journaux de bord des pilotes, les journaux de maintenance et les ordres de travail enregistrent les données opérationnelles en cours. Ils sont généralement de forme libre et manuscrits ou dactylographiés, ce qui complexifie encore l'extraction.
- Documents d'approvisionnement et d'inventaire :Les catalogues et listes de pièces illustrés, les demandes de devis, les bons de commande et les dossiers de garantie sont utilisés pour l'approvisionnement en pièces et la gestion des stocks. Des erreurs d'extraction des numéros de pièces ou des quantités peuvent entraîner des erreurs d'inventaire coûteuses.
Faire face à celadéluge de documentsest complexe car les données sont non structurées, enfermées dans des descriptions, des tableaux et des formulaires en langage naturel. On estime que80 % des données d'entreprise ne sont pas structurées, dissimulées dans des PDF, des e-mails et des formulaires numérisés. Les entreprises du secteur aéronautique connaissent bien ce problème : selon IDC, les employés peuvent consacrer environ 30 % de leur temps à rechercher et à consolider des informations dans différents documents. Les conséquences d'une mauvaise qualité des données sont graves : IBM estime que les données erronées coûtent environ 1 000 $ à l'économie américaine.3,1 billions de dollars par anDans l'aviation, les enjeux sont encore plus importants : des dossiers de maintenance mal classés ou mal lus peuvent immobiliser une flotte, et une référence de pièce incorrecte peut entraîner une réparation ratée ou un risque pour la sécurité. Les documents volumineux et à enjeux élevés exigent une extraction d'une précision extrême.
Des déchets à l'entrée, des déchets à la sortie : l'importance de l'extraction de précision
Modèles d’IA modernes – qu’il s’agisse d’unLLM (Large Language Model)Les solutions d'extraction de données, qu'elles soient de type « réponse aux questions de maintenance » ou « système de détection d'anomalies signalant des problèmes de conformité », ne sont efficaces que si les données qui les alimentent sont fiables. Si un moteur OCR interprète à tort « joint torique pièce 65-45764-10 » comme « joint torique pièce 65-45764-1O » (confondant un zéro avec un « O »), un système d'IA pourrait ne pas trouver l'historique de la pièce critique, ou pire, émettre une recommandation erronée. L'extraction de données de haute précision n'est pas seulement un atout ; c'est un atout.condition préalable à tout résultat précis de l'IAdans l'aviation. Cela est particulièrement vrai pourgénération augmentée par récupération (RAG)Pipelines et applications de recherche. Dans une configuration RAG, un LLM comme GPT-4o est enrichi d'extraits factuels de votre base de données documentaires. Si ces extraits sont extraits de manière incorrecte ou avec un contexte manquant, le LLM produira inévitablement des réponses erronées, quelle que soit la sophistication ou la taille du modèle. De même, les systèmes de recherche et d'analyse donneront des résultats erronés si l'index sous-jacent a été alimenté par des données bruitées. En résumé,les performances de l'IA en aval se dégradent rapidement lorsque la précision de l'extraction en amont faiblit– quelle que soit la taille ou la puissance du modèle. Garantir une précision quasi-réelle dès l'ingestion des données est le seul moyen de garantir la fiabilité des informations produites ultérieurement par vos solutions d'IA aéronautique.
Au-delà des outils génériques : le cas de l'IA documentaire spécifique à l'aviation
Le traitement des documents n'est pas toujours le même. Les outils d'IA génériques (souvent optimisés pour les factures ou les formulaires simples) peinent à gérercomplexité des documents d'aviationLes documents aéronautiques contiennent souvent des tableaux denses, des assemblages à plusieurs niveaux, une terminologie spécialisée (codes de pièces, chapitres ATA, etc.) et même des annotations manuscrites. Un OCR ou un analyseur de formulaires universel passera à côté des nuances ; par exemple, il pourrait lire une page de catalogue de pièces illustrées comme un fouillis de texte, alors qu'un modèle formé à l'aviation sait segmenter les numéros de pièces, la nomenclature, les plages d'efficacité et les hiérarchies d'assemblages.
Précision spécifique au domaine :Notre IA documentaire, axée sur l'aviation, a été conçue dès le départ pour répondre à cette complexité. Elle ne traite pas une page IPC comme n'importe quel tableau : elle comprend lesstructure et relations au niveau des parties. Par exemple, lors de l'extraction d'un IPC Boeing, le modèle capture lerépartition des éléments de ligne, y compris les assemblages parent-enfant(Par exemple, reconnaître que la pièce 65-45764-10 est un composant de l'assemblage parent 69-33484-2, lui-même rattaché à l'assemblage supérieur 65-38196-5). Cette préservation de la hiérarchie est essentielle : elle signifie que votre IA ne connaît pas seulement les pièces, mais aussi leur assemblage dans l'avion. Les outils génériques n'offrent tout simplement pas ce niveau de structuration contextuelle.


Leadership en matière de précision :Une formation spécialisée permet une précision supérieure. Notre IA documentaire atteintplus de 98 % de précision au niveau du terrain, et 99%+ au niveau du personnagesur les documents aéronautiques. Autrement dit, plus de 98 champs extraits sur 100 (tels que « Référence », « Numéro de série », « Date d'installation », etc.) sont parfaitement corrects – un taux inaccessible à la plupart des services OCR standard pour ces types de documents. Une précision au niveau des caractères supérieure à 99 % signifie que, même pour les références longues ou les codes alphanumériques, les erreurs sont extrêmement rares. Ce niveau de précision est le fruit de modèles OCR spécifiques au domaine, de contrôles de validation NLP et d'un ajustement continu des données aéronautiques. Il dépasse de loin ce qu'un système de traitement de factures générique atteindrait lorsqu'il traiterait, par exemple, un carnet de maintenance ou un formulaire de conformité FAA.Dans ce créneau, notre solution est le leader de la précision, spécialement conçu pour répondre aux exigences de l’aviation.
De plus, métadonnées de conformitéLes détails spécifiques au formulaire sont traités avec élégance. Contrairement à un outil générique qui pourrait ignorer un champ de formulaire non standard, une IA de documents aéronautiques sait extraire des champs tels que le « Numéro de certificat de type » d'un certificat de navigabilité ou la section « Efficacité » d'un bulletin de service, car ils sont essentiels dans le contexte. En se concentrant surdétails au niveau des parties, contexte au niveau du formulaire et métadonnées réglementairesLa solution garantit qu'aucune donnée critique n'est oubliée. Cette attention portée à la complexité de l'aviation est ce qui distingue l'IA documentaire spécialisée : elle parle le langage des documents aéronautiques, tandis que les modèles génériques restent muets.
L'IA des documents d'aviation en chiffres
Pour illustrer les performances et les capacités de notre IA documentaire de qualité aéronautique, voici quelques indicateurs et fonctionnalités clés :
- Précision au niveau du terrain > 98 %– Les champs de données essentiels (identifiants de pièces, dates, cases à cocher de conformité, etc.) sont correctement saisis avec une précision de plus de 98 % (file-q7xvjvhip1lffe4hbnkuac), même avec des mises en page de documents variées. Cela réduit considérablement le besoin de corrections humaines.
- Précision OCR au niveau des caractères > 99 %– Grâce à un OCR performant (et à l'utilisation de calques de texte natifs lorsqu'ils sont disponibles), la reconnaissance de caractères est quasiment exempte d'erreurs. Par exemple, les numéros de série ou les codes de pièces de plusieurs dizaines de caractères sont reproduits avec exactitude, préservant ainsi les identifiants critiques.
- Support IPC de Boeing (assemblages capturés)– Prend actuellement en chargeDocuments IPC de Boeing, analysant chaque ligne d'article. L'extracteur comprend le schéma IPC : il extrait des champs tels que le numéro de figure, le numéro d'article, le numéro de pièce, la nomenclature, les unités par assemblage et les plages d'effectivité. Il est essentiel qu'ilcapture les relations d'assemblage parent/enfant, reconstituant la hiérarchie des pièces de chaque assemblage. Votre IA peut ainsi répondre à des questions sur l'imbrication des composants ou identifier toutes les sous-pièces d'un assemblage donné, des capacités inaccessibles aux analyseurs génériques.
- Échelle – 1 000 pages simultanément– Le système a été testé sur le terrain dans undébit d'ingestion de 1 000 pages en parallèle, en exécutant 5 lots simultanés de 200 pages chacun. En pratique, cela signifie qu'une bibliothèque entière de manuels ou une année de journaux de bord peuvent être traités en quelques minutes. Un débit élevé garantit que mêmearriérés à volume élevéou les flux de documents en temps réel (comme un vidage soudain de nouveaux enregistrements de maintenance) peuvent être traités sans étouffement.
- Division et classification de documents en temps réel– Les manuels PDF volumineux ou les ensembles de documents combinés sont automatiquementdivisé en documents ou sections individuelspour le traitement cibléfile-q7xvjvhip1lffe4hbnkuac. Un système basé sur l'IAclassificateur de documentsLe type de document est d'abord déterminé (par exemple, en distinguant un catalogue de pièces illustré d'un manuel de maintenance ou d'un certificat de navigabilité) pour l'acheminer vers le bon pipeline d'extraction (file-q7xvjvhip1lffe4hbnkuac). Cette classification offre un taux de rappel proche de 100 %, garantissant qu'aucun document n'est mal identifié ou ignoré. Le fractionnement et la classification s'effectuent à la volée, permettant un traitement précis et en temps réel des flux continus de documents de types variés.
- Sortie structurée pour une intégration facile– Les données extraites ne sont pas simplement du texte brut : elles sont générées sous forme d'enregistrements structurés (JSON, XML, etc.) avec des métadonnées telles que le type de document, les en-têtes de section et même les références de page.capture de la structure du documentCela signifie que vous conservez le contexte : chaque donnée sait d'où elle provient (page X du manuel Y, section Z). Une telle structure est précieuse pour alimenter d'autres systèmes ou audits.
En résumé, la combinaison d'une précision extrême et de fonctionnalités adaptées au domaine (comme la capture de la hiérarchie d'assemblage) confère à cette solution une capacité unique à gérer les documents aéronautiques à grande échelle. Voyons maintenant comment ces fonctionnalités s'intègrent à un pipeline d'IA.
Présentation du pipeline technique : des documents aux données prêtes pour l'IA
Pour construire une stratégie efficacePipeline d'IA pour les données aéronautiquesNous recommandons une approche par étapes. Voici un aperçu du processus, de l'ingestion des documents bruts à la livraison des vecteurs pour les modèles d'IA :
- Ingestion (PDF et numérisations) :Acceptez des documents provenant de sources diverses : numérisations haute résolution, PDF avec texte intégré ou images. Le pipeline peut ingérerdocuments papier numériséset appliquez une reconnaissance optique de caractères avancée si nécessaire, ou analysez directement le texte à partir de PDF numériques (en exploitant la couche de texte pour une précision de 99,9 % lorsqu'elle est disponible). L'étape d'ingestion normalise les formats de fichiers et met les documents en file d'attente pour traitement. Elle est conçue pour gérer les téléchargements en masse et les entrées en continu, en lançant les tâches en aval dès l'arrivée de nouveaux fichiers (prenant en charge le traitement piloté par les événements pour les systèmes en temps réel).
- Classification:Ensuite, un classificateur basé sur l'IA identifie le type et l'objectif de chaque document (file-q7xvjvhip1lffe4hbnkuac). Par exemple, il les qualifie de « Certificat de navigabilité », « IPC – Boeing 737 », « Carte de tâches de maintenance », « Bulletin de la FAA AD », etc. Cette étape est cruciale, car la logique d'extraction est souvent spécifique à un modèle. Une précision de classification élevée (avec un taux de rappel proche de 100 %) garantit que chaque document est dirigé vers le modèle d'extraction ou l'ensemble de règles approprié. Si un document contient plusieurs sections (par exemple, un PDF fusionné avec plusieurs formulaires), cette étape segmente également ces sections par type.
- Fractionnement automatisé :Les manuels volumineux ou les PDF contenant plusieurs documents sont automatiquementdivisé en unités logiquesfichier-q7xvjvhip1lffe4hbnkuac. Par exemple, un manuel de maintenance de 500 pages peut être divisé par chapitre ou par tâche, ou un PDF IPC couvrant plusieurs sections sera divisé par section/figure. De même, une pile de pages de journal de bord numérisées sera divisée en images de page individuelles pour un traitement parallèle. Le fractionnement des données d'entrée a deux objectifs : il permetextraction parallèle(accélérant considérablement le traitement) et garantissant le respect des limites de contexte (afin que chaque fragment puisse être traité indépendamment pour les tâches en aval, comme l'intégration). Cela se fait en temps réel ; dès qu'un fichier volumineux est ingéré, le système commence à le fractionner et à alimenter simultanément l'étape d'extraction en pages/sections.
- Extraction de haute précision :Il s'agit de l'étape principale où le moteur d'extraction Document AI entre en jeu. En utilisant une combinaison de modèles OCR spécifiques aux modèles, d'analyseurs NLP et de contrôles de validation, le systèmeextrait des données structurées avec une précision de niveau aéronautiqueLes champs clés sont extraits en fonction du type de document – pour un IPC : numéros de pièces, nomenclature, références d'assemblage, etc. ; pour un journal de maintenance : dates, actions entreprises, notes du mécanicien ; pour un formulaire réglementaire : identifiants de certificat, expirations, signatures, etc.Intégrité contextuelleest conservé : la sortie conserve la section ou le tableau d'origine d'un champ, et les champs sont liés (par exemple, tous les éléments d'une figure ou toutes les entrées d'une date donnée). Le résultat est un ensemble de données structuré représentant les informations du document. Avec une précision supérieure à 98 % au niveau du champ, une révision humaine minimale est nécessaire, et toute baisse de confiance ou anomalie peut être signalée pour inspection.
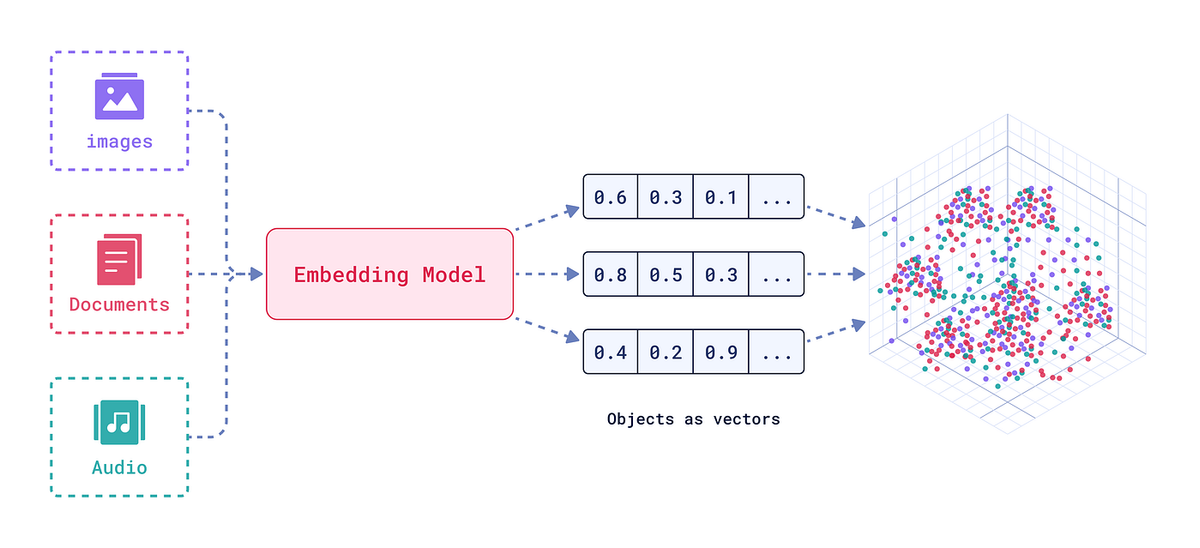
- Incorporation et vectorisation :Une fois les données textuelles extraites, elles peuvent être transformées en représentations vectorielles intégrées pour l'IA. Le pipeline s'intègre àprincipaux modèles d'intégration– vous pouvez intégrer le modèle de votre choix (par exemple, les API d'intégration de texte d'OpenAI, Sentence-BERT ou d'autres encodeurs basés sur des transformateurs) pour convertir chaque fragment de document ou enregistrement de données en un vecteur de grande dimension. Nous prenons en charge les personnalisations.stratégies de découpageIci : par exemple, vous pouvez intégrer chaque paragraphe ou chaque section séparément pour optimiser la recherche en aval. Le système peut automatiquement segmenter les champs de texte volumineux (comme les longs paragraphes manuels) en extraits de taille adaptée à votre fenêtre contextuelle LLM, ou vous pouvez définir des règles de segmentation (par phrase, par sous-section, etc.). Cette flexibilité garantit que les intégrations capturent des informations pertinentes sans tronquer le contexte. À la fin de cette étape, chaque document (ou section de document) est représenté par un ou plusieurs vecteurs d'intégration, généralement accompagnés de métadonnées (identifiant du document, titre de la section, référence de la source).
- Injection de base de données vectorielle :Enfin, les vecteurs et les métadonnées sontinjecté dans une base de données vectoriellede votre choix. La solution est prête à l'emploi avec les magasins vectoriels populaires tels queRedis(avec les vecteurs RediSearch),Pomme de pin, ou Élastique(La fonctionnalité de recherche vectorielle d'Elastic), entre autres. Cela signifie que les connaissances extraites des documents deviennent immédiatement consultables via la recherche par similarité ou utilisables dans la génération assistée par récupération. Par exemple, vous pouvez désormais interroger votre collection de documents en langage naturel et récupérer les fragments les plus pertinents dans l'espace vectoriel, ou votre assistant IA peut extraire les sections pertinentes du manuel de maintenance pour répondre à une question. Le pipeline garantit que, avec chaque vecteur, le texte original et la référence du document sont stockés. Ainsi, lorsqu'une correspondance vectorielle est trouvée, vous pouvez la retracer jusqu'au document/à la page source. Les mises à jour en temps réel sont également prises en charge : si de nouveaux documents arrivent, leurs intégrations peuvent être insérées à la volée, ce qui maintient à jour la base de données vectorielle et la base de connaissances de votre IA.
Ce pipeline assure un flux fluide, des données brutes non structurées aux informations structurées, prêtes à l'emploi pour l'IA. Chaque étape est optimisée pour les cas d'usage aéronautiques, de la compréhension des formats de documents spécifiques au domaine à l'extension du traitement sur des milliers de pages simultanément. Le résultat final est unbase de données vectorielles riche en connaissancesqui alimente la recherche, l'analyse ou les grands modèles linguistiques avecdonnées précises et riches en contexte.
Assurer des performances et une fiabilité évolutives
Concevoir une architecture pour le traitement de documents à l'échelle de l'aviation signifie gérer à la foishaut débit et haute fiabilité. Du côté du débit, comme indiqué, notre IA documentaire peut ingérer et traiter des documents en parallèle, avec succès.traitement de 1 000 pages simultanémentLors de récents tests sur le terrain, file-q7xvjvhip1lffe4hbnkuac a permis d'atteindre cet objectif grâce à une approche de mise à l'échelle horizontale : plusieurs opérateurs d'extraction travaillent simultanément sur différents lots de pages. Le système est cloud-native et s'adapte automatiquement à la charge. Ainsi, que vous ayez 100 ou 100 000 pages à analyser, il peut allouer des ressources pour répondre à la demande. Pour une équipe d'IA, cette évolutivité se traduit par un temps d'attente minimal entre l'ingestion des données et leur exploitation, un atout essentiel lorsqu'il s'agit, par exemple, d'intégrer rapidement la bibliothèque de documentation d'un nouvel avion à votre plateforme d'analyse.
La fiabilité ne se résume pas à une simple précision brute ; elle repose également surcapturer correctement la structure et le contexte. Par exemple, capture de la structure du documentgarantit que, lors de l'utilisation des données en aval, vous connaissez le contexte. Si une recherche vectorielle renvoie un extrait concernant la « valeur de couple : 50 Nm », le système sait de quel manuel de maintenance et de quelle section il provient, et peut récupérer l'intégralité de la section ou de l'image de la page à la demande. C'est un atout précieux pour la validation et pour la confiance des utilisateurs finaux dans les résultats de l'IA : ils peuvent toujours se référer à l'extrait de document original utilisé par l'IA. Les résultats structurés de notre pipeline incluent ces marqueurs contextuels par conception.
De plus, la solution a été testée sur des documents réels. Les documents d'aviation peuvent être complexes : numérisations avec tampons, écriture manuscrite ou présentations légèrement différentes selon les fabricants. L'IA de Document utiliseensemble OCRIl utilise des approches OCR (combinant plusieurs moteurs OCR et un mécanisme de vote) pour traiter les numérisations bruyantes, et utilise des règles de validation (comme la vérification des sommes de contrôle des numéros de pièces, le contrôle du format de date, etc.) pour détecter toute anomalie d'extraction. Ainsi, même en repoussant les limites de débit, le système maintient un niveau de précision élevé. Lors de tests internes avec des IPC Boeing, la précision des caractères OCR a été mesurée à99,9%sur les documents comportant une couche de texte, et légèrement inférieur sur les images numérisées pures grâce à des modèles OCR avancés. En capturant la structure spécifique à un domaine (comme la table des matières des manuels ou les sections des journaux de bord), le système peut également fractionner et corriger les erreurs avec élégance. Par exemple, si une page est particulièrement de mauvaise qualité, elle est isolée et signalée plutôt que de faire dérailler tout un lot.
Pour les équipes d'ingénierie IA, ces fonctionnalités simplifient la tâche : elles peuvent faire confiance aux données issues de leur pipeline documentaire. Elles évitent ainsi de devoir corriger les erreurs d'OCR ou d'écrire des expressions régulières ad hoc pour chaque nouveau type de document. Elles peuvent désormais se concentrer sur la création d'applications IA performantes (comme des modèles de maintenance prédictive, la construction de graphes de connaissances ou des outils d'audit de conformité) s'appuyant sur cette couche de données fiable.
L'impact sur l'IA en aval : RAG, LLM et recherche
Il convient de souligner à nouveau comment cette extraction de haute précision alimente les tâches d'IA en aval.Génération augmentée par récupération (RAG): Ici, un modèle de langage étendu (MLE) est complété par des documents ou des extraits pertinents extraits d'une base de connaissances. Si votre base de connaissances est une base de données vectorielle de documents aéronautiques construite à partir d'une extraction bâclée, le LLE pourrait recevoir du texte non pertinent ou incorrect, ce qui entraînerait une réponse inexacte ou hallucinante. En revanche, alimenter le LLE avecextraits propres et précisGrâce à notre pipeline d'IA documentaire, le modèle peut générer des réponses fiables. Nous avons observé qu'en augmentant la précision au niveau du champ au-delà de 98 %, nous améliorons significativement la précision des résultats de recherche (moins de fausses correspondances) et, par conséquent, la qualité des réponses dans un contexte de questions-réponses sur l'aviation. En résumé, le LLM peut se concentrer sur sa tâche de compréhension et de rédaction des réponses, plutôt que de se débattre en interne avec des données incohérentes. Il en résulte une assistance IA bien plus fiable pour les ingénieurs et les décideurs.
La même logique s'applique aux systèmes de recherche sémantique simple ou de questions-réponses qui n'impliquent pas de génération. Par exemple, une compagnie aérienne pourrait créer unportail de recherchePour les techniciens de maintenance, la recherche d'anciens dossiers ou manuels de réparation est possible. Si l'index de recherche repose sur des données extraites avec précision, les résultats sont fiables : les enregistrements renvoyés contiennent réellement les termes de la requête ou les informations pertinentes. Dans le cas contraire, la recherche risque de passer à côté de documents critiques (faible rappel) ou de révéler des documents erronés (faux positifs), ce qui érode la confiance des utilisateurs. Une extraction de haute précision garantit que, lorsque vous recherchez « conformité aux consignes de navigabilité des pompes à carburant », vous obtenez réellement le document de consigne de navigabilité pertinent et les enregistrements de conformité associés, et non un amas de données inutiles.
Peu importe le niveau d’avancement de vos modèles d’IA – même si vous utilisez un transformateur de pointe de 175 milliards de paramètres –leurs résultats peuvent être égarés par de mauvaises données d'entréeDans le contexte de l'aviation, où la sécurité et la conformité réglementaire sont en jeu, il ne s'agit pas d'un simple inconvénient mineur ; c'est un risque sérieux. C'est pourquoi nous insistons sur une couche d'extraction de premier ordre. Elle agit commesource unique de vérité, en convertissant vos documents non structurés en un référentiel de connaissances propre, interrogeable et prêt pour l'IA.
Conclusion : Poser les bases du succès de l’IA de niveau aéronautique
Pour les responsables de l’IA et les équipes techniques du secteur aéronautique, le message est clair :Investissez dans la précision des données dès le début de votre pipeline d'IALes documents aéronautiques volumineux et complexes constituent une source précieuse de données fiables, et l'extraction de leurs données avec une fidélité quasi parfaite est le seul moyen de les exploiter pour vos systèmes d'IA. Lésiner sur la qualité de l'extraction est une fausse économie ; toute économie sera annulée ultérieurement par une mauvaise performance de l'IA, ou pire, par une information cruciale manquée en raison d'un point de données erroné. En déployant une IA documentaire spécialisée dans l'aviation, avec une précision d'environ 98 à 99 % et plus, vous établissez une base solide pour toutes les applications en aval, de la maintenance prédictive et de l'optimisation de la flotte à l'audit de conformité et aux assistants intelligents.
En résumé, L'IA documentaire de haute précision est la clé de voûte de l'IA de niveau aéronautique. Il transforme des montagnes de documents non structurés en données fiables et structurées. Grâce à cela, votreLLM, graphiques de connaissances et tableaux de bord analytiquespeut décoller, fournissant des informations précises et exploitables qui améliorent la sécurité et l'efficacité des opérations. Sans elle, même l'IA la plus puissante trébucherait sur des données incertaines. Alors que l'industrie aéronautique adopte la transformation numérique et l'IA, ceux qui s'appuient sur une extraction de données propre et précise bénéficieront d'un avantage décisif. C'est comme avoir une boussole ultra-fiable avant un vol : impossible de décoller sans elle, et de même, aucun projet d'IA ne devrait débuter sans données fiables. En intégrant une solution d'IA documentaire haute précision à votre pipeline, dotée de modèles optimisés par domaine, d'une reconnaissance optique de caractères robuste et d'une intégration transparente aux bases de données vectorielles, vous garantissez que vos initiatives d'IA aéronautique sont approuvées avec confiance et précision.
Tendances en matière de maintenance aéronautique susceptibles de prendre de l'ampleur dans des circonstances incertaines
Les avions restent en service plus longtemps, les chaînes d'approvisionnement sont une véritable poudrière et la technologie évolue du jour au lendemain. Découvrez les tendances de maintenance qui gagnent du terrain et leurs implications pour les exploitants qui cherchent à maintenir leur rentabilité.

April 10, 2026
Mission Control : infrastructure d’intelligence haute performance pour une vitesse de décision critique
Tous les dirigeants avec qui je parle, qu’ils soient dans l’aéronautique, la fabrication ou la construction, me disent la même chose :
Nos systèmes deviennent plus intelligents, mais nos décisions ne deviennent ni plus rapides ni plus sûres au rythme qu’exigent les opérations.
Dans les environnements à haute intégrité, l’écart entre les données et les décisions est l’endroit où le risque s’accumule. À mesure que les opérations deviennent plus complexes, distribuées et sensibles au facteur temps, les organisations ont besoin de systèmes d’intelligence qui ne soient pas seulement rapides mais aussi vérifiables, déterministes et sécurisés dès la conception.
Voici la philosophie d’ingénierie qui sous‑tend Mission Control, notre infrastructure d’intelligence haute performance, conçue pour une prise de décision en temps réel, vérifiable et sécurisée de manière cryptographique.

October 2, 2025
Choisir les bonnes pièces d'avion grâce à l'analyse de la tolérance aux dommages
L'avenir de la sécurité aérienne repose sur les pièces. Des pièces authentiques et traçables offrent aux flottes une tolérance aux dommages et des performances optimales, pour une sécurité et une efficacité d'approvisionnement maximales.

September 30, 2025
Comment pénétrer de nouveaux marchés aéronautiques : le guide complet pour les fournisseurs de pièces détachées
Vous souhaitez conquérir de nouveaux marchés aéronautiques ? Découvrez comment les fournisseurs peuvent analyser la demande, gérer les pièces détachées PMA et renforcer la confiance des compagnies aériennes. Un guide complet pour une croissance mondiale.

