KI-Erkenntnisse in konkrete Maßnahmen überführen
Vector DB. Entschlüsseln Sie die unstrukturierten Erkenntnisse der Luftfahrt.
Juli 15, 2025
Vektordatenbanken indizieren hochdimensionale Einbettungsvektoren, um die semantische Suche in unstrukturierten Daten zu ermöglichen. Im Gegensatz zu herkömmlichen relationalen Speichern oder Dokumentspeichern, die exakte Übereinstimmungen mit Schlüsselwörtern verwenden, verwalten Vektordatenbanken dichte numerische Vektoren (oft 768–3072 Dimensionen), die die Semantik von Text oder Bildern darstellen. Zum Zeitpunkt der Abfrage findet die Datenbank die nächsten Nachbarn zu einem Abfragevektor, indem sie Suchalgorithmen für ungefähre nächste Nachbarn (ANN) verwendet. Ein graphenbasierter Index wie Hierarchical Navigable Small Worlds (HNSW) erstellt beispielsweise geschichtete Näherungsgraphen: eine kleine obere Schicht für die grobe Suche und größere untere Schichten zur Verfeinerung (siehe Abbildung unten). Die Suche „springt“ diese Schichten hinunter – und lokalisiert schnell einen Cluster, bevor sie die lokalen Nachbarn erschöpfend durchsucht. Dabei wird der Trefferquotient (Finden der wahren nächsten Nachbarn) gegen die Latenz abgewogen: Durch Erhöhen des HNSW-Suchparameters (efSearch) wird der Trefferquotient auf Kosten einer längeren Abfragezeit erhöht.
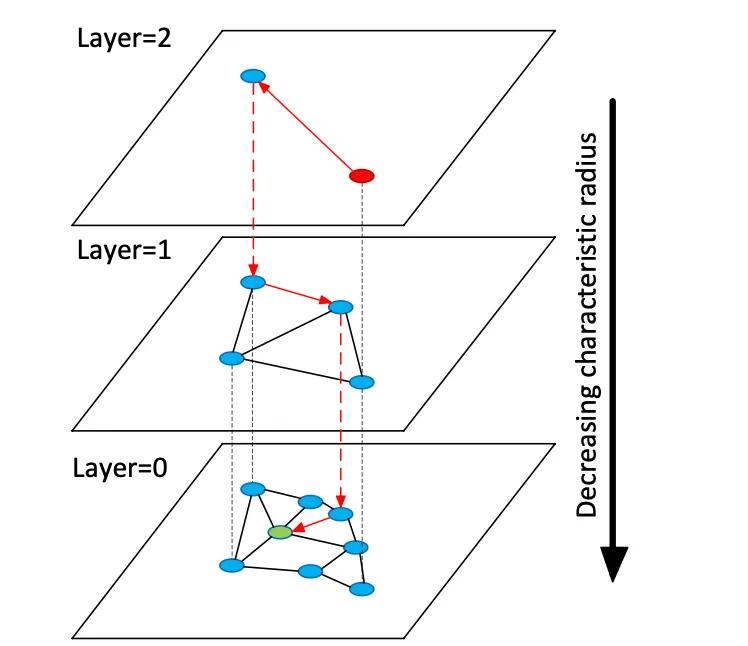
Abbildung: HNSW ANN-Suchdiagramm – Vektoren sind in Schichten organisiert, um Abfragen zum nächsten Nachbarn zu beschleunigen (angepasst von Devmys Erklärung zu Redis Vector Sets).
Anders als die exakte Suche in relationalen Tabellen kann die Vektorsuche Bedeutung erfassen: Abfragen finden semantisch ähnliche Elemente, nicht nur exakte Schlüsselwortübereinstimmungen. Bei Luftfahrtdaten (z. B. Handbüchern oder Reparaturprotokollen) bedeutet dies, dass Ingenieure relevante Inhalte abrufen können, auch wenn der Wortlaut unterschiedlich ist. Vektordistanzen (Kosinus, Skalarprodukt oder euklidischer Wert) quantifizieren die Ähnlichkeit. Bei normalisierten Einbettungen ergeben Kosinus-Ähnlichkeit und Skalarprodukt gleichwertige Rangfolgen. In der Praxis normalisiert man häufig Vektoren und verwendet die Kosinus-Ähnlichkeit als Relevanzmaß. Die wichtigsten Kompromisse bestehen zwischen Trefferquote und Latenz: Höhere Indizes und umfangreichere Suchparameter verbessern die Trefferquote, erhöhen aber die Latenz. Vektordatenbanken bieten anpassbare Indizes (HNSW, IVF, Flat Scan), um Geschwindigkeit und Genauigkeit ins Gleichgewicht zu bringen.
Einbettungsmodelle
Moderne Einbettungsmodelle wandeln Text (oder andere Daten) in Vektoren um. Zu den führenden Modellen zählen „text-embedding-3-large“ von OpenAI, „embedding-multilingual-v3“ von Cohere, die Gemini/BGE-Modelle von Google, die E5- und GTE-Familien von Meta und viele HuggingFace-Modelle (z. B. Sentence-BERT-Varianten). Diese Modelle unterscheiden sich in Dimensionalität, Datenabdeckung und Inferenzkosten. Beispielsweise erzeugt „text-embedding-3-large“ von OpenAI 3072-dimensionale Vektoren, die deutlich größer sind als die früheren Modelle Ada-002 (1536D). Die v3-Modelle von Cohere geben typischerweise 1024D (Englisch oder mehrsprachig) oder weniger aus (z. B. 384D „Light“-Versionen). „E5-large“ und „GTE-large“ von Meta erzeugen ebenfalls 1024D-Einbettungen, während ihre Basis- oder „kleinen“ Varianten 768D oder 384D ergeben. Zu den Vertex-AI-Einbettungen von Google gehören 768D-Textmodelle und ein 3072D großes Modell „Gemini-Embedding-001“. Im Allgemeinen verbessern höhere Dimensionen oft die semantische Wiedergabetreue, erfordern aber mehr Speicher und Rechenleistung: In einem Benchmark hat e5-base (768D) einen Datensatz über doppelt so schnell indiziert wie ada-002 (1536D).
Einbettungsmodelle unterscheiden sich auch je nach Trainingsdaten und Mehrsprachigkeit. Die Einbettungs-APIs von OpenAI und Cohere sind proprietär (mit den entsprechenden Kosten und Nutzungsbeschränkungen), während Metas E5/GTE- und viele HuggingFace-Modelle Open Source sind (unter Apache-Lizenz). E5- und GTE-Modelle unterstützen mehr als 50 Sprachen, ebenso wie Coheres mehrsprachige v3-Modelle. Diese mehrsprachige Abdeckung ist wertvoll für die internationale Luftfahrtdokumentation. Die Domänenanpassung ist für spezielle Vokabulare (z. B. ATA-Kapitelsprache, Teilenomenklatur) entscheidend. Diese Modelle werden sofort einsatzbereit mit Webtexten und gängigen Korpora trainiert. Sie erfassen den Luftfahrtjargon möglicherweise nicht perfekt. Teams sollten eine Feinabstimmung oder die Verwendung von Adaptern für Wartungsprotokolle oder Handbücher in Erwägung ziehen. In der Praxis beginnen Unternehmenssysteme oft mit starken allgemeinen Einbettungen (wie OpenAI oder E5) und nehmen dann eine Feinabstimmung an domänenspezifischem Text vor.
Aus Leistungssicht variieren die Modelle in ihrer Latenz. Kleinere Modelle (z. B. E5-base-768) sind schneller bei der Inferenz, während große proprietäre Modelle (OpenAI 3072D) langsamer sind und möglicherweise nur eine Anfrage auf einmal zulassen. Wenn die Hardware vor Ort begrenzt ist, können kleinere oder quantisierte Modelle verwendet werden. Die Lizenzierung ist wichtig: OpenAI und Cohere berechnen pro Anfrage und haben Nutzungsrichtlinien, während offene Modelle wie E5/GTE oder Google BGE (offen über VertexAI mit Kontingenten) API-Kosten vermeiden. Zusammenfassend lässt sich sagen, dass jede Vektordatenbank Einbettungen von jedem dieser Modelle aufnehmen kann, Architekten sollten bei der Auswahl von Modellen für Luftfahrtdaten jedoch die Einbettungsdimensionalität, Kosten, mehrsprachige Unterstützung und Domäneneignung abwägen.
Arten von Vektordatenbanken
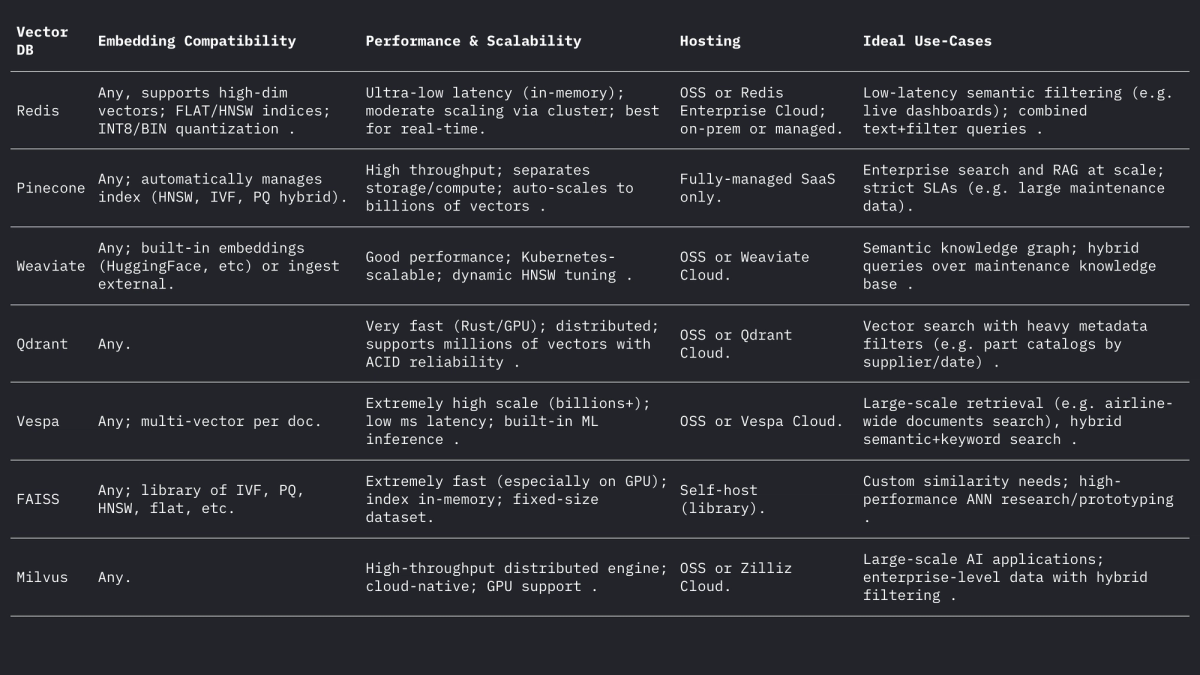
Es gibt eine Reihe von Vektordatenbanksystemen, von einfachen Bibliotheken bis hin zu vollwertigen Plattformen:
- Redis (Vektorsätze) – Redis ist ein speicherinterner Schlüssel-Wert-Speicher mit einem Vektorindexmodul. Er unterstützt FLAT- (exakte Brute-Force-) und HNSW-Indizes. Redis Vektorsätze ermöglichen einzigartige dynamische Aktualisierungen: HNSW-Diagramme werden bidirektional verwaltet, sodass Vektoren im laufenden Betrieb und mit sofortiger Wirkung hinzugefügt oder gelöscht werden können. Redis unterstützt Quantisierung (8-Bit oder Binär), um den Speicher (bis zu 4×–32×) bei minimalem Genauigkeitsverlust zu reduzieren. Es bietet auch hybride Filterung: Vektoren können neben Text-Tags oder numerischen Feldern gespeichert und in derselben Abfrage gefiltert werden (z. B. .year > 2020). Als speicherinterne Engine bietet Redis extrem niedrige Latenz auf Kosten der RAM-Nutzung. Es skaliert horizontal durch Clustering, obwohl die Clustergrößen normalerweise kleiner sind als bei dedizierten Vektorplattformen. Redis ist als Open Source oder über Redis Enterprise Cloud erhältlich.
- Pinecone – Ein vollständig verwalteter Cloud-Dienst für die Vektorsuche. Pinecone abstrahiert die gesamte Infrastruktur: Es trennt Speicher und Rechenleistung und skaliert auf Milliarden von Vektoren bei gleichzeitig schnellen Abfragezeiten. Die automatische Indexverwaltung (Mischung von HNSW, IVF, PQ usw.) sorgt für optimale Leistung. Der Kompromiss liegt in den Kosten und der Transparenz: Pinecone ist benutzerfreundlich (ohne Betriebsaufwand), aber teurer als OSS. Es zeichnet sich durch hohen Durchsatz und SLA-gebundene Workloads aus und unterstützt hybride (Keyword + Vektor) Abfragen sowie Enterprise-Funktionen. Pinecone ist ideal für Teams, die unternehmensweite Skalierbarkeit und Zuverlässigkeit ohne Serververwaltung benötigen.
- Weaviate – Eine graphenzentrierte Open-Source-Vektordatenbank (auch als verwalteter Dienst angeboten). Weaviate ermöglicht neben Vektoren auch die Strukturierung umfangreicher Schemata und Wissensgraphen. Es bietet eine GraphQL-API, um die semantische Vektorsuche mit herkömmlichen Abfragen zu kombinieren (hybrides Retrieval). Weaviate verwendet hauptsächlich HNSW-Indizes (und kann für kleine Datensätze flache Indizes verwenden). Es passt Suchparameter automatisch an oder ermöglicht asynchrone Indizierung für höheren Durchsatz. Mit Modulen für Deep Learning kann Weaviate sogar Vektoren generieren (z. B. über HuggingFace-Modelle). Es skaliert über Kubernetes und Cloud- oder lokale Cluster. Die Stärken von Weaviate sind die hybride semantische+symbolische Suche und die Flexibilität bei der Datenmodellierung; es eignet sich, wenn Beziehungen (z. B. Hierarchien von Teilen zu Flugzeugen) genauso wichtig sind wie Vektorähnlichkeiten.
- Qdrant – Eine Open-Source-Vektorsuchmaschine in Rust. Qdrant bietet einen leistungsstarken ANN-Index mit umfassender Metadatenfilterung. Es unterstützt HNSW-Indizes mit dynamischer Autoskalierung und bietet eine HTTP-API. Qdrant legt den Schwerpunkt auf strenge Filterung und Zuverlässigkeit – es unterstützt verteilte Bereitstellung, ACID-Transaktionen und GPU-Beschleunigung. Es arbeitet sehr gut mit großen Datensätzen und liefert eine hohe Trefferquote. Qdrant Cloud vereinfacht die Bereitstellung, ist aber auch im selbst gehosteten Zustand ebenso robust. Dies macht Qdrant zu einer guten Wahl, wenn Sie kombinierte Vektorähnlichkeit und strukturierte Filter benötigen (z. B. Suche nur innerhalb bestimmter Flugzeugmodelle oder Datumsbereiche).
- Vespa – Eine Open-Source-Suchmaschine und Analyse-Engine, ursprünglich von Yahoo. Vespa integriert auf einzigartige Weise die Vektorsuche mit der klassischen invertierten Indexsuche. Es kann Milliarden von Vektoren mit extremem Durchsatz verarbeiten: Die Plattform wirbt mit Unterstützung für Tausende von QPS bei <100 ms Latenzen über riesige Datenmengen. Vespa unterstützt mehrere Vektoren pro Dokument und eine hybride Suche (Semantik + Stichwort). Seine ANN-Indizierung umfasst HNSW (und neuartige Varianten wie HNSW-IF, die invertierte Dateifilterung kombinieren). Als vollwertiger Anwendungsserver unterstützt Vespa auch benutzerdefinierte Rankingmodelle und ML-Inferenz-Pipelines. Es eignet sich daher gut für große, unternehmenskritische Suchanwendungen (z. B. Suchportale für Fluggesellschaften), bei denen Skalierbarkeit und hybride Relevanz erforderlich sind. Vespa kann selbst verwaltet oder über Vespa Cloud genutzt werden.
- FAISS – Eine forschungsorientierte Bibliothek von Meta für die Ähnlichkeitssuche. FAISS ist keine eigenständige Datenbank, sondern eine Sammlung hochoptimierter Indizes (Flat, IVF, PQ, HNSW usw.), die auf CPU/GPU laufen. Sie erreicht eine außergewöhnliche Geschwindigkeit (insbesondere mit GPUs) und Flexibilität: nahezu jede Distanzmetrik oder Indizierungsmethode kann verwendet werden. FAISS enthält jedoch keine Speicher-/Abfrage-Engine oder Metadatenfilterung – Sie müssen es in Ihr eigenes System integrieren. Es eignet sich am besten, wenn maximale Leistung und Kontrolle über Indizierungsalgorithmen erforderlich sind. Beispielsweise wird FAISS häufig in der Computer Vision- und ML-Forschung verwendet, wo Rückruf und Geschwindigkeit von größter Bedeutung sind und die Datengrößen festgelegt sind. In der Luftfahrt könnte FAISS ein benutzerdefiniertes Suchtool für sehr hochdimensionale Einbettungen (z. B. bildbasierte Teileerkennung) unterstützen, erfordert aber eine umgebende Architektur.
- Milvus – Eine beliebte Open-Source-Vektordatenbank für große Workloads. Milvus bietet sowohl einen eigenständigen als auch einen verteilten Modus und unterstützt Milliarden von Vektoren mit hoher Konsistenz. Sie bietet mehrere Indextypen (HNSW, IVF, Annoy usw.) und Metriken (Cosinus, L2 usw.) sowie eine hybride Suche mittels Skalarfilterung. Milvus ist GPU-beschleunigt und Cloud-nativ (integriert mit Kubernetes). Es umfasst Enterprise-Funktionen wie Snapshots und Verschlüsselung und wird von Zilliz aktiv weiterentwickelt. Die Architektur von Milvus ist auf Skalierbarkeit und Leistung ausgelegt und eignet sich daher ideal für datenintensive Anwendungen wie die Analyse riesiger Archiven mit Handbüchern oder Sensorprotokollen. Zilliz bietet außerdem die Milvus Cloud für Managed Hosting an.
Jedes dieser Systeme behandelt Vektoren und Filter anders, aber alle unterstützen L2-, Skalarprodukt- und Kosinusdistanzen (oft durch Speicherung normalisierter Vektoren). Im Weaviate-Forum wird darauf hingewiesen, dass es sogar Vektoren mit bis zu 65535 Dimensionen speichern kann, weit über typischen Einbettungsgrößen, was die Flexibilität moderner Engines demonstriert. Zusammengefasst:
Anwendungsfälle in der Luftfahrt
Semantische Suche: Die Flugzeugwartung umfasst umfangreiche Sammlungen von Handbüchern, Servicebulletins und Regelwerken. Ein Vektorsuchsystem ermöglicht es Ingenieuren, natürlichsprachliche (oder sogar sprachbasierte) Abfragen zu stellen und relevante Passagen oder Dokumente semantisch abzurufen. Beispielsweise kann eine eingebettete Suche anstelle einer Stichwortsuche nach „Motorölleck“ Bulletin-Absätze finden, die „Hydraulikflüssigkeitsleck“ beschreiben, sofern sie kontextuell ähnlich sind. Wie Infosys/AWS gezeigt hat, ermöglicht die Speicherung jedes technischen Dokuments als Vektoren LLM-basierten Agenten, Wartungsanfragen zu beantworten, indem sie die relevantesten Dokumente aus dem Repository abrufen.
Fuzzy-Teileabgleich: Flugzeugteile haben oft kryptische Kennungen (NSN oder Teilenummern) und beschreibende Namen, die je nach Anbieter variieren. Vektor-Einbettungen von Teilebeschreibungen oder sogar Teilenummern (als Text behandelt) können Beinahe-Duplikate aufdecken, die durch regelbasiertes Matching nicht erkannt werden. In anderen Bereichen wurden Worteinbettungen verwendet, um Namen semantisch unscharf abzugleichen; ähnlich können Einbettungen von Teilebeschreibungen ein Teil der ähnlichsten Beschreibung in Lieferantenkatalogen zuordnen, selbst wenn Schreibweisen oder Codes unterschiedlich sind. Dies könnte den Bestand aus mehreren Quellen vereinheitlichen.
Protokollklassifizierung und -clusterung: Reparatur- und Fehlerprotokolle bestehen üblicherweise aus frei formuliertem Text. Einbettungsmodelle können Protokolleinträge in Vektoren umwandeln, und durch die Clusterung dieser Vektoren können ähnliche Fehlermuster automatisch gruppiert werden. Beispielsweise clustert das „HELP“-Framework Streaming-Systemprotokolle anhand ihrer Einbettungen, um wiederkehrende Protokollvorlagen zu erkennen. In der Luftfahrt könnte analoges Clustering häufige Fehlermodi identifizieren oder ungeplante Wartungseinträge ohne vordefinierte Bezeichnungen kategorisieren und so die Analyse häufiger Probleme ermöglichen (z. B. durch die Gruppierung von Vorfällen mit „seltsamen Vibrationen“). Diese unüberwachte semantische Gruppierung unterstützt Trendanalysen und die Vorhersage der Arbeitslast.
Conversational Retrieval (RAG): Einbettungen bilden die Grundlage für Retrieval-Augmented Generation (RAG)-Systeme, die Chatbots über Dokumente antreiben. Ein Beispiel für einen PDF-Chatbot veranschaulicht die Architektur: Text aus Handbüchern extrahieren, in Blöcke aufteilen, jeden Block einbetten und in einem Vektorspeicher (wie FAISS) speichern. Zur Laufzeit wird jede Benutzerabfrage eingebettet und verwendet, um die wichtigsten k Blöcke über den Vektorindex abzurufen. Diese Blöcke bilden den Kontext für ein LLM zur Beantwortung der Frage. In der Luftfahrt ermöglicht eine RAG-Pipeline einem Techniker, mit dem digitalen Zwilling des Flugzeugs zu „chatten“: Er kann beispielsweise fragen: „Wie wird der Staudruckschalter ausgetauscht?“ und erhält eine präzise Antwort aus den OEM-Handbüchern.
Prädiktive Fehlerindizierung: Historische Wartungsaufzeichnungen beschreiben Fehler und deren Behebung. Die Fehlerbeschreibungen könnten als Vektoren indexiert werden, sodass die Beschreibung eines neuen Vorfalls mit ähnlichen Fällen aus der Vergangenheit abgeglichen wird. Forschungen zur prädiktiven Wartung haben gezeigt, dass die Berechnung der semantischen Ähnlichkeit von Fehlertexten mithilfe von Transformer-Einbettungen (mit Kosinus- oder Pearson-Ähnlichkeit) die Gruppierung verwandter Fehler erfolgreich ermöglicht. In der Praxis könnte das System, wenn ein Mechaniker eine neue Fehlerbeschreibung protokolliert, vergangene Vorfälle mit hoher Einbettungsähnlichkeit abrufen, um wahrscheinliche Ursachen oder Überprüfungen vorzuschlagen und so effektiv anhand der Nähe im Einbettungsraum „vorherzusagen“.
Praktische Designüberlegungen
Einbettungsdimensionalität: Höherdimensionale Einbettungen erfassen mehr Nuancen, benötigen aber mehr Speicher und Rechenleistung. Gängige Optionen sind 768, 1024, 1536 oder 3072 Dimensionen. Die größeren Modelle von OpenAI verwenden beispielsweise 1536–3072 Dims, während Metas Basis-E5/GTE 768 oder 1024 verwendet. In einem Pilotversuch dauerte die Indizierung desselben Korpus mit 1536D-Einbettungen 2,4-mal länger als mit 768D. Wenn also Durchsatz und Latenz kritisch sind (z. B. geräteinterne Filterung von Hunderten von Abfragen/Sek.), können 768D oder 1024D ausreichen. Wenn ein maximaler Rückruf das Ziel ist (und die Hardware dies zulässt), sind größere Dims akzeptabel. In der Luftfahrt könnte man mit 1024D (ausgeglichen) beginnen und kleinere vs. größere Modelle bei Abrufaufgaben in Domänendaten testen.
Distanzmetrik: Die Wahl zwischen Kosinus (oder normalisiertem Skalarprodukt) und reinem euklidischen Wert hängt von der Einbettung ab. Die meisten modernen Texteinbettungen werden über Kosinus-Ähnlichkeit verglichen. Tekgöz et al. fanden beispielsweise heraus, dass Kosinus/Pearson-Metriken die beste Ähnlichkeit für Fehlerbeschreibungen ergaben. Redis und andere unterstützen die explizite Angabe von „COSINUS“ (normalisierende Vektoren im Hintergrund), wohingegen viele Systeme das innere Produkt auf vornormalisierten Vektoren verwenden. In der Praxis sind Kosinus und inneres Produkt gleichwertig, wenn Einbettungen normalisiert werden. Die euklidische Distanz ist für Text weniger gebräuchlich, aber konzeptionell ähnlich, wenn sich Vektoren auf einer Kugel befinden. Empfehlung: Verwenden Sie Kosinus für textbasierte Einbettungen.
Metadaten und hybride Strukturierung: Für eine verfeinerte Suche ist es wichtig, Vektoreinbettungen zusammen mit strukturierten Metadaten (Flugzeugmodell, ATA-Kapitel, Datum, Teilenummer usw.) zu speichern. Alle modernen Vektorspeicher erlauben das Anhängen von Metadaten an jeden Vektor. Mit Redis Vector Sets können Sie beispielsweise in derselben Abfrage nach JSON-Attributen filtern (z. B. WHERE aircraft_model = ‚A320‘ AND ATA = ‚21‘). Qdrant bietet leistungsstarke Boolesche Filterung, um Vektorergebnisse nach Metadaten einzugrenzen. Definieren Sie beim Entwerfen des Schemas Metadatenfelder (z. B. Modell, ATA, Datum, Teilenummer) und indizieren Sie sie normal, während Sie das Textfeld als VEKTOR markieren. Bei hybriden Abfragen wendet das System zuerst den Metadatenfilter an (oder kombiniert ihn über eine Punktestrafe) und durchsucht dann nur die Teilmenge nach nächsten Nachbarn, um die Präzision zu verbessern. Stellen Sie sicher, dass kritische Filter (z. B. Flugzeughecknummer oder Zeitbereich) auf indizierten Skalarfeldern liegen, um die DB-Filterung zu nutzen.
Latenz- und Durchsatzoptimierung: Die ANN-Indexparameter sollten auf die Ziellatenz optimiert werden. Bei HNSW führt eine Erhöhung des efSearch-Parameters zu einer höheren Trefferquote, erhöht aber die Abfragezeit linear. Ein praktischer Ansatz besteht darin, die Trefferquote gegenüber der Latenz anhand eines zurückgehaltenen Satzes zu vergleichen: Beginnen Sie mit einem niedrigen ef für die Geschwindigkeit und erhöhen Sie ihn dann, bis die Trefferquote ein Plateau erreicht. Weaviate unterstützt sogar ein „dynamisches ef“, das ef mit der gewünschten Ergebnisanzahl skaliert. Bei Batch-Workloads können Sie FLAT-Indizes (exakt) verwenden, um die Genauigkeit zu maximieren, während für Echtzeitabfragen im Bereich von Dutzenden von Millisekunden HNSW oder IVF mit optimierten Parametern besser geeignet ist. Quantisierung (8-Bit, Produktquantisierung) ist ein weiterer Hebel: Beispielsweise reduzieren die Q8- vs. BIN-Einstellungen von Redis den Speicher erheblich und beschleunigen die Suche, auf Kosten einer leicht verringerten Genauigkeit.
Indexaktualisierungen: Wenn sich Ihre Daten häufig ändern (neue Protokolleinträge oder manuelle Aktualisierungen), wählen Sie Systeme, die dynamische Indizierung unterstützen. Die HNSW-Implementierung von Redis ermöglicht Einfügungen und Löschungen im laufenden Betrieb, ohne dass der Index neu erstellt werden muss. Weaviate kann HNSW asynchron aktualisieren (so dass Schreibvorgänge Lesevorgänge nicht blockieren). Andere Systeme wie FAISS erfordern in der Regel eine Neuindizierung und sollten daher für überwiegend statische Korpora verwendet werden. Planen Sie eine Neuindizierung ein, wenn neue Handbücher eintreffen oder tägliche Protokolle hinzugefügt werden müssen. In vielen Luftfahrtsystemen ändern sich Handbücher nur langsam, aber es treffen tägliche Protokolle/Versandeinträge ein, sodass hybride Ansätze (neue Vektoren einen Tag lang in einen „heißen“ Index schreiben und jede Nacht zusammenführen) funktionieren können.
Zusammenfassung
Vektordatenbanken und Einbettungsmodelle ermöglichen zusammen umfassende semantische Intelligenz für Luftfahrtdaten. Hochwertige Einbettungen (z. B. 768–3072D-Modelle) übersetzen Handbücher, Protokolle und Teilebeschreibungen in durchsuchbare Vektoren, während spezialisierte Vektorspeicher (Redis, Pinecone, Weaviate, Qdrant, Vespa, FAISS, Milvus) die erforderlichen ANN-Indizes und Filterfunktionen für den großen Maßstab bereitstellen. Die obige Tabelle vergleicht die wichtigsten Funktionen: Redis und Qdrant zeichnen sich durch geringe Latenzzeiten beim Filtern aus; Pinecone und Milvus überzeugen bei großem Maßstab; Weaviate und Vespa unterstützen hybride (Graph+Vektor-)Abfragen; FAISS bietet höchste Leistung für benutzerdefinierte Pipelines. Die Auswahl der Einbettungen (Modell, Dimension, Normalisierung) und die Indexoptimierung (HNSW-Parameter, Quantisierung) müssen hinsichtlich Trefferquote und Geschwindigkeit abgewogen werden. Zusammen ermöglichen diese Technologien ML-Teams in der Luftfahrt, fortschrittliche Tools (Benutzeroberflächen für die semantische Suche, Wartungs-Chatbots, prädiktive Analysen) zu erstellen, die unstrukturierte Protokolle und Handbücher in umsetzbare Erkenntnisse umwandeln.
Trends in der Flugzeugwartung, die unter unsicheren Umständen an Dynamik gewinnen könnten
Flugzeuge bleiben länger im Einsatz, Lieferketten sind ein Pulverfass, und die Technologie entwickelt sich über Nacht weiter. Entdecken Sie die immer wichtiger werdenden Wartungstrends und erfahren Sie, was sie für Betreiber bedeuten, die in der Luft bleiben und profitabel bleiben wollen.

April 10, 2026
Mission Control: Hochleistungs‑Intelligence‑Infrastruktur für missionskritische Entscheidungsgeschwindigkeit
Jede Führungskraft, mit der ich in der Luft- und Raumfahrt, der Fertigung oder der Bauindustrie spreche, sagt dasselbe:
Unsere Systeme werden immer intelligenter, aber unsere Entscheidungen werden nicht in dem Tempo schneller oder sicherer, das der Betrieb erfordert.
In Hochsicherheitsumgebungen ist die Lücke zwischen Daten und Entscheidungen der Ort, an dem sich Risiken ansammeln. Wenn Abläufe komplexer, verteilter und zeitkritischer werden, brauchen Organisationen Intelligenzsysteme, die nicht nur schnell, sondern auch überprüfbar, deterministisch und von Grund auf sicher konzipiert sind.
Dies ist die technische Philosophie hinter Mission Control, unserer Hochleistungs‑Intelligence‑Infrastruktur, die für Echtzeit, Prüfungssicherheit und kryptografisch abgesicherte Entscheidungsgeschwindigkeit entwickelt wurde.

October 2, 2025
Auswahl der richtigen Flugzeugteile mit Schadenstoleranzanalyse
Die Zukunft der Flugsicherheit hängt ganz von den Ersatzteilen ab. Authentische, rückverfolgbare Teile sorgen für optimale Schadenstoleranz und Leistung in Flotten und damit für maximale Sicherheit und Beschaffungseffizienz.

September 30, 2025
So erschließen Sie neue Luftfahrtmärkte: Der vollständige Leitfaden für Teilelieferanten
Sie möchten neue Luftfahrtmärkte erschließen? Erfahren Sie, wie Lieferanten die Nachfrage analysieren, PMA-Teile verwalten und das Vertrauen der Fluggesellschaften gewinnen. Ein umfassender Leitfaden für globales Wachstum.

