Orchestrate AI insights into action
Vector DB. Unlock Aviation’s Unstructured Intelligence.
June 15, 2025
Vector databases index high-dimensional embedding vectors to enable semantic search over unstructured data, unlike traditional relational or document stores which use exact matches on keywords. Instead of tables or documents, vector stores manage dense numeric vectors (often 768–3072 dimensions) representing text or image semantics. At query time, the database finds nearest neighbors to a query vector using approximate nearest neighbor (ANN) search algorithms. For example, a graph-based index like Hierarchical Navigable Small Worlds (HNSW) constructs layered proximity graphs: a small top layer for coarse search and larger lower layers for refinement (see figure below). The search “hops” down these layers—quickly localizing to a cluster before exhaustively searching local neighbors. This trades off recall (finding the true nearest neighbors) against latency: raising the HNSW search parameter (efSearch) increases recall at the cost of higher query time .
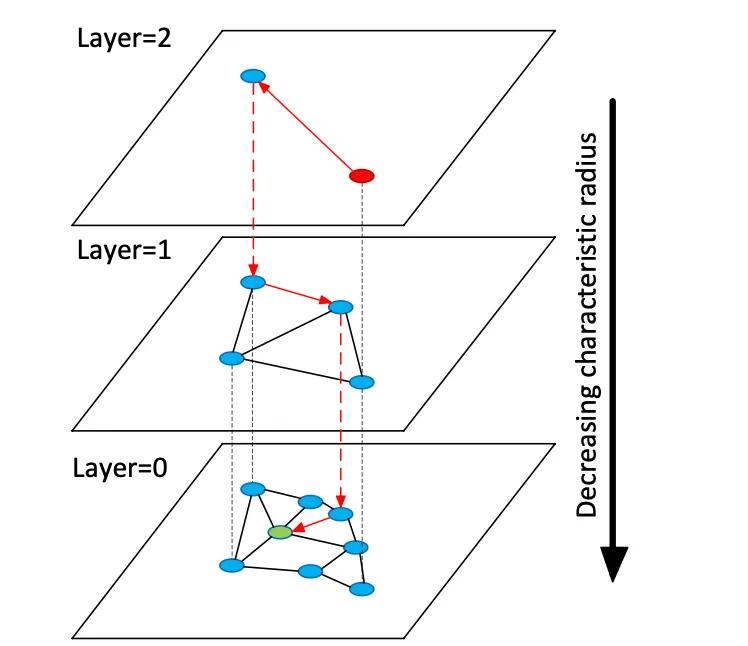
Figure: HNSW ANN search graph – vectors are organized in layers to speed nearest-neighbor queries (adapted from Devmy’s Redis Vector Sets explanation ).
Unlike exact search in relational tables, vector search can capture meaning: queries find semantically similar items, not just exact keyword matches. For aviation data (e.g. manuals or repair logs), this means engineers can retrieve relevant content even if the wording differs. Vector distances (cosine, dot product, or Euclidean) quantify similarity. When embeddings are normalized, cosine similarity and dot-product yield equivalent rankings . In practice, one commonly normalizes vectors and uses cosine similarity as the relevance metric. Key tradeoffs include recall vs. latency: larger indices and higher search parameters improve recall but raise latency . Vector DBs provide tunable indices (HNSW, IVF, flat scan) to balance speed versus accuracy.
Embedding Models
Modern embedding models convert text (or other data) to vectors. Leading models include OpenAI’s text-embedding-3-large, Cohere’s embed-multilingual-v3, Google’s Gemini/BGE models, Meta’s E5 and GTE families, and many HuggingFace models (e.g. Sentence-BERT variants). These models differ in dimensionality, data coverage, and inference cost. For instance, OpenAI’s text-embedding-3-large produces 3072-dimensional vectors, significantly larger than earlier Ada-002 (1536D) . Cohere’s v3 models typically output 1024D (English or multilingual) or smaller (e.g. 384D “light” versions) . Meta’s E5-large and GTE-large also produce 1024D embeddings , whereas their base or “small” variants yield 768D or 384D. Google’s Vertex-AI embeddings include 768D text models and a 3072D “gemini-embedding-001” large model . In general, higher dimensions often improve semantic fidelity but require more storage and compute: e5-base (768D) indexed a dataset over 2× faster than ada-002 (1536D) in one benchmark .
Embedding models also vary by training data and multilinguality. OpenAI’s and Cohere’s embedding APIs are proprietary (with associated costs and usage limits), while Meta’s E5/GTE and many HuggingFace models are open-source (Apache-licensed). E5 and GTE models support 50+ languages , as do Cohere’s multilingual-v3 models . This multilingual coverage is valuable for international aviation documentation. Domain adaptation is critical for specialized vocabularies (e.g. ATA chapter language, part nomenclature). Out-of-the-box, these models are trained on web text and common corpora; they may not perfectly capture aviation jargon. Teams should consider fine-tuning or using adapters on maintenance logs or manuals. In practice, enterprise systems often start with strong general embeddings (like OpenAI or E5) and then fine-tune on domain-specific text.
From a performance standpoint, models vary in latency. Smaller models (e.g. E5-base-768) are faster at inference, whereas large proprietary models (OpenAI’s 3072D) are slower and may only allow one request at a time . If on-prem hardware is limited, smaller or quantized models can be used. Licensing matters: OpenAI and Cohere charge per request and have usage policies, while open models like E5/GTE or Google’s BGE (open via VertexAI with quotas) avoid API costs. In summary, any vector DB can ingest embeddings from any of these models, but architects should weigh embedding dimensionality, cost, multilingual support, and domain fit when selecting models for aviation data.
Types of Vector Databases
A range of vector database systems exist, from lightweight libraries to full-fledged platforms:
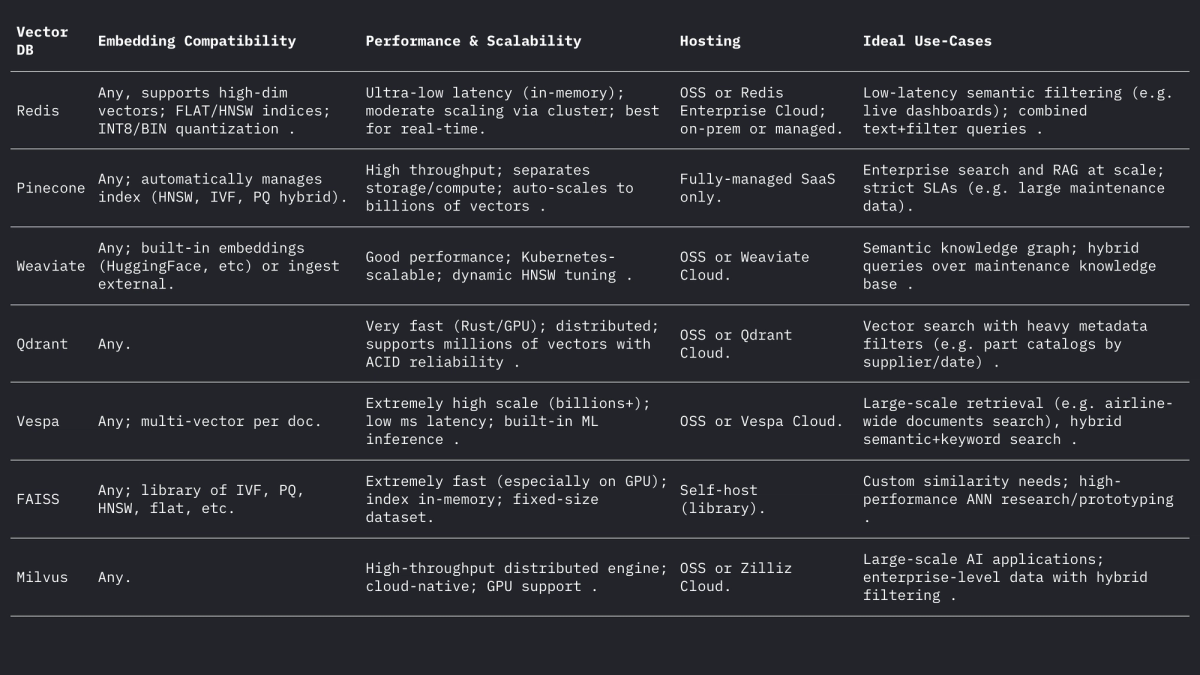
- Redis (Vector Sets) – Redis is an in-memory key-value store with a vector index module. It supports FLAT (exact brute-force) and HNSW indexes . Redis Vector Sets uniquely allow dynamic updates: HNSW graphs are maintained bidirectionally so vectors can be added or deleted on the fly with immediate effect . Redis supports quantization (8-bit or binary) to reduce memory (up to 4×–32×) with minimal accuracy loss . It also provides hybrid filtering: vectors may be stored alongside text tags or numeric fields and filtered (e.g. .year > 2020) in the same query . As an in-memory engine, Redis delivers ultra-low latency at the cost of RAM usage. It scales horizontally via clustering, though cluster sizes are typically smaller than dedicated vector platforms. Redis is available as open-source or through Redis Enterprise Cloud.
- Pinecone – A fully-managed vector search cloud service. Pinecone abstracts away all infrastructure: it separates storage from compute and scales to billions of vectors while maintaining fast query times . It automatically manages indexes under the hood (mixing HNSW, IVF, PQ, etc.) for optimal performance. The tradeoff is cost and opacity: Pinecone is easy to use (no ops) but more expensive than OSS. It excels at high throughput and SLA-bound workloads, supporting hybrid (keyword + vector) queries and enterprise features. Pinecone is ideal for teams that need enterprise-grade scalability and reliability without managing servers .
- Weaviate – An open-source graph-centric vector DB (also offered as a managed service). Weaviate allows rich schema and knowledge-graph structuring alongside vectors . It offers a GraphQL API to combine semantic vector search with traditional queries (hybrid retrieval). Weaviate primarily uses HNSW indices (and can use flat index for small datasets) . It automatically adjusts search parameters or allows asynchronous indexing for throughput. With modules for deep-learning, Weaviate can even generate vectors (e.g. via HuggingFace models). It scales via Kubernetes and cloud or on-premise clusters. Weaviate’s strengths are hybrid semantic+symbolic search and flexibility in data modeling ; it’s suitable when relationships (e.g. part-to-aircraft hierarchies) matter as much as vector similarity.
- Qdrant – An open-source vector search engine in Rust. Qdrant offers a high-performance ANN index with rich metadata filtering . It supports HNSW indexes with dynamic autoscaling and provides an HTTP API. Notably, Qdrant’s emphasis is on strict filtering and reliability – it supports distributed deployment, ACID transactions, and GPU acceleration. It performs very well on large datasets and returns high recall. . Qdrant Cloud simplifies deployment, but it is equally robust self-hosted. This makes Qdrant a strong choice when you need combined vector similarity and structured filters (e.g. search only within certain aircraft models or date ranges) .
- Vespa – An open-source search and analytics engine originally from Yahoo. Vespa uniquely integrates vector search with classic inverted-index search. It can handle billions of vectors with extreme throughput: the platform advertises support for thousands of QPS at <100ms latencies over vast data . Vespa supports multi-vector per document and hybrid search (semantic + keyword). Its ANN indexing includes HNSW (and novel variants like HNSW-IF that combine inverted-file filtering) . As a full application server, Vespa also supports custom ranking models and ML inference pipelines. It is therefore well-suited for large-scale, mission-critical search applications (e.g. airline-wide search portals) where scale and hybrid relevance are required . Vespa can be self-managed or used via Vespa Cloud.
- FAISS – A research-grade library by Meta for similarity search. FAISS is not a standalone database but a collection of highly optimized indexes (Flat, IVF, PQ, HNSW, etc.) that run on CPU/GPU . It achieves exceptional speed (especially with GPUs) and flexibility: nearly any distance metric or indexing method can be used. However, FAISS does not include a storage/query engine or metadata filtering – you must integrate it into your own system. It is most suitable when maximum performance and control over indexing algorithms are needed . For example, FAISS is widely used in computer vision and ML research where recall and speed are paramount and data sizes are fixed. In aviation, FAISS might underpin a custom search tool for very high-dimensional embeddings (e.g. image-based part recognition), but it requires a surrounding architecture.
- Milvus – A popular open-source vector database designed for large-scale workloads. Milvus offers both standalone and distributed modes, supporting billions of vectors with strong consistency . It provides multiple index types (HNSW, IVF, Annoy, etc.) and metrics (cosine, L2, etc.), plus hybrid search via scalar filtering. Milvus is GPU-accelerated and cloud-native (integrates with Kubernetes). It includes enterprise features like snapshots and encryption, and is actively developed by Zilliz. Milvus’s architecture is built for scale and performance – making it ideal for data-intensive applications such as analyzing massive archives of manuals or sensor logs. Zilliz also offers Milvus Cloud for managed hosting.
Each of these systems handles vectors and filters differently, but all support L2, inner-product (dot), and cosine distances (often by storing normalized vectors). Weaviate’s forum notes it can even store vectors up to 65535 dimensions , far above typical embedding sizes, demonstrating the flexibility of modern engines. Summarized:
Use Cases in Aviation
Semantic Search: Aircraft maintenance involves vast collections of manuals, service bulletins, and regulation documents. A vector-search system lets engineers pose natural-language queries (or even voice queries) and retrieve relevant passages or documents semantically. For example, instead of keyword search on “engine oil leak”, an embedding search may find bulletin paragraphs describing “hydraulic fluid leak” if contextually similar. As Infosys/AWS showed, storing each technical document as vectors allows LLM-powered agents to answer maintenance queries by retrieving the most relevant documents from the repository .
Fuzzy Part Matching: Aviation parts often have cryptic identifiers (NSN or part numbers) and descriptive names that vary across vendors. Vector embeddings of part descriptions or even the part numbers (treated as text) can reveal near-duplicates that rule-based matching misses. In other domains, word embeddings have been used to fuzzy-match names semantically ; similarly, embeddings of part descriptors can match a part to its closest description across supplier catalogs even if spellings or codes differ. This could unify inventory from multiple sources.
Log Classification & Clustering: Repair and fault logs are usually free-form text. Embedding models can convert log entries into vectors, and clustering these vectors can automatically group similar fault patterns. For instance, the “HELP” framework clusters streaming system logs by their embeddings to discover recurring log templates . In aviation, analogous clustering could identify common failure modes or categorize unscheduled maintenance entries without predefined labels, enabling analytics on frequent issues (e.g. clustering “strange vibration” incidents together). This unsupervised semantic grouping aids in trend analysis and workload prediction.
Conversational Retrieval (RAG): Embeddings underlie Retrieval-Augmented Generation (RAG) systems that power chatbots over documents. A PDF chatbot example shows the architecture: extract text from manuals, chunk it, embed each chunk, and store in a vector store (like FAISS) . At runtime, each user query is embedded and used to retrieve the top-k relevant chunks via the vector index. These chunks form the context for an LLM to answer the question. For aviation, a RAG pipeline lets a technician “chat” with the aircraft’s digital twin: e.g. asking “What is the procedure for replacing the pitot heat switch?” and getting a precise answer sourced from the OEM manuals.
Predictive Failure Indexing: Historical maintenance records describe failures and fixes. One could index the failure descriptions as vectors so that a new incident’s description is matched to similar past cases. Research in predictive maintenance found that computing semantic similarity of failure text using transformer embeddings (with cosine or Pearson similarity) successfully groups related failures . In practice, when a mechanic logs a new fault description, the system could retrieve past incidents with high embedding similarity to suggest likely root causes or checks, effectively “predicting” based on proximity in the embedding space.
Practical Design Considerations
Embedding Dimensionality: Higher-dimensional embeddings capture more nuance but cost more in storage and computation. Common choices are 768, 1024, 1536, or 3072 dimensions. For example, OpenAI’s larger models use 1536–3072 dims, whereas Meta’s base E5/GTE uses 768 or 1024 . In a pilot experiment, indexing the same corpus took 2.4× longer with 1536D embeddings than 768D . Thus, if throughput and latency are critical (e.g. on-device filtering of hundreds of queries/sec), 768D or 1024D may suffice. If maximum recall is the goal (and hardware allows), larger dims are acceptable. For aviation, one might start with 1024D (balanced) and test smaller vs. larger models on retrieval tasks in domain data.
Distance Metric: Choosing cosine (or normalized dot-product) vs. raw Euclidean depends on the embedding. Most modern text embeddings are compared via cosine similarity. For example, Tekgöz et al. found cosine/Pearson metrics gave the best similarity for failure descriptions . Redis and others support specifying “COSINE” explicitly (behind the scenes normalizing vectors), whereas many systems use inner-product on pre-normalized vectors. In practice, cosine and inner-product are equivalent if embeddings are normalized. Euclidean distance is less common for text but conceptually similar when vectors are on a sphere. Recommendation: use cosine for text-based embeddings.
Metadata and Hybrid Structuring: It is important to store vector embeddings alongside structured metadata (aircraft model, ATA chapter, date, part number, etc.) for refined search. All modern vector stores allow attaching metadata to each vector. For example, Redis Vector Sets let you filter by JSON attributes in the same query (e.g. WHERE aircraft_model = 'A320' AND ATA = '21') . Qdrant provides powerful Boolean filtering to narrow vector results by metadata . When designing the schema, define metadata fields (e.g. model, ata, date, part_no) and index them normally while marking the text field as a VECTOR. In hybrid queries, the system first applies the metadata filter (or combines it via a score penalty) and then searches only the subset for nearest neighbors, improving precision. Ensure critical filters (e.g. aircraft tail number or time range) are on indexed scalar fields to leverage DB filtering.
Latency and Throughput Tuning: ANN index parameters should be tuned for target latency. For HNSW, raising the efSearch parameter yields higher recall but linearly increases query time . A practical approach is to benchmark recall vs. latency on a held-out set: start with a low ef for speed, then increment until recall plateau. Weaviate even supports a “dynamic ef” that scales ef with the desired result count . For batch workloads, one can use FLAT indexes (exact) to maximize accuracy, whereas for real-time dozens-of-milliseconds queries, HNSW or IVF with tuned parameters is better . Quantization (8-bit, product quantization) is another lever: e.g. Redis’s Q8 vs BIN settings dramatically reduce memory and speed up search , at the expense of a slight drop in accuracy.
Index Updates: If your data changes frequently (new log entries or manual updates), choose systems that support dynamic indexing. Redis’s HNSW implementation allows on-the-fly insertions and deletions without rebuilding the index . Weaviate can update HNSW asynchronously (so writes do not block reads) . Others like FAISS typically require re-indexing, so use them for mostly-static corpora. Plan for re-indexing if new manuals arrive or daily logs must be added. In many aviation systems, manuals change slowly but daily logs/dispatch entries arrive, so hybrid approaches (write new vectors to a “hot” index for a day and merge nightly) can work.
Summary
Vector databases and embedding models together enable rich semantic intelligence over aviation data. High-quality embeddings (e.g. 768–3072D models) translate manuals, logs, and parts descriptions into searchable vectors, while specialized vector stores (Redis, Pinecone, Weaviate, Qdrant, Vespa, FAISS, Milvus) provide the ANN indexes and filtering needed at scale. The table above compares key features: Redis and Qdrant excel at low-latency with filtering; Pinecone and Milvus shine at massive scale; Weaviate and Vespa support hybrid (graph+vector) queries; FAISS offers ultimate performance for custom pipelines. Embedding choices (model, dimension, normalization) and index tuning (HNSW parameters, quantization) must be balanced for recall vs. speed. Together, these technologies allow aviation ML teams to build advanced tools (semantic search UIs, maintenance chatbots, predictive analytics) that convert unstructured logs and manuals into actionable insights.
Aviation Maintenance Trends That May Gain Momentum in Uncertain Circumstances
Aircraft are staying in service longer, supply chains are a powder keg, and the tech is evolving overnight. Discover the maintenance trends gaining momentum and what they mean for operators trying to stay airborne and profitable.

April 14, 2026
ePlane AI's Unlock $500M in Quoting Opportunity with Automation! | Free Webinar
See how sales operators are automating RFQ extraction, eliminating manual data entry errors, and scaling their quoting operations with precision and consistency to unlock revenue.
April 10, 2026
Mission Control: High‑Performance Intelligence Infrastructure for Mission‑Critical Decision Velocity
Every leader I speak with across aerospace, manufacturing, or construction says the same thing:
Our systems are getting smarter, but our decisions aren’t getting faster or safer at the pace operations demand.
In high‑integrity environments, the gap between data and decisions is where risk accumulates. As operations grow more complex, distributed, and time‑sensitive, organizations need intelligence systems that are not just fast but verifiable, deterministic, and secure by design.
This is the engineering philosophy behind Mission Control, our high‑performance intelligence infrastructure built for real‑time, audit‑ready, cryptographically secure decision velocity.

February 2, 2026
ePlane AI at MRO Americas 2026 | The Future of Maintenance, Supply Chain, and Operational Intelligence
MRO Americas is where the aviation maintenance ecosystem aligns on what’s next — and in 2026, the conversation is shifting decisively toward operational intelligence, automation, and data‑driven decisioning. This year, ePlane AI is joining the industry in Orlando to demonstrate how deterministic, agentic intelligence is reshaping maintenance, supply chain, and technical operations.

