Trasforma le intuizioni dell’IA in azioni concrete
Vector DB. Sblocca l'intelligenza non strutturata dell'aviazione.
giugno 15, 2025
I database vettoriali indicizzano vettori di incorporamento ad alta dimensionalità per consentire la ricerca semantica su dati non strutturati, a differenza dei tradizionali archivi relazionali o di documenti che utilizzano corrispondenze esatte per le parole chiave. Invece di tabelle o documenti, gli archivi vettoriali gestiscono vettori numerici densi (spesso con dimensioni comprese tra 768 e 3072) che rappresentano la semantica di testo o immagini. In fase di query, il database trova i vicini più prossimi a un vettore di query utilizzando algoritmi di ricerca di vicini più prossimi approssimati (ANN). Ad esempio, un indice basato su grafi come Hierarchical Navigable Small Worlds (HNSW) costruisce grafi di prossimità a strati: un piccolo strato superiore per la ricerca grossolana e strati inferiori più grandi per il raffinamento (vedi figura sotto). La ricerca "salta" lungo questi strati, localizzandosi rapidamente in un cluster prima di cercare in modo esaustivo i vicini locali. Questo bilancia la recall (ricerca dei veri vicini più prossimi) con la latenza: aumentando il parametro di ricerca HNSW (efSearch) aumenta la recall a scapito di un tempo di query più lungo.
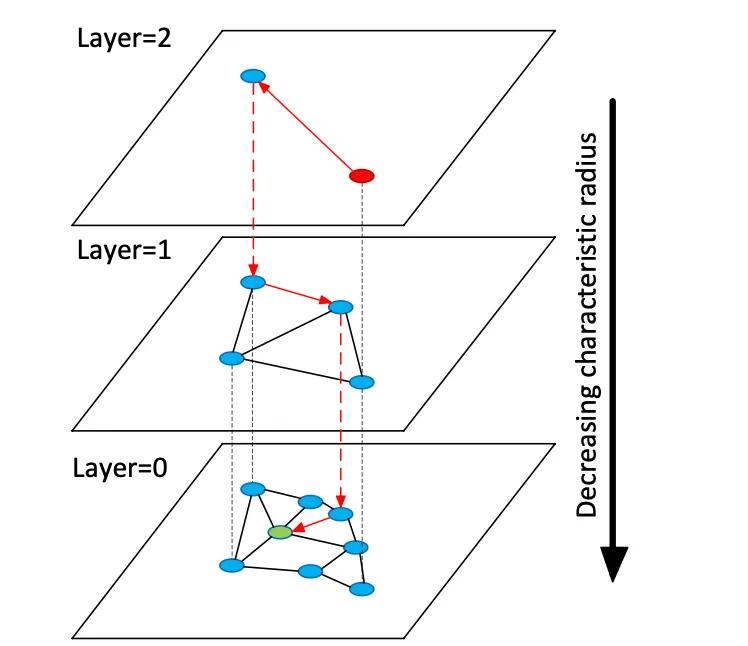
Figura: Grafico di ricerca HNSW ANN: i vettori sono organizzati in livelli per velocizzare le query al vicino più prossimo (adattato dalla spiegazione dei set di vettori Redis di Devmy).
A differenza della ricerca esatta nelle tabelle relazionali, la ricerca vettoriale può catturare il significato: le query trovano elementi semanticamente simili, non solo corrispondenze esatte di parole chiave. Per i dati aeronautici (ad esempio manuali o registri di riparazione), ciò significa che gli ingegneri possono recuperare contenuti pertinenti anche se la formulazione è diversa. Le distanze vettoriali (coseno, prodotto scalare o euclidee) quantificano la similarità. Quando gli embedding vengono normalizzati, la similarità del coseno e il prodotto scalare producono classifiche equivalenti. In pratica, si normalizzano comunemente i vettori e si utilizza la similarità del coseno come metrica di rilevanza. I compromessi chiave includono richiamo vs. latenza: indici più grandi e parametri di ricerca più elevati migliorano il richiamo ma aumentano la latenza. I database vettoriali forniscono indici regolabili (HNSW, IVF, scansione piatta) per bilanciare velocità e accuratezza.
Modelli di incorporamento
I moderni modelli di embedding convertono il testo (o altri dati) in vettori. I modelli principali includono text-embedding-3-large di OpenAI, embed-multilingual-v3 di Cohere, i modelli Gemini/BGE di Google, le famiglie E5 e GTE di Meta e molti modelli HuggingFace (ad esempio, le varianti Sentence-BERT). Questi modelli differiscono per dimensionalità, copertura dei dati e costo di inferenza. Ad esempio, text-embedding-3-large di OpenAI produce vettori a 3072 dimensioni, significativamente più grandi del precedente Ada-002 (1536D). I modelli v3 di Cohere in genere producono 1024D (inglese o multilingue) o più piccoli (ad esempio, versioni "light" a 384D). Anche E5-large e GTE-large di Meta producono embedding a 1024D, mentre le loro varianti base o "small" producono 768D o 384D. Gli embedding Vertex-AI di Google includono modelli di testo 768D e un modello di grandi dimensioni "gemini-embedding-001" 3072D. In generale, dimensioni più elevate spesso migliorano la fedeltà semantica, ma richiedono maggiore spazio di archiviazione e capacità di calcolo: e5-base (768D) ha indicizzato un set di dati con una velocità oltre 2 volte superiore rispetto ad ada-002 (1536D) in un benchmark.
I modelli di incorporamento variano anche in base ai dati di training e al multilinguismo. Le API di incorporamento di OpenAI e Cohere sono proprietarie (con relativi costi e limiti di utilizzo), mentre E5/GTE di Meta e molti modelli HuggingFace sono open source (con licenza Apache). I modelli E5 e GTE supportano oltre 50 lingue, così come i modelli multilingua-v3 di Cohere. Questa copertura multilingue è preziosa per la documentazione aeronautica internazionale. L'adattamento del dominio è fondamentale per i vocabolari specializzati (ad esempio, il linguaggio dei capitoli ATA, la nomenclatura delle parti). Questi modelli vengono addestrati di default su testo web e corpora comuni; potrebbero non catturare perfettamente il gergo aeronautico. I team dovrebbero valutare la possibilità di una messa a punto o l'utilizzo di adattatori su registri di manutenzione o manuali. In pratica, i sistemi aziendali spesso iniziano con solidi incorporamenti generali (come OpenAI o E5) e poi si perfezionano su testo specifico del dominio.
Dal punto di vista delle prestazioni, la latenza dei modelli varia. I modelli più piccoli (ad esempio E5-base-768) sono più veloci nell'inferenza, mentre i modelli proprietari di grandi dimensioni (3072D di OpenAI) sono più lenti e potrebbero consentire una sola richiesta alla volta. Se l'hardware on-prem è limitato, è possibile utilizzare modelli più piccoli o quantizzati. Le licenze sono importanti: OpenAI e Cohere addebitano costi per richiesta e hanno policy di utilizzo, mentre i modelli aperti come E5/GTE o BGE di Google (aperti tramite VertexAI con quote) evitano i costi delle API. In sintesi, qualsiasi database vettoriale può acquisire embedding da uno qualsiasi di questi modelli, ma gli architetti dovrebbero valutare la dimensionalità dell'embedding, il costo, il supporto multilingue e l'adattamento al dominio quando selezionano i modelli per i dati aeronautici.
Tipi di database vettoriali
Esiste una gamma di sistemi di database vettoriali, da librerie leggere a piattaforme complete:
- Redis (Vector Sets) – Redis è un archivio chiave-valore in memoria con un modulo di indice vettoriale. Supporta indici FLAT (exact brute-force) e HNSW. I Vector Set di Redis consentono aggiornamenti dinamici in modo univoco: i grafici HNSW sono gestiti bidirezionalmente, quindi i vettori possono essere aggiunti o eliminati al volo con effetto immediato. Redis supporta la quantizzazione (8 bit o binaria) per ridurre la memoria (fino a 4×–32×) con una perdita minima di accuratezza. Fornisce inoltre un filtraggio ibrido: i vettori possono essere memorizzati insieme a tag di testo o campi numerici e filtrati (ad esempio, .year > 2020) nella stessa query. Come motore in memoria, Redis offre una latenza estremamente bassa a scapito dell'utilizzo di RAM. Scala orizzontalmente tramite clustering, sebbene le dimensioni dei cluster siano in genere inferiori rispetto alle piattaforme vettoriali dedicate. Redis è disponibile come open source o tramite Redis Enterprise Cloud.
- Pinecone – Un servizio cloud di ricerca vettoriale completamente gestito. Pinecone astrae tutta l'infrastruttura: separa lo storage dal calcolo e scala fino a miliardi di vettori mantenendo tempi di query rapidi. Gestisce automaticamente gli indici in modo integrato (combinando HNSW, IVF, PQ, ecc.) per prestazioni ottimali. Il compromesso è il costo e l'opacità: Pinecone è facile da usare (nessuna operazione) ma più costoso di OSS. Eccelle per carichi di lavoro ad alta velocità e vincolati a SLA, supportando query ibride (parola chiave + vettori) e funzionalità aziendali. Pinecone è ideale per i team che necessitano di scalabilità e affidabilità di livello enterprise senza dover gestire server.
- Weaviate – Un database vettoriale open source incentrato sui grafici (offerto anche come servizio gestito). Weaviate consente una strutturazione avanzata di schemi e grafi di conoscenza insieme ai vettori. Offre un'API GraphQL per combinare la ricerca vettoriale semantica con query tradizionali (recupero ibrido). Weaviate utilizza principalmente indici HNSW (e può utilizzare indici piatti per piccoli set di dati). Regola automaticamente i parametri di ricerca o consente l'indicizzazione asincrona per il throughput. Grazie ai moduli per il deep learning, Weaviate può persino generare vettori (ad esempio tramite modelli HuggingFace). È scalabile tramite Kubernetes e cluster cloud o on-premise. I punti di forza di Weaviate sono la ricerca ibrida semantica+simbolica e la flessibilità nella modellazione dei dati; è adatto quando le relazioni (ad esempio, gerarchie da componente ad aeromobile) sono importanti tanto quanto la similarità dei vettori.
- Qdrant – Un motore di ricerca vettoriale open source in Rust. Qdrant offre un indice ANN ad alte prestazioni con un ricco filtro per i metadati. Supporta indici HNSW con scalabilità automatica dinamica e fornisce un'API HTTP. In particolare, Qdrant si concentra su un filtraggio rigoroso e sull'affidabilità: supporta l'implementazione distribuita, le transazioni ACID e l'accelerazione GPU. Offre ottime prestazioni su dataset di grandi dimensioni e restituisce un elevato recall. Qdrant Cloud semplifica l'implementazione, ma è altrettanto robusto in modalità self-hosted. Questo rende Qdrant una scelta ottimale quando si necessita di similarità vettoriale combinata con filtri strutturati (ad esempio, la ricerca solo all'interno di determinati modelli di aeromobili o intervalli di date).
- Vespa – Un motore di ricerca e analisi open source originariamente di Yahoo. Vespa integra in modo unico la ricerca vettoriale con la classica ricerca a indice invertito. Può gestire miliardi di vettori con un throughput estremo: la piattaforma pubblicizza il supporto per migliaia di QPS con latenze <100 ms su dati di grandi dimensioni. Vespa supporta la ricerca multi-vettore per documento e la ricerca ibrida (semantica + parola chiave). La sua indicizzazione ANN include HNSW (e nuove varianti come HNSW-IF che combinano il filtraggio a file invertito). Come server applicativo completo, Vespa supporta anche modelli di ranking personalizzati e pipeline di inferenza ML. È quindi adatto per applicazioni di ricerca su larga scala e mission-critical (ad esempio, portali di ricerca per compagnie aeree) in cui sono richieste scalabilità e rilevanza ibrida. Vespa può essere autogestito o utilizzato tramite Vespa Cloud.
- FAISS – Una libreria di livello di ricerca di Meta per la ricerca di similarità. FAISS non è un database autonomo, ma una raccolta di indici altamente ottimizzati (Flat, IVF, PQ, HNSW, ecc.) che operano su CPU/GPU. Raggiunge velocità eccezionali (soprattutto con GPU) e flessibilità: è possibile utilizzare praticamente qualsiasi metrica di distanza o metodo di indicizzazione. Tuttavia, FAISS non include un motore di archiviazione/query né un filtro per i metadati: è necessario integrarlo nel proprio sistema. È particolarmente indicato quando sono necessarie massime prestazioni e controllo sugli algoritmi di indicizzazione. Ad esempio, FAIISS è ampiamente utilizzato nella ricerca sulla visione artificiale e sul machine learning, dove richiamo e velocità sono fondamentali e le dimensioni dei dati sono fisse. In ambito aeronautico, FAIISS potrebbe supportare uno strumento di ricerca personalizzato per incorporamenti ad altissima dimensionalità (ad esempio, il riconoscimento di componenti basato su immagini), ma richiede un'architettura di riferimento.
- Milvus – Un popolare database vettoriale open source progettato per carichi di lavoro su larga scala. Milvus offre sia modalità standalone che distribuita, supportando miliardi di vettori con elevata coerenza. Fornisce diversi tipi di indice (HNSW, IVF, Annoy, ecc.) e metriche (coseno, L2, ecc.), oltre alla ricerca ibrida tramite filtro scalare. Milvus è accelerato da GPU e cloud-native (si integra con Kubernetes). Include funzionalità aziendali come snapshot e crittografia ed è sviluppato attivamente da Zilliz. L'architettura di Milvus è progettata per garantire scalabilità e prestazioni, rendendola ideale per applicazioni ad alta intensità di dati come l'analisi di archivi di manuali o log di sensori di grandi dimensioni. Zilliz offre anche Milvus Cloud per l'hosting gestito.
Ognuno di questi sistemi gestisce vettori e filtri in modo diverso, ma tutti supportano le distanze L2, prodotto interno (punto) e coseno (spesso memorizzando vettori normalizzati). Il forum di Weaviate sottolinea che può persino memorizzare vettori fino a 65535 dimensioni, ben al di sopra delle dimensioni di embedding tipiche, a dimostrazione della flessibilità dei motori moderni. In sintesi:
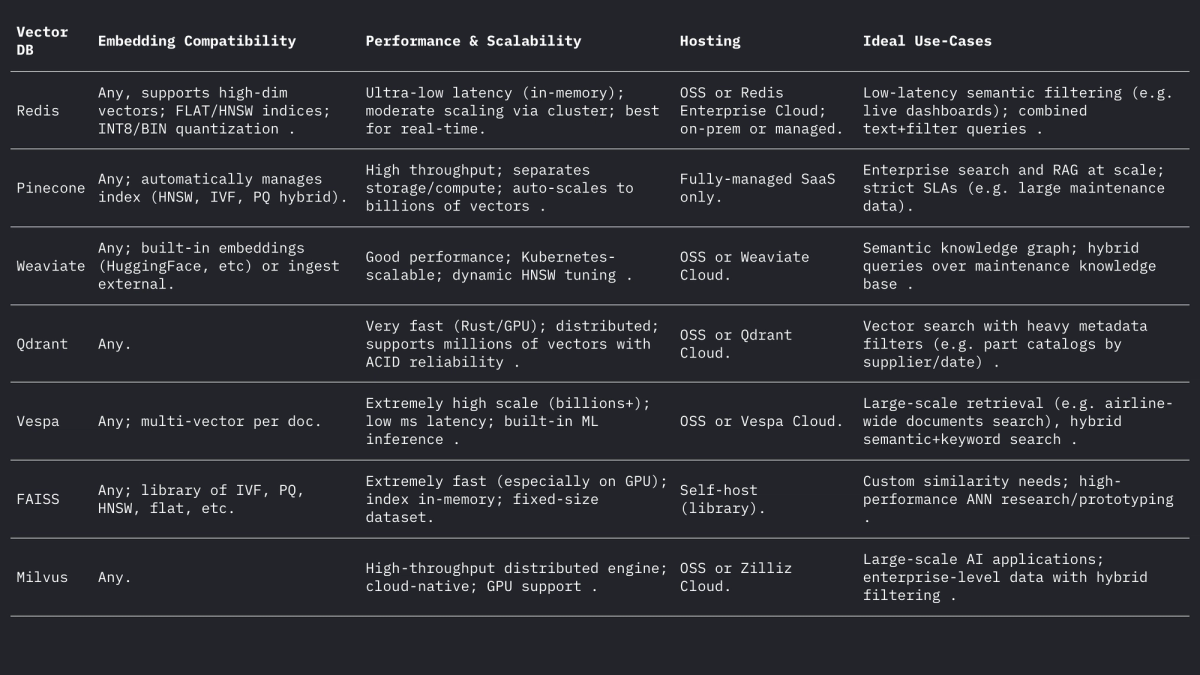
Casi d'uso nell'aviazione
Ricerca semantica: la manutenzione degli aeromobili coinvolge vaste raccolte di manuali, bollettini di servizio e documenti normativi. Un sistema di ricerca vettoriale consente agli ingegneri di porre query in linguaggio naturale (o anche vocali) e di recuperare semanticamente passaggi o documenti pertinenti. Ad esempio, invece di una ricerca per parola chiave su "perdita di olio motore", una ricerca incorporata potrebbe trovare paragrafi del bollettino che descrivono "perdita di fluido idraulico" se contestualmente simili. Come dimostrato da Infosys/AWS, l'archiviazione di ogni documento tecnico come vettori consente agli agenti basati su LLM di rispondere alle query di manutenzione recuperando i documenti più pertinenti dal repository.
Corrispondenza fuzzy dei componenti: i componenti aeronautici hanno spesso identificatori criptici (NSN o codici componente) e nomi descrittivi che variano a seconda del fornitore. L'inserimento di vettori nelle descrizioni dei componenti o persino nei codici componente (trattati come testo) può rivelare duplicati quasi identici che la corrispondenza basata su regole non riesce a individuare. In altri settori, l'inserimento di parole è stato utilizzato per la corrispondenza fuzzy dei nomi a livello semantico; analogamente, l'inserimento di descrittori di componenti può far corrispondere un componente alla sua descrizione più simile nei cataloghi dei fornitori, anche se l'ortografia o i codici differiscono. Ciò potrebbe unificare l'inventario da più fonti.
Classificazione e clustering dei log: i log di riparazione e guasti sono solitamente in formato testo libero. I modelli di incorporamento possono convertire le voci di log in vettori e il clustering di questi vettori può raggruppare automaticamente modelli di guasto simili. Ad esempio, il framework "HELP" raggruppa i log di sistema in streaming in base ai loro incorporamenti per individuare modelli di log ricorrenti. In aviazione, un clustering analogo potrebbe identificare modalità di guasto comuni o categorizzare voci di manutenzione non programmata senza etichette predefinite, consentendo l'analisi di problemi frequenti (ad esempio, raggruppando insieme incidenti di "vibrazioni anomale"). Questo raggruppamento semantico non supervisionato facilita l'analisi delle tendenze e la previsione del carico di lavoro.
Recupero Conversazionale (RAG): gli incorporamenti sono alla base dei sistemi di Generazione Aumentata del Recupero (RAG) che alimentano i chatbot sui documenti. Un esempio di chatbot PDF ne mostra l'architettura: estrae il testo dai manuali, lo suddivide in blocchi, incorpora ogni blocco e lo memorizza in un archivio vettoriale (come FAISS). In fase di esecuzione, ogni query dell'utente viene incorporata e utilizzata per recuperare i primi k blocchi rilevanti tramite l'indice vettoriale. Questi blocchi costituiscono il contesto per un LLM che risponde alla domanda. In ambito aeronautico, una pipeline RAG consente a un tecnico di "chattare" con il gemello digitale dell'aereo: ad esempio, chiedendo "Qual è la procedura per sostituire l'interruttore termico del tubo di Pitot?" e ottenendo una risposta precisa ricavata dai manuali OEM.
Indicizzazione predittiva dei guasti: i registri di manutenzione storici descrivono guasti e relative riparazioni. È possibile indicizzare le descrizioni dei guasti come vettori in modo che la descrizione di un nuovo incidente venga abbinata a casi precedenti simili. La ricerca sulla manutenzione predittiva ha scoperto che il calcolo della similarità semantica del testo del guasto utilizzando le tacche di trasformazione (con similarità coseno o di Pearson) raggruppa con successo i guasti correlati. In pratica, quando un meccanico registra una nuova descrizione di guasto, il sistema potrebbe recuperare incidenti passati con un'elevata similarità di tacche per suggerire probabili cause profonde o controlli, "prevedendo" efficacemente in base alla prossimità nello spazio di tacche.
Considerazioni pratiche sulla progettazione
Dimensionalità dell'embedding: gli embedding a più dimensioni catturano più sfumature, ma sono più costosi in termini di archiviazione e calcolo. Le scelte comuni sono 768, 1024, 1536 o 3072 dimensioni. Ad esempio, i modelli più grandi di OpenAI utilizzano dimensioni 1536–3072, mentre l'E5/GTE base di Meta utilizza 768 o 1024. In un esperimento pilota, l'indicizzazione dello stesso corpus ha richiesto 2,4 volte più tempo con embedding 1536D rispetto a 768D. Pertanto, se la produttività e la latenza sono critiche (ad esempio, filtraggio sul dispositivo di centinaia di query al secondo), 768D o 1024D potrebbero essere sufficienti. Se l'obiettivo è il massimo richiamo (e l'hardware lo consente), dimensioni maggiori sono accettabili. Per l'aviazione, si potrebbe iniziare con 1024D (bilanciato) e testare modelli più piccoli rispetto a quelli più grandi su attività di recupero nei dati di dominio.
Metrica della distanza: la scelta tra coseno (o prodotto scalare normalizzato) e euclidea grezza dipende dall'immersione. La maggior parte delle immersioni di testo moderne viene confrontata tramite similarità del coseno. Ad esempio, Tekgöz et al. hanno scoperto che le metriche coseno/Pearson fornivano la migliore similarità per le descrizioni di errore. Redis e altri supportano la specifica esplicita di "COSINO" (normalizzando i vettori dietro le quinte), mentre molti sistemi utilizzano il prodotto interno su vettori pre-normalizzati. In pratica, coseno e prodotto interno sono equivalenti se le immersioni sono normalizzate. La distanza euclidea è meno comune per il testo, ma concettualmente simile quando i vettori si trovano su una sfera. Raccomandazione: utilizzare il coseno per le immersioni basate su testo.
Metadati e strutturazione ibrida: è importante memorizzare gli embedding vettoriali insieme ai metadati strutturati (modello dell'aeromobile, capitolo ATA, data, codice componente, ecc.) per una ricerca più precisa. Tutti gli archivi vettoriali moderni consentono di associare metadati a ciascun vettore. Ad esempio, i set di vettori Redis consentono di filtrare per attributi JSON nella stessa query (ad esempio WHERE aircraft_model = 'A320' AND ATA = '21'). Qdrant offre un potente filtro booleano per restringere i risultati dei vettori in base ai metadati. Durante la progettazione dello schema, definire i campi dei metadati (ad esempio modello, ata, data, codice componente) e indicizzarli normalmente contrassegnando il campo di testo come VETTORE. Nelle query ibride, il sistema applica prima il filtro dei metadati (o lo combina tramite una penalità di punteggio) e quindi cerca solo nel sottoinsieme i vicini più prossimi, migliorando la precisione. Assicurarsi che i filtri critici (ad esempio numero di coda dell'aeromobile o intervallo di tempo) siano su campi scalari indicizzati per sfruttare il filtraggio del DB.
Ottimizzazione di latenza e throughput: i parametri dell'indice ANN dovrebbero essere ottimizzati per la latenza target. Per HNSW, l'aumento del parametro efSearch produce un recall più elevato ma aumenta linearmente il tempo di query. Un approccio pratico consiste nel confrontare recall e latenza su un set trattenuto: iniziare con un ef basso per la velocità, quindi incrementare fino al plateau di recall. Weaviate supporta persino un "ef dinamico" che scala ef con il conteggio dei risultati desiderato. Per i carichi di lavoro batch, è possibile utilizzare indici FLAT (esatti) per massimizzare l'accuratezza, mentre per query in tempo reale di decine di millisecondi, HNSW o IVF con parametri ottimizzati sono migliori. La quantizzazione (8 bit, quantizzazione del prodotto) è un'altra leva: ad esempio, le impostazioni Q8 vs BIN di Redis riducono drasticamente la memoria e accelerano la ricerca, a scapito di un leggero calo dell'accuratezza.
Aggiornamenti dell'indice: se i dati cambiano frequentemente (nuove voci di log o aggiornamenti manuali), scegli sistemi che supportano l'indicizzazione dinamica. L'implementazione HNSW di Redis consente inserimenti ed eliminazioni al volo senza ricostruire l'indice. Weaviate può aggiornare HNSW in modo asincrono (quindi le scritture non bloccano le letture). Altri sistemi, come FAISS, richiedono in genere una reindicizzazione, quindi utilizzali per corpora prevalentemente statici. Pianifica la reindicizzazione se arrivano nuovi manuali o se è necessario aggiungere log giornalieri. In molti sistemi aeronautici, i manuali cambiano lentamente ma arrivano log/voci di dispatch giornalieri, quindi approcci ibridi (scrivere nuovi vettori su un indice "caldo" per un giorno e unirli ogni notte) possono funzionare.
Riepilogo
Database vettoriali e modelli di embedding consentono, insieme, una ricca intelligenza semantica sui dati aeronautici. Gli embedding di alta qualità (ad esempio, i modelli 768–3072D) traducono manuali, log e descrizioni di componenti in vettori ricercabili, mentre gli archivi di vettori specializzati (Redis, Pinecone, Weaviate, Qdrant, Vespa, FAISS, Milvus) forniscono gli indici ANN e il filtro necessari su larga scala. La tabella sopra confronta le caratteristiche principali: Redis e Qdrant eccellono nella bassa latenza con filtro; Pinecone e Milvus brillano su larga scala; Weaviate e Vespa supportano query ibride (grafo+vettore); FAISS offre prestazioni ottimali per pipeline personalizzate. Le scelte di embedding (modello, dimensione, normalizzazione) e l'ottimizzazione degli indici (parametri HNSW, quantizzazione) devono essere bilanciate tra richiamo e velocità. Insieme, queste tecnologie consentono ai team di machine learning aeronautico di sviluppare strumenti avanzati (interfacce utente di ricerca semantica, chatbot di manutenzione, analisi predittiva) che convertono log e manuali non strutturati in informazioni fruibili.
Tendenze nella manutenzione aeronautica che potrebbero acquisire slancio in circostanze incerte
Gli aerei rimangono in servizio più a lungo, le catene di approvvigionamento sono una polveriera e la tecnologia si evolve da un giorno all'altro. Scopri le tendenze di manutenzione che stanno prendendo piede e cosa significano per gli operatori che cercano di rimanere operativi e redditizi.

April 10, 2026
Mission Control: infrastruttura di intelligence ad alte prestazioni per decisioni mission‑critical alla massima velocità
Ogni leader con cui parlo, che sia nell’aerospazio, nella manifattura o nell’edilizia, mi dice la stessa cosa:
I nostri sistemi stanno diventando sempre più intelligenti, ma le nostre decisioni non stanno diventando più rapide o più sicure al ritmo richiesto dalle operazioni.
Nei contesti ad alta integrità, lo spazio tra dati e decisioni è il punto in cui il rischio si accumula. Man mano che le operazioni diventano più complesse, distribuite e sensibili al fattore tempo, le organizzazioni hanno bisogno di sistemi di intelligence non solo rapidi ma anche verificabili, deterministici e sicuri per progettazione.
Questa è la filosofia ingegneristica alla base di Mission Control, la nostra infrastruttura di intelligence ad alte prestazioni, progettata per una velocità decisionale in tempo reale, verificabile e crittograficamente sicura.

October 2, 2025
Scelta delle parti giuste dell'aeromobile con analisi della tolleranza ai danni
Il futuro della sicurezza aerea è tutto nei componenti. Componenti autentici e tracciabili garantiscono alle flotte la massima tolleranza ai danni e prestazioni ottimali, per la massima sicurezza ed efficienza negli approvvigionamenti.

September 30, 2025
Come entrare in nuovi mercati dell'aviazione: la guida completa per i fornitori di componenti
Vuoi entrare in nuovi mercati dell'aviazione? Scopri come i fornitori possono analizzare la domanda, gestire i componenti PMA e costruire la fiducia delle compagnie aeree. Una guida completa per la crescita globale.

