AIによるインサイトを行動へとつなげる
Vector DB。航空業界の非構造化インテリジェンスを解き放つ。
7月 05, 2025
ベクターデータベースは、高次元の埋め込みベクトルにインデックスを付けて、非構造化データに対するセマンティック検索を可能にします。これは、キーワードの完全一致を使用する従来のリレーショナルストアやドキュメントストアとは異なります。テーブルやドキュメントの代わりに、ベクターストアはテキストまたは画像のセマンティクスを表す高密度の数値ベクトル (多くの場合 768~3072 次元) を管理します。クエリ時に、データベースは近似最近傍 (ANN) 検索アルゴリズムを使用して、クエリベクトルに最も近いものを検索します。たとえば、階層型ナビゲート可能スモールワールド (HNSW) などのグラフベースのインデックスは、粗い検索用の小さな最上位層と、絞り込み用の大きな下位層という階層化された近接グラフを構築します (下の図を参照)。検索はこれらの層を「ホップ」して下降し、ローカルな近傍を徹底的に検索する前にクラスターにすばやくローカライズします。これにより、再現率 (真の最近傍の検索) とレイテンシがトレードオフされます。つまり、HNSW 検索パラメータ (efSearch) を上げると、再現率は上がりますが、クエリ時間は長くなります。
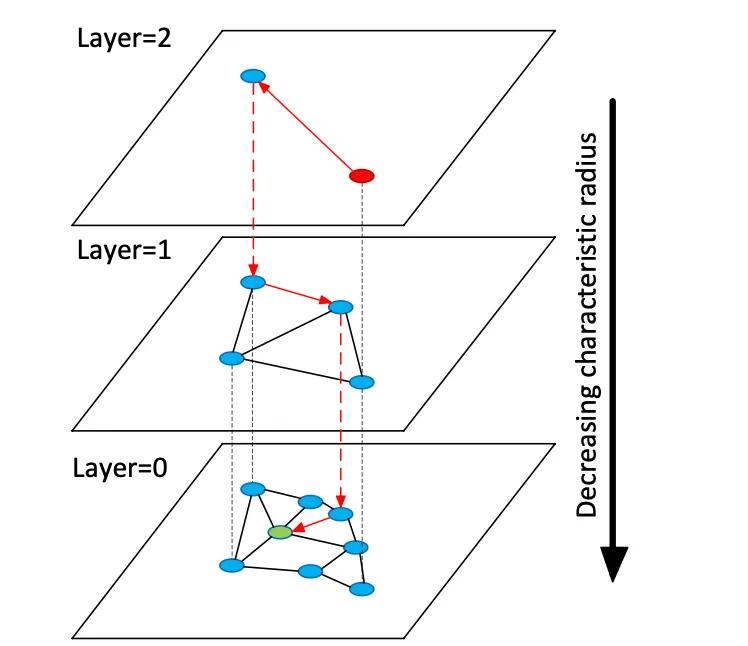
図: HNSW ANN 検索グラフ – ベクトルはレイヤーに編成され、最近傍クエリを高速化します (Devmy の Redis Vector Sets の説明より引用)。
リレーショナル テーブルでの完全一致検索とは異なり、ベクトル検索では意味を捉えることができます。つまり、クエリでは、キーワードの完全一致だけでなく、意味的に類似したアイテムが検索されます。航空データ (マニュアルや修理ログなど) の場合、これは技術者が表現が異なっていても関連コンテンツを取得できることを意味します。ベクトル距離 (コサイン、ドット積、ユークリッド) は類似性を定量化します。埋め込みを正規化すると、コサイン類似度とドット積は同等のランキングを生成します。実際には、ベクトルを正規化し、コサイン類似度を関連性メトリックとして使用するのが一般的です。主なトレードオフには、リコールとレイテンシがあります。インデックスが大きく、検索パラメータが高いほどリコールは向上しますが、レイテンシが増加します。ベクトル DB は、速度と精度のバランスをとるために調整可能なインデックス (HNSW、IVF、フラット スキャン) を提供します。
埋め込みモデル
最新の埋め込みモデルは、テキスト(またはその他のデータ)をベクトルに変換します。主要なモデルには、OpenAI の text-embedding-3-large、Cohere の embedded-multilingual-v3、Google の Gemini/BGE モデル、Meta の E5 および GTE ファミリー、多くの HuggingFace モデル(例: Sentence-BERT バリアント)などがあります。これらのモデルは、次元数、データ カバレッジ、推論コストが異なります。たとえば、OpenAI の text-embedding-3-large は 3072 次元のベクトルを生成しますが、これは以前の Ada-002 (1536D) よりも大幅に大きいです。Cohere の v3 モデルは通常、1024D (英語または多言語) 以下 (例: 384D「ライト」バージョン) を出力します。Meta の E5-large と GTE-large も 1024D の埋め込みを生成しますが、その基本または「小さい」バリアントは 768D または 384D を生成します。 GoogleのVertex-AI埋め込みには、768次元のテキストモデルと3072次元の「gemini-embedding-001」大規模モデルが含まれています。一般的に、次元数が多いほどセマンティック忠実度は向上しますが、より多くのストレージと計算量が必要になります。あるベンチマークでは、e5-base(768次元)はada-002(1536次元)よりも2倍以上高速にデータセットをインデックスしました。
埋め込みモデルは、トレーニング データと多言語性によっても異なります。OpenAI と Cohere の埋め込み API はプロプライエタリ (関連するコストと使用制限あり) ですが、Meta の E5/GTE と多くの HuggingFace モデルはオープンソース (Apache ライセンス) です。E5 および GTE モデルは 50 以上の言語をサポートしており、Cohere の multilingual-v3 モデルも同様です。この多言語対応は、国際的な航空文書にとって貴重です。ドメイン適応は、専門的な語彙 (ATA 章言語、部品命名法など) にとって重要です。これらのモデルは、すぐに使用できる状態で、Web テキストと一般的なコーパスでトレーニングされているため、航空専門用語を完全にはキャプチャできない可能性があります。チームは、メンテナンス ログまたはマニュアルで微調整するか、アダプターを使用することを検討する必要があります。実際には、エンタープライズ システムは強力な一般的な埋め込み (OpenAI や E5 など) から始めて、ドメイン固有のテキストで微調整することがよくあります。
パフォーマンスの観点から見ると、モデルのレイテンシは異なります。小規模なモデル(例:E5-base-768)は推論が高速ですが、大規模な独自モデル(OpenAIの3072D)は低速で、一度に1つのリクエストしか許可しない場合があります。オンプレミスのハードウェアが限られている場合は、より小規模なモデルや量子化されたモデルを使用できます。ライセンスは重要です。OpenAIとCohereはリクエストごとに課金され、使用ポリシーがありますが、E5 / GTEやGoogleのBGE(クォータ付きでVertexAI経由でオープン)などのオープンモデルはAPIコストを回避します。要約すると、どのベクトルDBでもこれらのモデルから埋め込みを取り込むことができますが、アーキテクトは航空データのモデルを選択する際に、埋め込みの次元、コスト、多言語サポート、およびドメイン適合性を比較検討する必要があります。
ベクターデータベースの種類
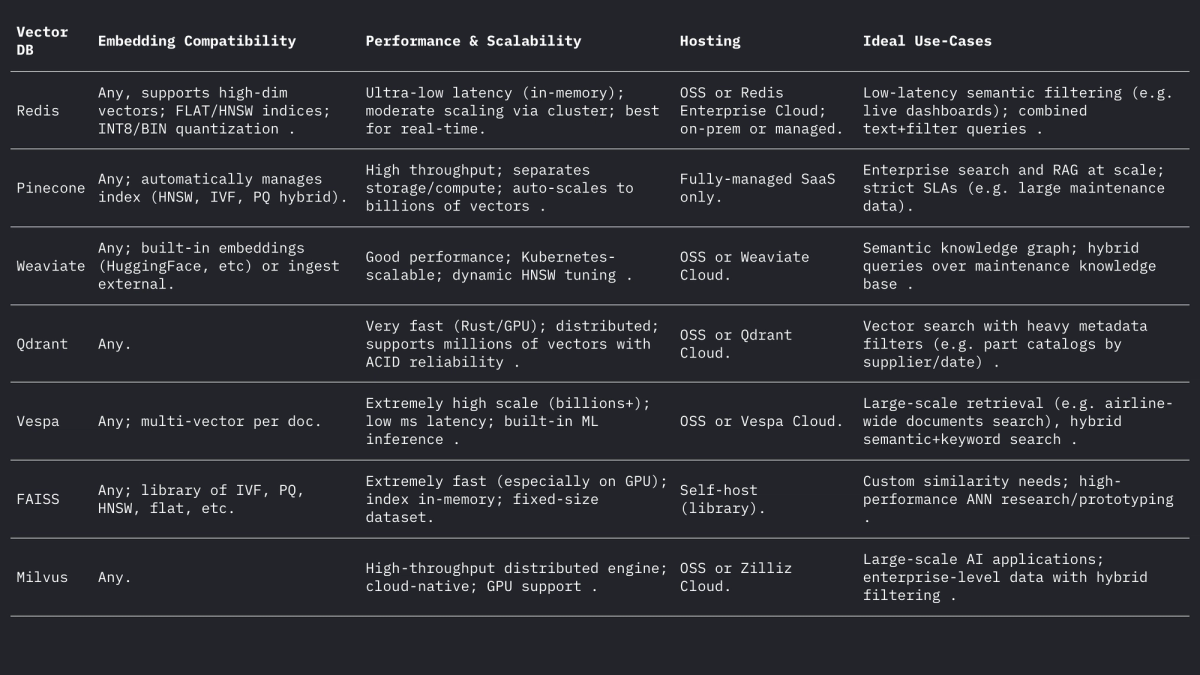
軽量ライブラリから本格的なプラットフォームまで、さまざまなベクター データベース システムが存在します。
- Redis (ベクトルセット) – Redis は、ベクトルインデックスモジュールを備えたインメモリのキーバリューストアです。FLAT (正確なブルートフォース) インデックスと HNSW インデックスをサポートしています。Redis ベクトルセットは、独自の動的更新を可能にします。HNSW グラフは双方向に維持されるため、ベクトルをオンザフライで追加または削除でき、その効果は即時に反映されます。Redis は量子化 (8 ビットまたはバイナリ) をサポートしており、精度の低下を最小限に抑えながらメモリを削減します (最大 4 ~ 32 倍)。また、ハイブリッドフィルタリングも提供しており、ベクトルをテキストタグや数値フィールドと一緒に保存し、同じクエリでフィルタリング (例: .year > 2020) できます。インメモリエンジンとして、Redis は RAM 使用量を犠牲にして超低レイテンシを実現します。クラスタリングにより水平方向に拡張できますが、クラスターのサイズは通常、専用のベクトルプラットフォームよりも小さくなります。Redis はオープンソースとして、または Redis Enterprise Cloud を通じて利用できます。
- Pinecone – フルマネージドのベクトル検索クラウドサービス。Pineconeはすべてのインフラストラクチャを抽象化します。ストレージとコンピューティングを分離し、高速なクエリ時間を維持しながら数十億のベクトルに拡張できます。最適なパフォーマンスを実現するために、HNSW、IVF、PQなどを混在させたインデックスを内部で自動管理します。トレードオフはコストと透明性です。Pineconeは使いやすく(オペレーターは不要)、OSSよりも高価です。高スループットとSLAバウンドのワークロードに優れ、ハイブリッド(キーワード+ベクトル)クエリとエンタープライズ機能をサポートします。Pineconeは、サーバー管理なしでエンタープライズグレードのスケーラビリティと信頼性を必要とするチームに最適です。
- Weaviate – オープンソースのグラフ中心のベクターDB(マネージドサービスとしても提供)。Weaviateでは、ベクターに加えて、豊富なスキーマとナレッジグラフ構造化が可能です。GraphQL APIを提供して、セマンティックベクター検索と従来のクエリ(ハイブリッド検索)を組み合わせたり、GraphQL APIを使用したりできます。Weaviateは主にHNSWインデックスを使用します(小規模なデータセットにはフラットインデックスも使用できます)。検索パラメータを自動的に調整したり、スループットを向上させるために非同期インデックス作成を可能にしたりします。ディープラーニング用のモジュールを使用すると、Weaviateはベクターを生成することもできます(例:HuggingFaceモデル経由)。Kubernetesとクラウドまたはオンプレミスのクラスターを介して拡張できます。Weaviateの強みは、ハイブリッドなセマンティック+シンボリック検索とデータモデリングの柔軟性です。関係性(例:部品と航空機の階層)がベクターの類似性と同じくらい重要な場合に適しています。
- Qdrant – Rustで書かれたオープンソースのベクトル検索エンジンです。Qdrantは、豊富なメタデータフィルタリング機能を備えた高性能なANNインデックスを提供します。動的オートスケーリング機能を備えたHNSWインデックスをサポートし、HTTP APIも提供しています。特に、Qdrantは厳格なフィルタリングと信頼性を重視しており、分散デプロイメント、ACIDトランザクション、GPUアクセラレーションをサポートしています。大規模なデータセットでも優れたパフォーマンスを発揮し、高い再現率を実現します。Qdrant Cloudはデプロイメントを簡素化するだけでなく、セルフホスト型でも同様に堅牢です。そのため、ベクトル類似度と構造化フィルター(例:特定の航空機モデルや日付範囲のみの検索)を組み合わせたい場合、Qdrantは最適な選択肢となります。
- Vespa – Yahoo 発のオープンソースの検索および分析エンジンです。Vespa は、ベクトル検索と従来の転置インデックス検索を独自に統合しています。数十億のベクトルを極めて高いスループットで処理でき、このプラットフォームは膨大なデータに対して 100 ミリ秒未満のレイテンシで数千 QPS をサポートすると謳っています。Vespa はドキュメントごとにマルチベクトルとハイブリッド検索 (セマンティック + キーワード) をサポートしています。ANN インデックスには HNSW (および転置ファイル フィルタリングを組み合わせた HNSW-IF などの新しいバリアント) が含まれます。完全なアプリケーション サーバーとして、Vespa はカスタム ランキング モデルと ML 推論パイプラインもサポートしています。そのため、規模とハイブリッドな関連性が求められる大規模でミッション クリティカルな検索アプリケーション (航空会社全体の検索ポータルなど) に適しています。Vespa は自己管理することも、Vespa Cloud 経由で使用することもできます。
- FAISS – Metaによる類似性検索のための研究レベルのライブラリ。FAISSはスタンドアロンのデータベースではなく、CPU/GPUで実行される高度に最適化されたインデックス(Flat、IVF、PQ、HNSWなど)のコレクションです。並外れた速度(特にGPU使用時)と柔軟性を実現し、ほぼすべての距離メトリックやインデックス作成方法を使用できます。ただし、FAISSにはストレージ/クエリエンジンやメタデータフィルタリングが含まれていないため、独自のシステムに統合する必要があります。最高のパフォーマンスとインデックス作成アルゴリズムの制御が必要な場合に最適です。たとえば、FAISSは、再現率と速度が最も重要で、データサイズが固定されているコンピュータービジョンやMLの研究で広く使用されています。航空分野では、FAISSは非常に高次元の埋め込み(画像ベースの部品認識など)用のカスタム検索ツールの基盤となる可能性がありますが、周囲のアーキテクチャが必要です。
- Milvus – 大規模ワークロード向けに設計された、人気の高いオープンソースのベクトルデータベースです。Milvusはスタンドアロンモードと分散モードの両方を提供し、数十億のベクトルを強力な一貫性でサポートします。複数のインデックスタイプ(HNSW、IVF、Annoyなど)とメトリクス(コサイン、L2など)に加え、スカラーフィルタリングによるハイブリッド検索も提供します。MilvusはGPUアクセラレーション対応でクラウドネイティブ(Kubernetesと統合)です。スナップショットや暗号化などのエンタープライズ機能を備え、Zillizによって積極的に開発されています。Milvusのアーキテクチャはスケーラビリティとパフォーマンスを重視して構築されており、膨大なマニュアルやセンサーログのアーカイブ分析など、データ集約型のアプリケーションに最適です。Zillizは、マネージドホスティングとしてMilvus Cloudも提供しています。
これらのシステムはそれぞれベクトルとフィルターの扱い方が異なりますが、いずれもL2、内積(ドット)、コサイン距離(多くの場合、正規化されたベクトルを保存することで)をサポートしています。Weaviateのフォーラムでは、Weaviateは最大65535次元のベクトルを保存できると述べられており、これは一般的な埋め込みサイズをはるかに上回っており、現代のエンジンの柔軟性を示しています。まとめ:
航空業界におけるユースケース
セマンティック検索:航空機整備には、膨大なマニュアル、整備速報、規制文書が関わってきます。ベクター検索システムを利用することで、エンジニアは自然言語(あるいは音声)によるクエリを入力し、意味的に関連性の高い文章や文書を検索できます。例えば、「エンジンオイル漏れ」というキーワード検索の代わりに、埋め込み検索を使えば、文脈的に類似する「油圧液漏れ」に関する速報文を見つけることができます。Infosys/AWSが実証したように、各技術文書をベクターとして保存することで、LLMベースのエージェントはリポジトリから最も関連性の高い文書を検索し、整備に関するクエリに回答できます。
あいまい部品マッチング:航空機部品には、ベンダーごとに異なる難解な識別子(NSNまたは部品番号)と説明的な名称が付けられていることがよくあります。部品説明、あるいは部品番号(テキストとして扱われる)のベクトル埋め込みにより、ルールベースのマッチングでは見逃される、ほぼ重複した部品が見つかる可能性があります。他の分野では、単語埋め込みを用いて名称を意味的にあいまい一致させる手法が用いられてきました。同様に、部品記述子の埋め込みにより、スペルやコードが異なっていても、サプライヤーカタログ間で部品を最も近い説明と一致させることができます。これにより、複数のソースからの在庫を統合することが可能になります。
ログの分類とクラスタリング:修理ログや障害ログは通常、自由形式のテキストです。埋め込みモデルはログエントリをベクトルに変換し、これらのベクトルをクラスタリングすることで、類似の障害パターンを自動的にグループ化できます。例えば、「HELP」フレームワークは、ストリーミングシステムログを埋め込みに基づいてクラスタリングし、繰り返し発生するログテンプレートを検出します。航空業界では、同様のクラスタリングによって、一般的な故障モードを特定したり、事前定義されたラベルを使用せずに予定外のメンテナンスエントリを分類したりすることで、頻繁な問題に関する分析が可能になります(例:「異常振動」インシデントをまとめてクラスタリングする)。この教師なしセマンティックグループ化は、傾向分析やワークロード予測に役立ちます。
会話型検索(RAG):埋め込みは、ドキュメント上でチャットボットを動かす検索拡張生成(RAG)システムの基盤となっています。PDFチャットボットの例は、マニュアルからテキストを抽出し、チャンク化し、各チャンクを埋め込み、ベクトルストア(FAISSなど)に保存するというアーキテクチャを示しています。実行時に、各ユーザークエリが埋め込まれ、ベクトルインデックスを介して上位k個の関連チャンクを取得するために使用されます。これらのチャンクは、LLMが質問に答えるためのコンテキストを形成します。航空業界では、RAGパイプラインにより、技術者は航空機のデジタルツインと「チャット」することができます。例えば、「ピトー管ヒートスイッチの交換手順は?」と質問すると、OEMマニュアルから正確な回答を得ることができます。
予測的故障インデックス作成:過去のメンテナンス記録には、故障とその修正内容が記録されています。故障の説明をベクトルとしてインデックス付けすることで、新しいインシデントの説明を過去の類似事例と照合することができます。予測メンテナンスの研究では、トランスフォーマー埋め込み(コサイン類似度またはピアソン類似度を使用)を用いて故障テキストの意味的類似性を計算することで、関連する故障を効果的にグループ化できることが分かっています。実際には、整備士が新しい故障の説明を記録すると、システムは埋め込み類似度の高い過去のインシデントを検索し、考えられる根本原因やチェック項目を提案することで、埋め込み空間における近接性に基づいて効果的に「予測」することができます。
実用的な設計上の考慮事項
埋め込み次元: 高次元の埋め込みはより多くのニュアンスを捉えますが、ストレージと計算のコストが高くなります。一般的な選択肢は 768、1024、1536、または 3072 次元です。たとえば、OpenAI の大規模モデルは 1536~3072 次元を使用しますが、Meta の基本 E5/GTE は 768 または 1024 を使用します。パイロット実験では、同じコーパスのインデックス作成に、768D よりも 1536D の埋め込みで 2.4 倍の時間がかかりました。したがって、スループットとレイテンシが重要な場合 (例: 数百クエリ/秒のデバイス内フィルタリング)、768D または 1024D で十分な場合があります。最大の再現率が目標であり (ハードウェアが許す場合)、より大きな次元でも許容されます。航空業界では、1024D (バランス) から始めて、ドメイン データの検索タスクで小さいモデルと大きいモデルをテストする場合があります。
距離メトリクス:コサイン(または正規化されたドット積)と生のユークリッドのどちらを選択するかは、埋め込み方法によって異なります。最近のテキスト埋め込みのほとんどは、コサイン類似度によって比較されます。たとえば、Tekgöz らは、コサイン/ピアソンメトリクスが障害の説明に対して最良の類似度を与えることを発見しました。Redis などは、明示的に「COSINE」を指定することをサポートしています(バックグラウンドでベクトルを正規化します)。一方、多くのシステムでは、事前に正規化されたベクトルに対して内積を使用します。実際には、埋め込みが正規化されている場合、コサインと内積は同等です。ユークリッド距離はテキストではあまり一般的ではありませんが、ベクトルが球面上にある場合は概念的に同様です。推奨事項:テキストベースの埋め込みにはコサインを使用します。
メタデータとハイブリッド構造化: 絞り込み検索を行うには、構造化メタデータ (航空機モデル、ATA チャプター、日付、部品番号など) と一緒にベクター埋め込みを保存することが重要です。すべての最新のベクター ストアでは、各ベクターにメタデータを添付できます。たとえば、Redis Vector Sets を使用すると、同じクエリ (例: WHERE aircraft_model = 'A320' AND ATA = '21') で JSON 属性でフィルタリングできます。Qdrant は、メタデータでベクターの結果を絞り込むための強力なブールフィルタリングを提供します。スキーマを設計するときは、メタデータ フィールド (例: model、ata、date、part_no) を定義し、通常どおりインデックスを作成し、テキスト フィールドをベクターとしてマークします。ハイブリッド クエリでは、システムは最初にメタデータ フィルターを適用し (またはスコア ペナルティを介して組み合わせ)、次にサブセットのみで最近傍を検索して精度を向上させます。DB フィルタリングを活用するには、重要なフィルター (例: 航空機の機体番号や時間範囲) がインデックス付きのスカラー フィールドにあることを確認してください。
レイテンシとスループットのチューニング: ANN インデックス パラメータは、ターゲット レイテンシに合わせてチューニングする必要があります。HNSW の場合、efSearch パラメータを上げるとリコールは高くなりますが、クエリ時間は直線的に増加します。実用的なアプローチは、ホールドアウト セットでリコールとレイテンシをベンチマークすることです。速度を上げるために低い ef から始めて、リコールが横ばいになるまで増やします。Weaviate は、必要な結果数に合わせて ef をスケーリングする「動的 ef」もサポートしています。バッチ ワークロードの場合、FLAT インデックス (正確) を使用して精度を最大化できますが、リアルタイムの数十ミリ秒のクエリの場合は、チューニングされたパラメータを使用した HNSW または IVF の方が適しています。量子化 (8 ビット、積量子化) も別の手段です。たとえば、Redis の Q8 設定と BIN 設定を比較すると、メモリが大幅に削減され、検索が高速化されますが、精度がわずかに低下します。
インデックス更新:データが頻繁に変更される場合(新しいログエントリや手動更新など)、動的インデックスをサポートするシステムを選択してください。Redis の HNSW 実装では、インデックスを再構築することなく、オンザフライで挿入と削除が可能です。Weaviate は HNSW を非同期的に更新できます(書き込みによって読み取りがブロックされないため)。FAISS などの他のシステムは通常、再インデックスを必要とするため、ほぼ静的なコーパスに使用してください。新しいマニュアルが届いた場合や日次ログを追加する必要がある場合は、再インデックスを計画してください。多くの航空システムでは、マニュアルの変更は遅いですが、日次ログ/ディスパッチエントリは届くため、ハイブリッドアプローチ(新しいベクトルを 1 日だけ「ホット」インデックスに書き込み、夜間にマージする)が機能します。
まとめ
ベクターデータベースと埋め込みモデルを組み合わせることで、航空データに関する豊富なセマンティックインテリジェンスを実現できます。高品質な埋め込み(例:768~3072Dモデル)は、マニュアル、ログ、部品の説明を検索可能なベクターに変換します。一方、専用のベクターストア(Redis、Pinecone、Weaviate、Qdrant、Vespa、FAISS、Milvus)は、大規模なANNインデックスとフィルタリングを提供します。上の表は主要な機能を比較したものです。RedisとQdrantはフィルタリングによる低レイテンシに優れ、PineconeとMilvusは大規模に強みを発揮します。WeaviateとVespaはハイブリッド(グラフ+ベクター)クエリをサポートし、FAISSはカスタムパイプラインに究極のパフォーマンスを提供します。埋め込みの選択(モデル、次元、正規化)とインデックスチューニング(HNSWパラメータ、量子化)は、再現率と速度のバランスを取る必要があります。これらのテクノロジーを組み合わせることで、航空 ML チームは、構造化されていないログやマニュアルを実用的な洞察に変換する高度なツール (セマンティック検索 UI、メンテナンス チャットボット、予測分析) を構築できます。
不確実な状況下で勢いを増す可能性のある航空機整備のトレンド
航空機の運航期間が長くなり、サプライチェーンは火薬庫のように不安定になり、テクノロジーは急速に進化しています。勢いを増すメンテナンスのトレンドと、運航維持と収益確保を目指す運航事業者にとっての意味を探ります。

April 10, 2026
ミッションコントロール:ミッションクリティカルな意思決定スピードを実現する高性能インテリジェンス基盤
私が航空宇宙、製造業、建設業界で話をするどのリーダーも、口をそろえて同じことを言います。
私たちのシステムはどんどん賢くなっていますが、現場が求めるスピードに見合うほど、私たちの意思決定は速くも安全にもなっていません。
高い完全性が求められる環境では、データと意思決定の間にあるギャップこそがリスクの蓄積する場所になります。業務がより複雑に、分散的に、そして時間に敏感になるにつれて、組織には単に高速であるだけでなく、検証可能で決定論的、かつ設計段階からセキュアであるインテリジェンスシステムが必要になります。
これは、Mission Controlの背後にあるエンジニアリング哲学です。Mission Control は、リアルタイムで監査可能かつ暗号学的に安全な意思決定スピードを実現するために構築された、高性能なインテリジェンス基盤です。

October 2, 2025
損傷許容度解析による適切な航空機部品の選択
航空安全の未来は部品にかかっています。純正で追跡可能な部品は、航空機の損傷耐性と性能を最大限に高め、安全性と調達効率を最大限に高めます。

September 30, 2025
航空業界の新市場への参入方法:部品サプライヤーのための完全ガイド
新たな航空市場への参入をお考えですか?サプライヤーが需要分析、PMA部品の管理、そして航空会社との信頼関係構築を行う方法を学びましょう。グローバル成長のための完全ガイドです。

