Zet AI‑inzichten om in gerichte actie
Vector DB. Ontgrendel de ongestructureerde intelligentie van de luchtvaart.
juni 15, 2025
Vectordatabases indexeren hoogdimensionale embeddingvectoren om semantisch zoeken in ongestructureerde data mogelijk te maken, in tegenstelling tot traditionele relationele of documentopslag die exacte overeenkomsten op trefwoorden gebruiken. In plaats van tabellen of documenten beheren vectoropslagen dichte numerieke vectoren (vaak 768-3072 dimensies) die de semantiek van tekst of afbeeldingen representeren. Tijdens de query vindt de database de dichtstbijzijnde buren van een queryvector met behulp van approximatieve dichtstbijzijnde buur (ANN) zoekalgoritmen. Een grafiekgebaseerde index zoals Hierarchical Navigable Small Worlds (HNSW) construeert bijvoorbeeld gelaagde nabijheidsgrafieken: een kleine bovenste laag voor grof zoeken en grotere onderliggende lagen voor verfijning (zie onderstaande afbeelding). De zoekopdracht "springt" langs deze lagen omlaag en lokaliseert snel naar een cluster voordat de lokale buren uitgebreid worden doorzocht. Dit vormt een afweging tussen recall (het vinden van de echte dichtstbijzijnde buren) en latentie: het verhogen van de HNSW-zoekparameter (efSearch) verhoogt de recall ten koste van een hogere querytijd.
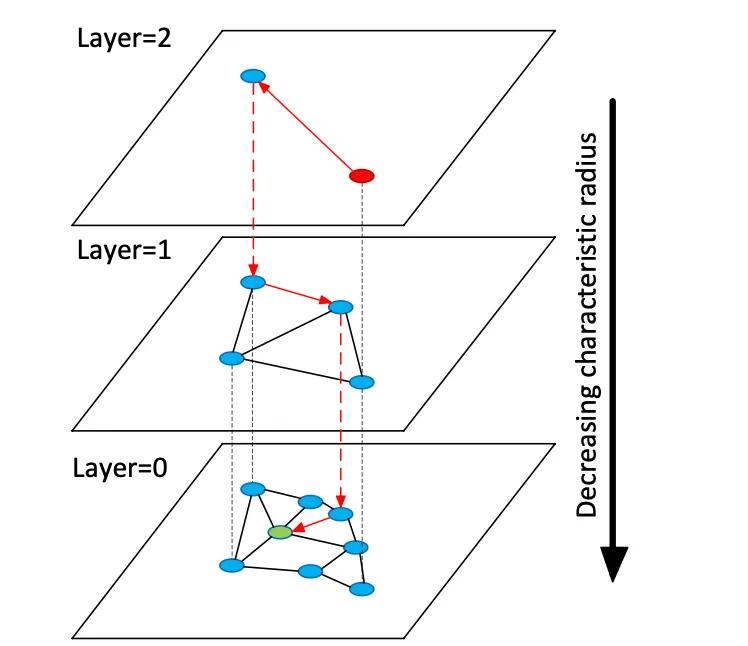
Figuur: HNSW ANN-zoekgrafiek – vectoren zijn georganiseerd in lagen om zoekopdrachten naar de dichtstbijzijnde buur te versnellen (bewerkt van Devmy's Redis Vector Sets-uitleg).
In tegenstelling tot exact zoeken in relationele tabellen kan vectorzoeken betekenis vastleggen: zoekopdrachten vinden semantisch vergelijkbare items, niet alleen exacte trefwoordmatches. Voor luchtvaartgegevens (bijv. handleidingen of reparatielogboeken) betekent dit dat technici relevante content kunnen ophalen, zelfs als de formulering verschilt. Vectorafstanden (cosinus, inwendig product of Euclidisch) kwantificeren gelijkenis. Wanneer embeddings genormaliseerd worden, leveren cosinusgelijkenis en inwendig product equivalente rankings op. In de praktijk normaliseert men vectoren vaak en gebruikt men cosinusgelijkenis als relevantiemaatstaf. Belangrijke afwegingen zijn recall versus latentie: grotere indices en hogere zoekparameters verbeteren recall, maar verhogen de latentie. Vectordatabases bieden instelbare indices (HNSW, IVF, flat scan) om snelheid versus nauwkeurigheid in evenwicht te brengen.
Inbeddingsmodellen
Moderne embeddingmodellen zetten tekst (of andere data) om in vectoren. Toonaangevende modellen zijn onder andere OpenAI's text-embedding-3-large, Cohere's embed-multilingual-v3, Google's Gemini/BGE-modellen, Meta's E5- en GTE-families en vele HuggingFace-modellen (bijv. Sentence-BERT-varianten). Deze modellen verschillen in dimensionaliteit, datadekking en inferentiekosten. OpenAI's text-embedding-3-large produceert bijvoorbeeld 3072-dimensionale vectoren, aanzienlijk groter dan de eerdere Ada-002 (1536D). Cohere's v3-modellen leveren doorgaans 1024D (Engels of meertalig) of kleiner (bijv. 384D "light"-versies). Meta's E5-large en GTE-large produceren ook 1024D embeddings, terwijl hun basis- of "kleine" varianten 768D of 384D opleveren. De Vertex-AI-embeddings van Google omvatten 768D-tekstmodellen en een groot "gemini-embedding-001"-model van 3072D. Over het algemeen verbeteren hogere dimensies vaak de semantische betrouwbaarheid, maar vereisen ze meer opslagruimte en rekenkracht: e5-base (768D) indexeerde een dataset meer dan 2× sneller dan ada-002 (1536D) in één benchmark.
Embedding-modellen variëren ook afhankelijk van trainingsdata en meertaligheid. De embedding-API's van OpenAI en Cohere zijn bedrijfseigen (met bijbehorende kosten en gebruikslimieten), terwijl Meta's E5/GTE en veel HuggingFace-modellen open-source zijn (met een Apache-licentie). E5- en GTE-modellen ondersteunen meer dan 50 talen, evenals Cohere's meertalige v3-modellen. Deze meertalige dekking is waardevol voor internationale luchtvaartdocumentatie. Domeinaanpassing is cruciaal voor gespecialiseerde vocabulaires (bijv. ATA-hoofdstuktaal, onderdeelnomenclatuur). Deze modellen worden standaard getraind op webtekst en algemene corpora; ze vatten luchtvaartjargon mogelijk niet perfect samen. Teams moeten overwegen om adapters te finetunen of te gebruiken op onderhoudslogboeken of handleidingen. In de praktijk beginnen bedrijfssystemen vaak met sterke algemene embeddings (zoals OpenAI of E5) en finetunen ze vervolgens op domeinspecifieke tekst.
Vanuit prestatieoogpunt variëren modellen in latentie. Kleinere modellen (bijv. E5-base-768) zijn sneller in inferentie, terwijl grote, propriëtaire modellen (OpenAI's 3072D) langzamer zijn en mogelijk slechts één verzoek tegelijk toestaan. Als on-premises hardware beperkt is, kunnen kleinere of gekwantiseerde modellen worden gebruikt. Licentie is belangrijk: OpenAI en Cohere rekenen kosten per verzoek en hebben een gebruiksbeleid, terwijl open modellen zoals E5/GTE of Google's BGE (open via VertexAI met quota) API-kosten vermijden. Kortom, elke vectordatabase kan embeddings van elk van deze modellen verwerken, maar architecten moeten bij het selecteren van modellen voor luchtvaartgegevens rekening houden met de dimensionaliteit van de embedding, kosten, meertalige ondersteuning en domeinfit.
Soorten vectordatabases
Er bestaat een breed scala aan vectordatabasesystemen, van eenvoudige bibliotheken tot volwaardige platforms:
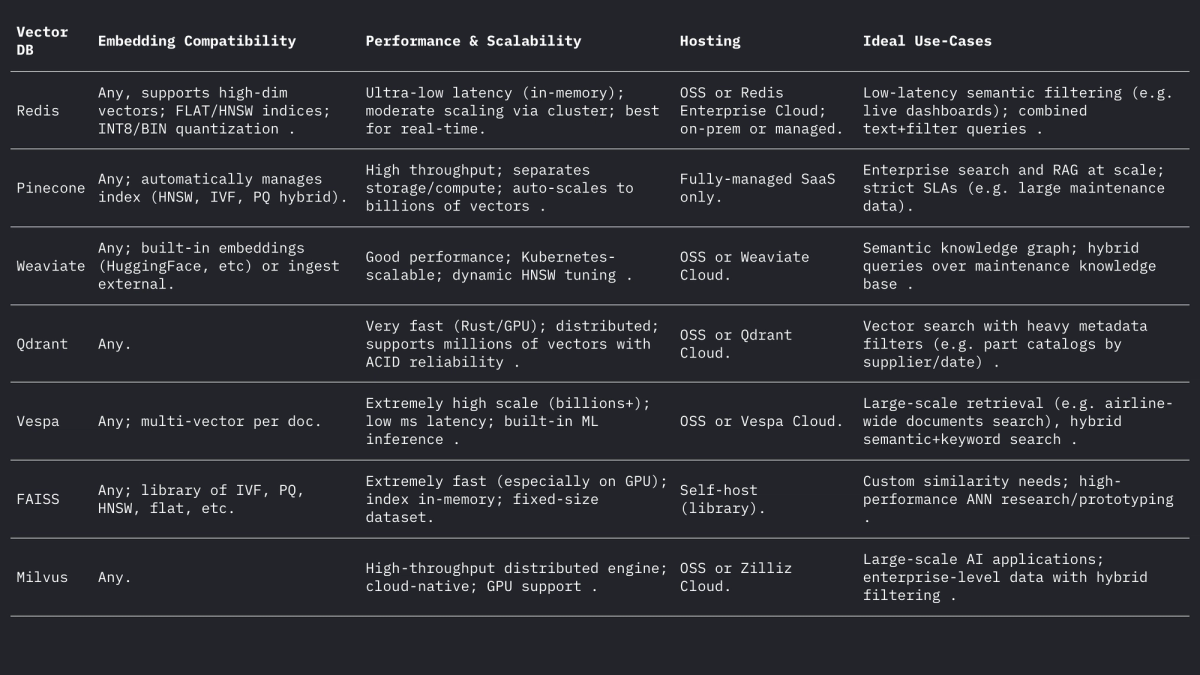
- Redis (Vector Sets) – Redis is een in-memory sleutel-waarde opslag met een vector index module. Het ondersteunt FLAT (exact brute-force) en HNSW indexen. Redis Vector Sets staan op unieke wijze dynamische updates toe: HNSW grafieken worden bidirectioneel onderhouden zodat vectoren direct en met onmiddellijke ingang kunnen worden toegevoegd of verwijderd. Redis ondersteunt kwantificering (8-bits of binair) om het geheugen te verkleinen (tot 4×–32×) met minimaal nauwkeurigheidsverlies. Het biedt ook hybride filtering: vectoren kunnen worden opgeslagen naast tekstlabels of numerieke velden en gefilterd (bijv. .year > 2020) in dezelfde query. Als in-memory engine levert Redis een ultralage latentie ten koste van RAM-gebruik. Het schaalt horizontaal via clustering, hoewel clustergroottes doorgaans kleiner zijn dan speciale vectorplatforms. Redis is beschikbaar als open-source of via Redis Enterprise Cloud.
- Pinecone – Een volledig beheerde cloudservice voor vectorzoekopdrachten. Pinecone abstraheert alle infrastructuur: het scheidt opslag van rekenkracht en schaalt naar miljarden vectoren, met behoud van snelle querytijden. Het beheert automatisch indexen onder de motorkap (een mix van HNSW, IVF, PQ, enz.) voor optimale prestaties. De afweging is kosten en ondoorzichtigheid: Pinecone is gebruiksvriendelijk (geen ops), maar duurder dan OSS. Het blinkt uit in hoge throughput en SLA-gebonden workloads, met ondersteuning voor hybride (trefwoord + vector) query's en enterprise-functionaliteit. Pinecone is ideaal voor teams die schaalbaarheid en betrouwbaarheid op enterprise-niveau nodig hebben zonder servers te beheren.
- Weaviate – Een open-source, grafiekgerichte vectordatabase (ook aangeboden als beheerde service). Weaviate maakt rijke schema- en kennisgrafiekstructurering naast vectoren mogelijk. Het biedt een GraphQL API om semantisch vectorzoeken te combineren met traditionele zoekopdrachten (hybride retrieval). Weaviate maakt voornamelijk gebruik van HNSW-indices (en kan een platte index gebruiken voor kleine datasets). Het past automatisch zoekparameters aan of staat asynchrone indexering toe voor throughput. Met modules voor deep learning kan Weaviate zelfs vectoren genereren (bijvoorbeeld via HuggingFace-modellen). Het schaalt via Kubernetes en cloud- of on-premise clusters. De sterke punten van Weaviate zijn hybride semantisch+symbolisch zoeken en flexibiliteit in datamodellering; het is geschikt wanneer relaties (bijvoorbeeld hiërarchieën tussen onderdelen en vliegtuigen) net zo belangrijk zijn als vectorgelijkenis.
- Qdrant – Een open-source vectorzoekmachine in Rust. Qdrant biedt een hoogwaardige ANN-index met uitgebreide metadatafiltering. Het ondersteunt HNSW-indexen met dynamische autoschaling en biedt een HTTP API. Qdrant legt met name de nadruk op strikte filtering en betrouwbaarheid – het ondersteunt gedistribueerde implementatie, ACID-transacties en GPU-versnelling. Het presteert zeer goed op grote datasets en levert een hoge recall op. Qdrant Cloud vereenvoudigt de implementatie, maar is even robuust als zelfgehoste zoekmachine. Dit maakt Qdrant een goede keuze wanneer u gecombineerde vectorgelijkenis en gestructureerde filters nodig hebt (bijvoorbeeld zoeken binnen bepaalde vliegtuigmodellen of datumbereiken).
- Vespa – Een open-source zoek- en analyse-engine, oorspronkelijk van Yahoo. Vespa integreert op unieke wijze vectorzoekopdrachten met klassieke omgekeerde-indexzoekopdrachten. Het kan miljarden vectoren verwerken met een extreme doorvoer: het platform adverteert met ondersteuning voor duizenden QPS met een latentie van <100 ms over enorme hoeveelheden data. Vespa ondersteunt multi-vector per document en hybride zoekopdrachten (semantisch + trefwoord). De ANN-indexering omvat HNSW (en nieuwe varianten zoals HNSW-IF die omgekeerde-bestandsfiltering combineren). Als volledige applicatieserver ondersteunt Vespa ook aangepaste rangschikkingsmodellen en ML-inferentiepijplijnen. Het is daarom zeer geschikt voor grootschalige, bedrijfskritische zoektoepassingen (bijv. zoekportalen voor luchtvaartmaatschappijen) waar schaal en hybride relevantie vereist zijn. Vespa kan zelf worden beheerd of worden gebruikt via Vespa Cloud.
- FAISS – Een bibliotheek van onderzoekskwaliteit van Meta voor gelijkenisonderzoek. FAISS is geen zelfstandige database, maar een verzameling zeer geoptimaliseerde indexen (Flat, IVF, PQ, HNSW, enz.) die draaien op CPU/GPU. Het bereikt uitzonderlijke snelheid (vooral met GPU's) en flexibiliteit: vrijwel elke afstandsmetriek of indexeringsmethode kan worden gebruikt. FAISS bevat echter geen opslag-/query-engine of metadatafiltering – u moet het integreren in uw eigen systeem. Het is het meest geschikt wanneer maximale prestaties en controle over indexeringsalgoritmen nodig zijn. FAISS wordt bijvoorbeeld veel gebruikt in computer vision en ML-onderzoek, waar recall en snelheid van cruciaal belang zijn en datagroottes vastliggen. In de luchtvaart zou FAISS de basis kunnen vormen voor een aangepaste zoektool voor zeer hoogdimensionale embeddings (bijv. beeldgebaseerde onderdeelherkenning), maar het vereist een omringende architectuur.
- Milvus – Een populaire open-source vectordatabase, ontworpen voor grootschalige workloads. Milvus biedt zowel standalone als gedistribueerde modi en ondersteunt miljarden vectoren met een sterke consistentie. Het biedt meerdere indextypen (HNSW, IVF, Annoy, enz.) en metrische gegevens (cosinus, L2, enz.), plus hybride zoekfunctionaliteit via scalaire filtering. Milvus is GPU-versneld en cloud-native (integreert met Kubernetes). Het bevat zakelijke functies zoals snapshots en encryptie en wordt actief ontwikkeld door Zilliz. De architectuur van Milvus is gebouwd voor schaalbaarheid en prestaties, waardoor het ideaal is voor data-intensieve applicaties zoals het analyseren van enorme archieven met handleidingen of sensorlogs. Zilliz biedt ook Milvus Cloud aan voor beheerde hosting.
Elk van deze systemen verwerkt vectoren en filters op een andere manier, maar ze ondersteunen allemaal L2, inwendig product (punt) en cosinusafstanden (vaak door genormaliseerde vectoren op te slaan). Het forum van Weaviate merkt op dat het zelfs vectoren tot 65535 dimensies kan opslaan, ver boven de gebruikelijke inbeddingsgroottes, wat de flexibiliteit van moderne engines aantoont. Samengevat:
Gebruiksscenario's in de luchtvaart
Semantisch zoeken: Vliegtuigonderhoud omvat enorme verzamelingen handleidingen, servicebulletins en regelgevingsdocumenten. Met een vectorzoeksysteem kunnen ingenieurs zoekopdrachten in natuurlijke taal (of zelfs gesproken zoekopdrachten) stellen en relevante passages of documenten semantisch terugvinden. In plaats van bijvoorbeeld te zoeken op trefwoorden zoals "motorolielek", kan een ingesloten zoekopdracht alinea's in bulletins vinden die "hydraulische vloeistoflek" beschrijven, mits contextueel vergelijkbaar. Zoals Infosys/AWS aantoonde, stelt het opslaan van elk technisch document als vectoren LLM-gestuurde agents in staat om onderhoudsvragen te beantwoorden door de meest relevante documenten uit de repository op te halen.
Fuzzy Part Matching: Luchtvaartonderdelen hebben vaak cryptische identificatiecodes (NSN of onderdeelnummers) en beschrijvende namen die per leverancier verschillen. Vector-embeddings van onderdeelbeschrijvingen of zelfs de onderdeelnummers (behandeld als tekst) kunnen bijna-duplicaten aan het licht brengen die regelgebaseerde matching over het hoofd ziet. In andere domeinen zijn woord-embeddings gebruikt om namen semantisch fuzzy te matchen; op dezelfde manier kunnen embeddings van onderdeelbeschrijvingen een onderdeel matchen met de dichtstbijzijnde beschrijving in leverancierscatalogi, zelfs als de spelling of codes verschillen. Dit kan de voorraad van meerdere bronnen samenvoegen.
Logclassificatie en -clustering: Reparatie- en storingslogs zijn meestal vrije tekst. Embedding-modellen kunnen loggegevens omzetten in vectoren, en clustering van deze vectoren kan automatisch vergelijkbare storingspatronen groeperen. Het "HELP"-framework clustert bijvoorbeeld streaming systeemlogs op basis van hun embeddings om terugkerende logsjablonen te ontdekken. In de luchtvaart kan analoge clustering veelvoorkomende storingsmodi identificeren of ongeplande onderhoudsgegevens categoriseren zonder vooraf gedefinieerde labels, wat analyses van frequente problemen mogelijk maakt (bijvoorbeeld het clusteren van incidenten met "vreemde trillingen"). Deze onbegeleide semantische groepering helpt bij trendanalyse en werklastvoorspelling.
Conversational Retrieval (RAG): Embeddings liggen ten grondslag aan Retrieval-Augmented Generation (RAG)-systemen die chatbots via documenten aansturen. Een voorbeeld van een PDF-chatbot laat de architectuur zien: tekst uit handleidingen extraheren, deze opdelen in stukken, elk fragment insluiten en opslaan in een vectorbestand (zoals FAISS). Tijdens runtime wordt elke gebruikersvraag ingebed en gebruikt om de top-k relevante fragmenten op te halen via de vectorindex. Deze fragmenten vormen de context voor een LLM om de vraag te beantwoorden. In de luchtvaart laat een RAG-pipeline een technicus 'chatten' met de digitale tweeling van het vliegtuig: bijvoorbeeld door te vragen: "Wat is de procedure voor het vervangen van de pitot-hitteschakelaar?" en een nauwkeurig antwoord te krijgen uit de OEM-handleidingen.
Voorspellende foutindexering: Historische onderhoudsgegevens beschrijven fouten en oplossingen. De foutbeschrijvingen kunnen als vectoren worden geïndexeerd, zodat de beschrijving van een nieuw incident wordt gekoppeld aan vergelijkbare eerdere gevallen. Onderzoek naar voorspellend onderhoud heeft aangetoond dat het berekenen van de semantische gelijkenis van fouttekst met behulp van transformer-embeddings (met cosinus- of Pearson-gelijkenis) gerelateerde fouten succesvol groepeert. In de praktijk, wanneer een monteur een nieuwe foutbeschrijving registreert, kan het systeem eerdere incidenten met een hoge embeddingsgelijkenis ophalen om waarschijnlijke hoofdoorzaken of controles te suggereren, en zo effectief te "voorspellen" op basis van nabijheid in de embeddingsruimte.
Praktische ontwerpoverwegingen
Embedding Dimensionaliteit: Hogere-dimensionale embeddings leggen meer nuance vast, maar kosten meer aan opslag en berekeningen. Veelvoorkomende keuzes zijn 768, 1024, 1536 of 3072 dimensies. OpenAI's grotere modellen gebruiken bijvoorbeeld 1536-3072 dims, terwijl Meta's basis E5/GTE 768 of 1024 gebruikt. In een pilot-experiment duurde het indexeren van hetzelfde corpus 2,4× langer met 1536D embeddings dan met 768D . Dus, als throughput en latency cruciaal zijn (bijv. on-device filtering van honderden queries/sec), kan 768D of 1024D volstaan. Als maximale recall het doel is (en de hardware het toelaat), zijn grotere dims acceptabel. Voor de luchtvaart zou men kunnen beginnen met 1024D (gebalanceerd) en kleinere versus grotere modellen testen op ophaaltaken in domeingegevens.
Afstandsmetriek: De keuze voor cosinus (of genormaliseerd dot-product) versus ruwe Euclidische is afhankelijk van de embedding. De meeste moderne tekst-embeddings worden vergeleken via cosinus-similariteit. Tekgöz et al. ontdekten bijvoorbeeld dat cosinus/Pearson-metrieken de beste similariteit opleverden voor foutbeschrijvingen. Redis en andere systemen ondersteunen het expliciet specificeren van "COSINE" (achter de schermen normaliseren van vectoren), terwijl veel systemen inwendig product gebruiken op vooraf genormaliseerde vectoren. In de praktijk zijn cosinus en inwendig product equivalent als de embeddings genormaliseerd zijn. Euclidische afstand is minder gebruikelijk voor tekst, maar conceptueel vergelijkbaar wanneer vectoren zich op een bol bevinden. Aanbeveling: gebruik cosinus voor tekstgebaseerde embeddings.
Metadata en hybride structurering: Het is belangrijk om vector-embeddings op te slaan naast gestructureerde metadata (vliegtuigmodel, ATA-hoofdstuk, datum, onderdeelnummer, enz.) voor een verfijnde zoekopdracht. Alle moderne vectoropslagplaatsen maken het mogelijk om metadata aan elke vector toe te voegen. Met Redis Vector Sets kunt u bijvoorbeeld filteren op JSON-attributen in dezelfde query (bijv. WHERE aircraft_model = 'A320' AND ATA = '21'). Qdrant biedt krachtige Booleaanse filtering om vectorresultaten te verfijnen op metadata. Definieer bij het ontwerpen van het schema metadatavelden (bijv. model, ata, datum, onderdeelnummer) en indexeer deze op de normale manier, terwijl u het tekstveld als een VECTOR markeert. Bij hybride query's past het systeem eerst het metadatafilter toe (of combineert het dit via een scorestraf) en doorzoekt vervolgens alleen de subset op dichtstbijzijnde buren, wat de precisie verbetert. Zorg ervoor dat kritieke filters (bijv. staartnummer van vliegtuig of tijdsbereik) op geïndexeerde scalaire velden staan om DB-filtering te benutten.
Latency en Throughput Tuning: ANN-indexparameters moeten worden afgestemd op doellatentie. Voor HNSW levert het verhogen van de efSearch-parameter een hogere recall op, maar verhoogt het lineair de querytijd. Een praktische aanpak is om recall versus latentie te vergelijken met een set die is achtergehouden: begin met een lage ef voor snelheid en verhoog deze vervolgens tot een recall-plateau. Weaviate ondersteunt zelfs een "dynamische ef" die ef schaalt met het gewenste aantal resultaten. Voor batch-workloads kan men FLAT-indexen (exact) gebruiken om de nauwkeurigheid te maximaliseren, terwijl voor realtime query's van tientallen milliseconden HNSW of IVF met afgestemde parameters beter is. Kwantisering (8-bits, productkwantisering) is een andere hefboom: bijvoorbeeld de Q8- versus BIN-instellingen van Redis verminderen het geheugen drastisch en versnellen het zoeken, ten koste van een lichte daling van de nauwkeurigheid.
Indexupdates: Als uw gegevens regelmatig veranderen (nieuwe loggegevens of handmatige updates), kies dan systemen die dynamische indexering ondersteunen. De HNSW-implementatie van Redis maakt on-the-fly invoegingen en verwijderingen mogelijk zonder de index opnieuw op te bouwen. Weaviate kan HNSW asynchroon bijwerken (zodat schrijfbewerkingen geen leesbewerkingen blokkeren). Andere systemen, zoals FAISS, vereisen doorgaans herindexering, dus gebruik deze voor overwegend statische corpora. Houd rekening met herindexering als er nieuwe handleidingen binnenkomen of als er dagelijkse logs moeten worden toegevoegd. In veel luchtvaartsystemen veranderen handleidingen langzaam, maar komen er dagelijkse logs/dispatch-items binnen, dus hybride benaderingen (nieuwe vectoren schrijven naar een "hot" index voor een dag en 's nachts samenvoegen) kunnen werken.
Samenvatting
Vectordatabases en embeddingmodellen maken samen rijke semantische intelligentie over luchtvaartdata mogelijk. Hoogwaardige embeddings (bijv. 768-3072D-modellen) vertalen handleidingen, logboeken en onderdeelbeschrijvingen naar doorzoekbare vectoren, terwijl gespecialiseerde vectoropslag (Redis, Pinecone, Weaviate, Qdrant, Vespa, FAISS, Milvus) de ANN-indexen en filtering bieden die op schaal nodig zijn. De bovenstaande tabel vergelijkt de belangrijkste kenmerken: Redis en Qdrant blinken uit in lage latentie met filtering; Pinecone en Milvus blinken uit op enorme schaal; Weaviate en Vespa ondersteunen hybride (grafiek + vector) query's; FAISS biedt ultieme prestaties voor aangepaste pipelines. Embedding-keuzes (model, dimensie, normalisatie) en indexafstemming (HNSW-parameters, kwantificering) moeten in evenwicht zijn met recall versus snelheid. Samen zorgen deze technologieën ervoor dat ML-teams in de luchtvaart geavanceerde hulpmiddelen kunnen bouwen (gebruikersinterfaces voor semantische zoekopdrachten, chatbots voor onderhoud, voorspellende analyses) waarmee ongestructureerde logboeken en handleidingen kunnen worden omgezet in bruikbare inzichten.
Trends in luchtvaartonderhoud die in onzekere omstandigheden aan momentum kunnen winnen
Vliegtuigen blijven langer in gebruik, toeleveringsketens zijn een kruitvat en de technologie ontwikkelt zich van de ene op de andere dag. Ontdek de onderhoudstrends die aan populariteit winnen en wat ze betekenen voor exploitanten die in de lucht en winstgevend willen blijven.

April 10, 2026
Mission Control: High-performance intelligent infrastructuur voor missiekritische beslissingssnelheid
Elke leider met wie ik spreek in de luchtvaart, maakindustrie of bouw zegt hetzelfde:
Onze systemen worden slimmer, maar onze beslissingen worden niet sneller of veiliger in het tempo dat de operaties vereisen.
In omgevingen met hoge integriteit is de kloof tussen gegevens en beslissingen de plek waar risico’s zich opstapelen. Naarmate operaties complexer, meer verspreid en tijdkritischer worden, hebben organisaties intelligentesystemen nodig die niet alleen snel zijn, maar ook verifieerbaar, deterministisch en veilig-by-design.
Dit is de technische filosofie achter Mission Control, onze high‑performance intelligence‑infrastructuur, gebouwd voor realtime, controleerbare en cryptografisch beveiligde beslissingssnelheid.

October 2, 2025
De juiste vliegtuigonderdelen kiezen met schadetolerantieanalyse
De toekomst van luchtvaartveiligheid draait om de onderdelen. Authentieke, traceerbare onderdelen zorgen voor optimale schadetolerantie en prestaties van vloten, voor maximale veiligheid en inkoopefficiëntie.

September 30, 2025
Hoe u nieuwe luchtvaartmarkten betreedt: de complete gids voor onderdelenleveranciers
Betreedt u nieuwe luchtvaartmarkten? Ontdek hoe leveranciers de vraag kunnen analyseren, PMA-onderdelen kunnen beheren en vertrouwen kunnen opbouwen bij luchtvaartmaatschappijen. Een complete gids voor wereldwijde groei.

