Orquestre insights de IA em ações
Vector DB. Desbloqueie a inteligência não estruturada da aviação.
junho 15, 2025
Bancos de dados vetoriais indexam vetores de incorporação de alta dimensão para permitir a busca semântica em dados não estruturados, diferentemente dos armazenamentos relacionais ou de documentos tradicionais, que usam correspondências exatas de palavras-chave. Em vez de tabelas ou documentos, os armazenamentos vetoriais gerenciam vetores numéricos densos (geralmente de 768 a 3.072 dimensões) que representam a semântica de texto ou imagem. No momento da consulta, o banco de dados encontra os vizinhos mais próximos de um vetor de consulta usando algoritmos de busca por vizinho mais próximo aproximado (RNA). Por exemplo, um índice baseado em grafos como o Hierarchical Navigable Small Worlds (HNSW) constrói grafos de proximidade em camadas: uma pequena camada superior para busca grosseira e camadas inferiores maiores para refinamento (veja a figura abaixo). A busca "salta" por essas camadas — localizando-se rapidamente em um cluster antes de buscar exaustivamente os vizinhos locais. Isso compensa a recuperação (encontrar os verdadeiros vizinhos mais próximos) com a latência: aumentar o parâmetro de busca HNSW (efSearch) aumenta a recuperação ao custo de um tempo de consulta maior.
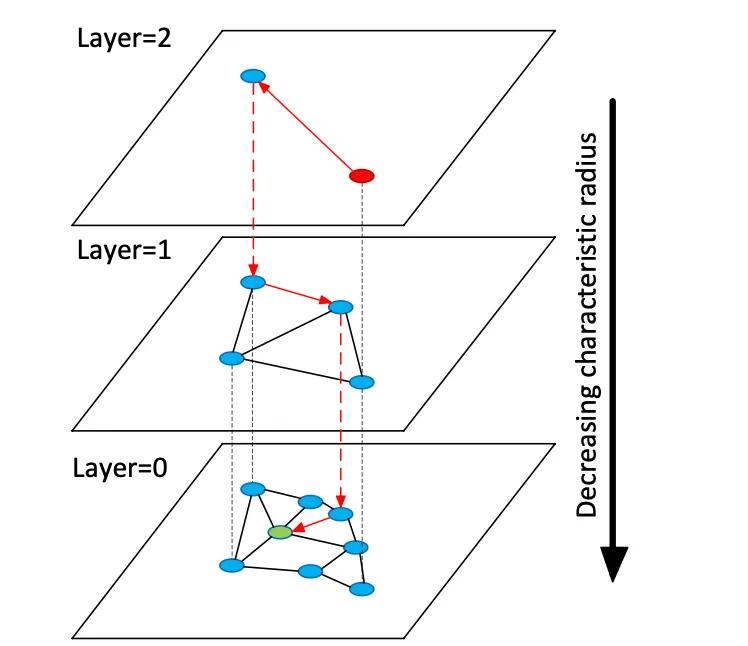
Figura: gráfico de pesquisa HNSW ANN – os vetores são organizados em camadas para acelerar as consultas do vizinho mais próximo (adaptado da explicação Redis Vector Sets do Devmy).
Ao contrário da pesquisa exata em tabelas relacionais, a pesquisa vetorial pode capturar significado: as consultas encontram itens semanticamente semelhantes, não apenas correspondências exatas de palavras-chave. Para dados de aviação (por exemplo, manuais ou registros de reparo), isso significa que os engenheiros podem recuperar conteúdo relevante mesmo que a redação seja diferente. Distâncias vetoriais (cosseno, produto escalar ou euclidiana) quantificam a similaridade. Quando os embeddings são normalizados, a similaridade de cosseno e o produto escalar produzem classificações equivalentes. Na prática, geralmente normaliza-se vetores e usa-se a similaridade de cosseno como métrica de relevância. As principais compensações incluem recall vs. latência: índices maiores e parâmetros de pesquisa mais altos melhoram o recall, mas aumentam a latência. Bancos de dados vetoriais fornecem índices ajustáveis (HNSW, FIV, varredura plana) para equilibrar velocidade versus precisão.
Modelos de incorporação
Modelos de incorporação modernos convertem texto (ou outros dados) em vetores. Os principais modelos incluem o text-embedding-3-large da OpenAI, o embed-multilingual-v3 da Cohere, os modelos Gemini/BGE da Google, as famílias E5 e GTE da Meta e muitos modelos HuggingFace (por exemplo, variantes Sentence-BERT). Esses modelos diferem em dimensionalidade, cobertura de dados e custo de inferência. Por exemplo, o text-embedding-3-large da OpenAI produz vetores de 3072 dimensões, significativamente maiores que o anterior Ada-002 (1536D). Os modelos v3 da Cohere normalmente produzem 1024D (inglês ou multilíngue) ou menores (por exemplo, versões "leves" de 384D). Os modelos E5-large e GTE-large da Meta também produzem embeddings de 1024D, enquanto suas variantes base ou "pequenas" produzem 768D ou 384D. Os embeddings Vertex-AI do Google incluem modelos de texto 768D e um modelo grande "gemini-embedding-001" 3072D. Em geral, dimensões maiores geralmente melhoram a fidelidade semântica, mas exigem mais armazenamento e computação: e5-base (768D) indexou um conjunto de dados mais de 2 vezes mais rápido que ada-002 (1536D) em um benchmark.
Os modelos de incorporação também variam de acordo com os dados de treinamento e o multilinguismo. As APIs de incorporação do OpenAI e do Cohere são proprietárias (com custos e limites de uso associados), enquanto os modelos E5/GTE e muitos modelos HuggingFace do Meta são de código aberto (licenciados pela Apache). Os modelos E5 e GTE oferecem suporte a mais de 50 idiomas, assim como os modelos multilíngues v3 do Cohere. Essa cobertura multilíngue é valiosa para a documentação da aviação internacional. A adaptação de domínio é crítica para vocabulários especializados (por exemplo, idioma do capítulo ATA, nomenclatura de peças). Prontos para uso, esses modelos são treinados em texto da web e corpora comuns; eles podem não capturar perfeitamente o jargão da aviação. As equipes devem considerar o ajuste fino ou o uso de adaptadores em registros ou manuais de manutenção. Na prática, os sistemas corporativos geralmente começam com fortes incorporações gerais (como OpenAI ou E5) e, em seguida, fazem o ajuste fino em texto específico do domínio.
Do ponto de vista do desempenho, os modelos variam em latência. Modelos menores (por exemplo, E5-base-768) são mais rápidos na inferência, enquanto modelos proprietários maiores (3072D da OpenAI) são mais lentos e podem permitir apenas uma solicitação por vez. Se o hardware local for limitado, modelos menores ou quantizados podem ser usados. O licenciamento é importante: OpenAI e Cohere cobram por solicitação e têm políticas de uso, enquanto modelos abertos como E5/GTE ou BGE do Google (aberto via VertexAI com cotas) evitam custos de API. Em resumo, qualquer banco de dados vetorial pode ingerir embeddings de qualquer um desses modelos, mas os arquitetos devem considerar a dimensionalidade, o custo, o suporte multilíngue e o ajuste de domínio do embedding ao selecionar modelos para dados de aviação.
Tipos de bancos de dados vetoriais
Existe uma variedade de sistemas de bancos de dados vetoriais, desde bibliotecas leves até plataformas completas:
- Redis (Vector Sets) – O Redis é um armazenamento de chave-valor na memória com um módulo de índice vetorial. Ele suporta índices FLAT (exact brute-force) e HNSW. Os Redis Vector Sets permitem atualizações dinâmicas de forma exclusiva: os gráficos HNSW são mantidos bidirecionalmente para que os vetores possam ser adicionados ou excluídos dinamicamente com efeito imediato. O Redis suporta quantização (8 bits ou binária) para reduzir a memória (até 4×–32×) com perda mínima de precisão. Ele também fornece filtragem híbrida: os vetores podem ser armazenados junto com tags de texto ou campos numéricos e filtrados (por exemplo, .year > 2020) na mesma consulta. Como um mecanismo na memória, o Redis oferece latência ultrabaixa ao custo do uso de RAM. Ele escala horizontalmente por meio de clustering, embora os tamanhos de cluster sejam normalmente menores do que as plataformas de vetores dedicadas. O Redis está disponível como código aberto ou por meio do Redis Enterprise Cloud.
- Pinecone – Um serviço de nuvem de pesquisa vetorial totalmente gerenciado. O Pinecone abstrai toda a infraestrutura: separa o armazenamento da computação e escala para bilhões de vetores, mantendo tempos de consulta rápidos. Ele gerencia índices automaticamente em segundo plano (combinando HNSW, IVF, PQ, etc.) para desempenho ideal. A desvantagem é o custo e a opacidade: o Pinecone é fácil de usar (sem operações), mas mais caro que o OSS. Ele se destaca em cargas de trabalho de alto rendimento e vinculadas a SLA, suportando consultas híbridas (palavra-chave + vetor) e recursos corporativos. O Pinecone é ideal para equipes que precisam de escalabilidade e confiabilidade de nível empresarial sem precisar gerenciar servidores.
- Weaviate – Um banco de dados vetorial centrado em gráficos de código aberto (também oferecido como um serviço gerenciado). O Weaviate permite a estruturação rica de esquemas e gráficos de conhecimento junto com vetores. Ele oferece uma API GraphQL para combinar pesquisa vetorial semântica com consultas tradicionais (recuperação híbrida). O Weaviate usa principalmente índices HNSW (e pode usar índice plano para pequenos conjuntos de dados). Ele ajusta automaticamente os parâmetros de pesquisa ou permite indexação assíncrona para rendimento. Com módulos para aprendizado profundo, o Weaviate pode até gerar vetores (por exemplo, por meio de modelos HuggingFace). Ele escala via Kubernetes e clusters em nuvem ou locais. Os pontos fortes do Weaviate são a pesquisa híbrida semântica+simbólica e a flexibilidade na modelagem de dados; é adequado quando os relacionamentos (por exemplo, hierarquias de peças para aeronaves) importam tanto quanto a similaridade de vetores.
- Qdrant – Um mecanismo de busca vetorial de código aberto em Rust. O Qdrant oferece um índice ANN de alto desempenho com filtragem avançada de metadados. Ele suporta índices HNSW com escalonamento automático dinâmico e fornece uma API HTTP. Notavelmente, a ênfase do Qdrant está na filtragem rigorosa e confiabilidade – ele suporta implantação distribuída, transações ACID e aceleração por GPU. Ele tem um ótimo desempenho em grandes conjuntos de dados e retorna alta recuperação. O Qdrant Cloud simplifica a implantação, mas é igualmente robusto e auto-hospedado. Isso torna o Qdrant uma ótima opção quando você precisa combinar similaridade vetorial e filtros estruturados (por exemplo, pesquisar apenas em determinados modelos de aeronaves ou intervalos de datas).
- Vespa – Um mecanismo de busca e análise de código aberto originalmente do Yahoo. O Vespa integra de forma única a busca vetorial com a busca clássica de índice invertido. Ele pode lidar com bilhões de vetores com rendimento extremo: a plataforma anuncia suporte para milhares de QPS em latências <100ms em dados vastos. O Vespa suporta multivetor por documento e busca híbrida (semântica + palavra-chave). Sua indexação ANN inclui HNSW (e novas variantes como HNSW-IF que combinam filtragem de arquivo invertido). Como um servidor de aplicativos completo, o Vespa também suporta modelos de classificação personalizados e pipelines de inferência de ML. Portanto, é adequado para aplicações de busca de missão crítica em larga escala (por exemplo, portais de busca para companhias aéreas) onde escala e relevância híbrida são necessárias. O Vespa pode ser autogerenciado ou usado via Vespa Cloud.
- FAISS – Uma biblioteca de nível de pesquisa da Meta para pesquisa de similaridade. O FAISS não é um banco de dados independente, mas uma coleção de índices altamente otimizados (Flat, IVF, PQ, HNSW, etc.) que rodam em CPU/GPU. Ele alcança velocidade excepcional (especialmente com GPUs) e flexibilidade: quase qualquer métrica de distância ou método de indexação pode ser usado. No entanto, o FAISS não inclui um mecanismo de armazenamento/consulta ou filtragem de metadados – você deve integrá-lo ao seu próprio sistema. É mais adequado quando o máximo desempenho e controle sobre algoritmos de indexação são necessários. Por exemplo, o FAISS é amplamente utilizado em visão computacional e pesquisa de ML onde recall e velocidade são primordiais e tamanhos de dados são fixos. Na aviação, o FAISS pode sustentar uma ferramenta de pesquisa personalizada para embeddings de dimensões muito altas (por exemplo, reconhecimento de peças baseado em imagem), mas requer uma arquitetura envolvente.
- Milvus – Um popular banco de dados vetorial de código aberto projetado para cargas de trabalho de grande escala. O Milvus oferece modos autônomo e distribuído, suportando bilhões de vetores com forte consistência. Ele fornece vários tipos de índice (HNSW, IVF, Annoy, etc.) e métricas (cosseno, L2, etc.), além de busca híbrida via filtragem escalar. O Milvus é acelerado por GPU e nativo da nuvem (integra-se ao Kubernetes). Inclui recursos corporativos como snapshots e criptografia e é desenvolvido ativamente pela Zilliz. A arquitetura do Milvus é construída para escala e desempenho, tornando-o ideal para aplicações com uso intensivo de dados, como a análise de arquivos massivos de manuais ou registros de sensores. A Zilliz também oferece o Milvus Cloud para hospedagem gerenciada.
Cada um desses sistemas lida com vetores e filtros de forma diferente, mas todos suportam distâncias de L2, produto interno (ponto) e cosseno (geralmente armazenando vetores normalizados). O fórum do Weaviate observa que ele pode até armazenar vetores de até 65.535 dimensões, muito acima dos tamanhos típicos de embedding, demonstrando a flexibilidade dos mecanismos modernos. Resumindo:
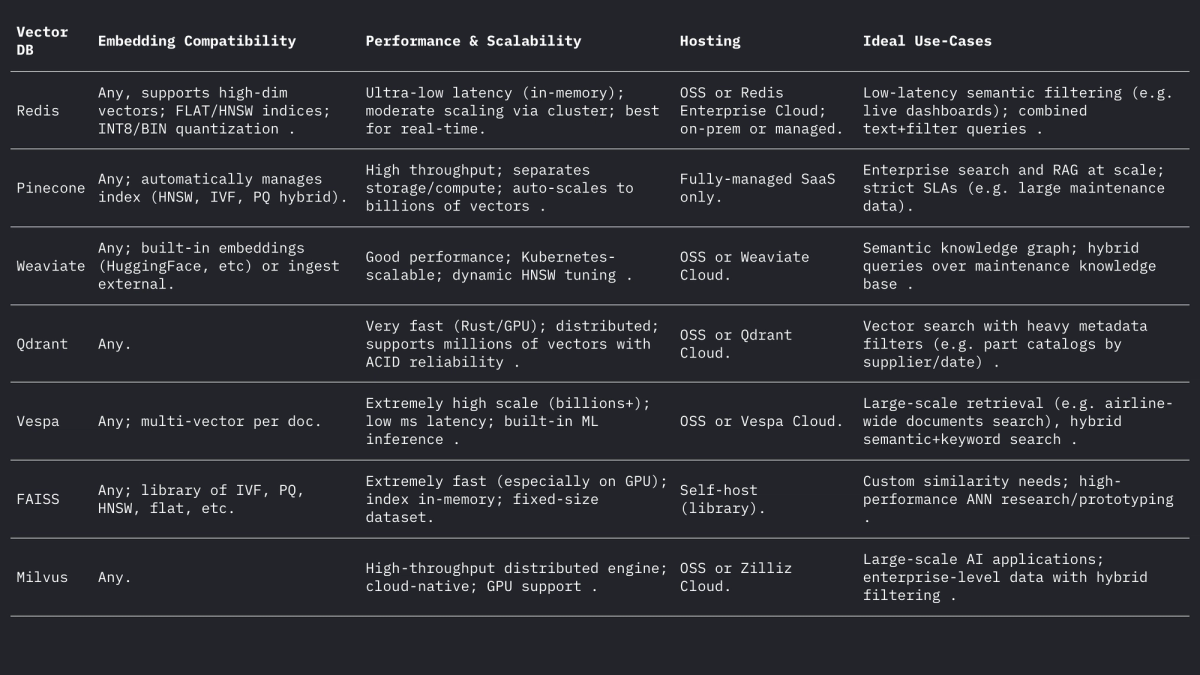
Casos de uso na aviação
Busca Semântica: A manutenção de aeronaves envolve vastas coleções de manuais, boletins de serviço e documentos de regulamentação. Um sistema de busca vetorial permite que engenheiros façam consultas em linguagem natural (ou até mesmo consultas por voz) e recuperem passagens ou documentos relevantes semanticamente. Por exemplo, em vez de uma busca por palavra-chave como "vazamento de óleo do motor", uma busca incorporada pode encontrar parágrafos de boletins descrevendo "vazamento de fluido hidráulico" se forem contextualmente semelhantes. Como demonstrado pela Infosys/AWS, o armazenamento de cada documento técnico como vetores permite que agentes com LLM respondam a consultas de manutenção recuperando os documentos mais relevantes do repositório.
Correspondência Fuzzy de Peças: Peças de aviação frequentemente possuem identificadores enigmáticos (NSN ou números de peça) e nomes descritivos que variam entre os fornecedores. Incorporações vetoriais de descrições de peças ou mesmo dos números de peça (tratados como texto) podem revelar quase duplicatas que a correspondência baseada em regras não detecta. Em outros domínios, incorporações de palavras têm sido usadas para correspondências fuzzy de nomes semanticamente; da mesma forma, incorporações de descritores de peças podem corresponder uma peça à sua descrição mais próxima em catálogos de fornecedores, mesmo que a grafia ou os códigos sejam diferentes. Isso poderia unificar o estoque de múltiplas fontes.
Classificação e Agrupamento de Logs: Logs de reparos e falhas geralmente são textos livres. Modelos de incorporação podem converter entradas de log em vetores, e o agrupamento desses vetores pode agrupar automaticamente padrões de falhas semelhantes. Por exemplo, a estrutura "HELP" agrupa logs de sistema de streaming por seus embeddings para descobrir modelos de log recorrentes. Na aviação, o agrupamento análogo pode identificar modos de falha comuns ou categorizar entradas de manutenção não programadas sem rótulos predefinidos, permitindo análises sobre problemas frequentes (por exemplo, agrupando incidentes de "vibração estranha"). Esse agrupamento semântico não supervisionado auxilia na análise de tendências e na previsão da carga de trabalho.
Recuperação Conversacional (RAG): Embeddings são a base dos sistemas de Geração Aumentada de Recuperação (RAG) que alimentam chatbots em documentos. Um exemplo de chatbot em PDF mostra a arquitetura: extrair texto de manuais, dividi-lo em partes, incorporar cada parte e armazená-lo em um repositório de vetores (como o FAISS). Em tempo de execução, cada consulta do usuário é incorporada e usada para recuperar as principais k partes relevantes por meio do índice vetorial. Essas partes formam o contexto para um LLM responder à pergunta. Para a aviação, um pipeline de RAG permite que um técnico "converse" com o gêmeo digital da aeronave: por exemplo, perguntando "Qual é o procedimento para substituir o interruptor de aquecimento do pitot?" e obtendo uma resposta precisa proveniente dos manuais do fabricante do equipamento original.
Indexação Preditiva de Falhas: Registros históricos de manutenção descrevem falhas e correções. É possível indexar as descrições de falhas como vetores, de modo que a descrição de um novo incidente seja comparada a casos anteriores semelhantes. Pesquisas em manutenção preditiva constataram que o cálculo da similaridade semântica de textos de falhas usando embeddings de transformadores (com similaridade de cosseno ou Pearson) agrupa com sucesso falhas relacionadas. Na prática, quando um mecânico registra uma nova descrição de falha, o sistema pode recuperar incidentes anteriores com alta similaridade de embedding para sugerir prováveis causas-raiz ou verificações, efetivamente "prevendo" com base na proximidade no espaço de embedding.
Considerações práticas de design
Dimensionalidade de Incorporação: Incorporações de dimensões mais altas capturam mais nuances, mas custam mais em armazenamento e computação. As escolhas comuns são dimensões de 768, 1024, 1536 ou 3072. Por exemplo, os modelos maiores do OpenAI usam dims de 1536–3072, enquanto o E5/GTE base do Meta usa 768 ou 1024. Em um experimento piloto, a indexação do mesmo corpus levou 2,4 vezes mais tempo com incorporações de 1536D do que com 768D. Portanto, se a taxa de transferência e a latência forem críticas (por exemplo, filtragem no dispositivo de centenas de consultas/seg), 768D ou 1024D podem ser suficientes. Se a recuperação máxima for o objetivo (e o hardware permitir), dims maiores são aceitáveis. Para a aviação, pode-se começar com 1024D (balanceado) e testar modelos menores vs. maiores em tarefas de recuperação em dados de domínio.
Métrica de Distância: A escolha entre cosseno (ou produto escalar normalizado) e euclidiano bruto depende da incorporação. A maioria das incorporações de texto modernas é comparada por similaridade de cosseno. Por exemplo, Tekgöz et al. descobriram que as métricas de cosseno/Pearson apresentaram a melhor similaridade para descrições de falhas. O Redis e outros apoiam a especificação explícita de "COSSELO" (nos bastidores da normalização de vetores), enquanto muitos sistemas usam produto interno em vetores pré-normalizados. Na prática, cosseno e produto interno são equivalentes se as incorporações forem normalizadas. A distância euclidiana é menos comum para texto, mas conceitualmente semelhante quando os vetores estão em uma esfera. Recomendação: use cosseno para incorporações baseadas em texto.
Metadados e Estruturação Híbrida: É importante armazenar embeddings de vetores junto com metadados estruturados (modelo de aeronave, capítulo ATA, data, número da peça, etc.) para pesquisa refinada. Todos os armazenamentos de vetores modernos permitem anexar metadados a cada vetor. Por exemplo, os Conjuntos de Vetores Redis permitem filtrar por atributos JSON na mesma consulta (por exemplo, WHERE aircraft_model = 'A320' AND ATA = '21'). O Qdrant fornece filtragem booleana poderosa para restringir os resultados do vetor por metadados. Ao projetar o esquema, defina campos de metadados (por exemplo, modelo, ata, data, part_no) e indexe-os normalmente enquanto marca o campo de texto como um VETOR. Em consultas híbridas, o sistema primeiro aplica o filtro de metadados (ou os combina por meio de uma penalidade de pontuação) e então pesquisa apenas o subconjunto para vizinhos mais próximos, melhorando a precisão. Certifique-se de que filtros críticos (por exemplo, número da cauda da aeronave ou intervalo de tempo) estejam em campos escalares indexados para aproveitar a filtragem do BD.
Ajuste de Latência e Taxa de Transferência: Os parâmetros de índice ANN devem ser ajustados para latência alvo. Para HNSW, aumentar o parâmetro efSearch produz maior recall, mas aumenta linearmente o tempo de consulta. Uma abordagem prática é comparar recall vs. latência em um conjunto mantido: comece com um ef baixo para velocidade, então aumente até o platô de recall. O Weaviate ainda suporta um "ef dinâmico" que escala ef com a contagem de resultados desejada. Para cargas de trabalho em lote, pode-se usar índices FLAT (exatos) para maximizar a precisão, enquanto para consultas em tempo real de dezenas de milissegundos, HNSW ou IVF com parâmetros ajustados é melhor. A quantização (quantização de produto de 8 bits) é outra alavanca: por exemplo, as configurações Q8 vs BIN do Redis reduzem drasticamente a memória e aceleram a pesquisa, à custa de uma ligeira queda na precisão.
Atualizações de Índice: Se seus dados mudam frequentemente (novas entradas de log ou atualizações manuais), escolha sistemas que suportem indexação dinâmica. A implementação HNSW do Redis permite inserções e exclusões instantâneas sem a necessidade de reconstruir o índice. O Weaviate pode atualizar o HNSW de forma assíncrona (para que as gravações não bloqueiem as leituras). Outros, como o FAISS, normalmente exigem reindexação, portanto, use-os para corpora predominantemente estáticos. Planeje a reindexação caso novos manuais cheguem ou seja necessário adicionar logs diários. Em muitos sistemas de aviação, os manuais mudam lentamente, mas os logs/entradas de despacho diários chegam, portanto, abordagens híbridas (gravar novos vetores em um índice "ativo" por um dia e mesclar todas as noites) podem funcionar.
Resumo
Bancos de dados vetoriais e modelos de incorporação, em conjunto, possibilitam uma rica inteligência semântica sobre dados de aviação. Incorporações de alta qualidade (por exemplo, modelos 768–3072D) traduzem manuais, registros e descrições de peças em vetores pesquisáveis, enquanto repositórios de vetores especializados (Redis, Pinecone, Weaviate, Qdrant, Vespa, FAISS, Milvus) fornecem os índices de RNA e a filtragem necessários em escala. A tabela acima compara os principais recursos: Redis e Qdrant se destacam em baixa latência com filtragem; Pinecone e Milvus se destacam em escala massiva; Weaviate e Vespa suportam consultas híbridas (gráfico+vetor); FAISS oferece desempenho máximo para pipelines personalizados. As opções de incorporação (modelo, dimensão, normalização) e ajuste de índice (parâmetros HNSW, quantização) devem ser balanceadas para recall e velocidade. Juntas, essas tecnologias permitem que as equipes de ML de aviação criem ferramentas avançadas (interfaces de usuário de pesquisa semântica, chatbots de manutenção, análise preditiva) que convertem registros e manuais não estruturados em insights acionáveis.
Tendências de manutenção da aviação que podem ganhar força em circunstâncias incertas
As aeronaves estão em serviço por mais tempo, as cadeias de suprimentos são um barril de pólvora e a tecnologia está evoluindo da noite para o dia. Descubra as tendências de manutenção que estão ganhando força e o que elas significam para as operadoras que buscam se manter no ar e lucrativas.

April 10, 2026
Mission Control: Infraestrutura de Inteligência de Alto Desempenho para Velocidade Crítica na Tomada de Decisões
Todo líder com quem converso nos setores aeroespacial, de manufatura ou de construção diz a mesma coisa:
Nossos sistemas estão ficando mais inteligentes, mas nossas decisões não estão se tornando mais rápidas nem mais seguras no ritmo que as operações exigem.
Em ambientes de alta integridade, a lacuna entre dados e decisões é onde o risco se acumula. À medida que as operações se tornam mais complexas, distribuídas e sensíveis ao tempo, as organizações precisam de sistemas de inteligência que não sejam apenas rápidos, mas também verificáveis, determinísticos e seguros por concepção.
Esta é a filosofia de engenharia por trás do Mission Control, nossa infraestrutura de inteligência de alto desempenho, criada para oferecer velocidade de decisão em tempo real, auditável e com segurança criptográfica.

October 2, 2025
Escolhendo as peças certas da aeronave com análise de tolerância a danos
O futuro da segurança da aviação está nas peças. Peças autênticas e rastreáveis proporcionam às frotas tolerância a danos e desempenho ideais para máxima segurança e eficiência na aquisição.

September 30, 2025
Como entrar em novos mercados de aviação: o guia completo para fornecedores de peças
Entrando em novos mercados de aviação? Aprenda como os fornecedores podem analisar a demanda, gerenciar peças PMA e construir a confiança das companhias aéreas. Um guia completo para o crescimento global.

