Trasforma le intuizioni dell’IA in azioni concrete
Intelligenza artificiale per documenti di livello aeronautico. Precisione e prestazioni.
giugno 11, 2025
Introduzione: il diluvio di documenti dell’aviazione e l’imperativo dell’accuratezza
Il settore dell'aviazione è inondato di documenti critici: certificati di aeronavigabilità, cataloghi illustrati dei componenti (IPC), manuali di manutenzione, bollettini di servizio/direttive di aeronavigabilità della FAA, registri di volo e altro ancora. Questi documenti non strutturati e voluminosi sono la linfa vitale delle operazioni e della conformità del settore aeronautico. Ad esempio, un singolo aereo commerciale statunitense può produrre fino a7.500 pagine di nuovi documenti all'annoper soddisfare i requisiti del DOT e della FAA. Garantire che i sistemi di intelligenza artificiale possano interpretare e utilizzare in modo affidabile questa montagna di dati è imprescindibile. Nella costruzioneintelligenza artificiale di livello aeronautico, un principio risalta:la qualità degli output dell'IA è buona solo quanto la precisione dell'estrazione dei dati sottostantiIn altre parole, se l'estrazione dei dati dal documento è difettosa, anche il modello di intelligenza artificiale più avanzato propagherà tali errori, un classico scenario "garbage in, garbage out". I responsabili dell'intelligenza artificiale e i team tecnici devono quindi dare prioritàestrazione di dati di documenti ad alta precisionecome fondamento di qualsiasi percorso di intelligenza artificiale nel settore dell'aviazione.
Dati non strutturati nell'aviazione: sfide e necessità
Le aziende aeronautiche dipendono da documenti non strutturati per ogni aspetto, dalla conformità normativa alle operazioni quotidiane. Consideriamo solo alcuni esempi:
- Documenti normativi:Certificati di aeronavigabilità, FAABollettini di servizio (SB) E Direttive di aeronavigabilità (DA)Bollettini, certificazioni di sicurezza e rapporti sugli incidenti sono obbligatori e sottoposti a frequenti controlli. Qualsiasi dettaglio inesatto può comportare violazioni della conformità o il fermo degli aeromobili.
- Manuali tecnici: Manuali di manutenzione E IPCContengono codici di componenti complessi, schemi di assemblaggio e procedure su cui ingegneri e meccanici fanno affidamento. Spesso si estendono per migliaia di pagine e sono disponibili in vari formati (PDF scansionati, stampe di vecchia data), rendendo difficile l'analisi automatizzata.
- Registri operativi:I registri di volo, i registri di manutenzione e gli ordini di lavoro registrano i dati operativi in corso. Di solito sono in formato libero, scritti a mano o a macchina, il che aggiunge un ulteriore livello di complessità all'estrazione.
- Documenti di approvvigionamento e inventario:Cataloghi illustrati di ricambi ed elenchi di ricambi, richieste di preventivo (RFQ), ordini di acquisto e registri di garanzia vengono utilizzati per l'approvvigionamento di ricambi e la gestione dell'inventario. Errori nell'estrazione di codici o quantità di componenti possono portare a costosi errori di inventario.
Affrontare questodiluvio di documentiè impegnativo perché i dati non sono strutturati, intrappolati in descrizioni, tabelle e moduli in linguaggio naturale. Si stima cheL'80% dei dati aziendali non è strutturato, nascosti in PDF, email e moduli scansionati. Le aziende aeronautiche conoscono bene questo problema: secondo IDC, i dipendenti possono dedicare circa il 30% del loro tempo semplicemente a cercare e consolidare informazioni tra i documenti. Le conseguenze della scarsa qualità dei dati sono gravi: IBM ha stimato che i dati di scarsa qualità costino all'economia statunitense circa3,1 trilioni di dollari all'annoNel settore dell'aviazione, la posta in gioco è ancora più alta: registri di manutenzione archiviati o letti in modo errato possono mettere a terra una flotta, e un codice componente errato può comportare una riparazione non riuscita o un rischio per la sicurezza. Documenti voluminosi e ad alto rischio richiedono un'accuratezza di estrazione di altissimo livello.
Garbage In, Garbage Out: perché l'estrazione di precisione è importante
Modelli di intelligenza artificiale moderni, che si tratti di unLLM (Large Language Model)Rispondere a domande di manutenzione o un sistema di rilevamento anomalie che segnala problemi di conformità sono efficaci solo quanto i dati che li alimentano. Se un motore OCR interpreta erroneamente "O-ring parte 65-45764-10" come "O-ring parte 65-45764-1O" (confondendo uno zero con una "O"), un sistema di intelligenza artificiale potrebbe non riuscire a trovare la cronologia dei componenti critici o, peggio, fornire una raccomandazione errata. L'estrazione di dati ad alta precisione non è solo un optional; è unprerequisito per qualsiasi risultato AI accuratonell'aviazione. Ciò è particolarmente vero pergenerazione aumentata dal recupero (RAG)Pipeline e applicazioni di ricerca. In una configurazione RAG, un LLM come GPT-4o viene arricchito con frammenti di dati tratti dal database dei documenti. Se tali frammenti vengono estratti in modo errato o con contesto mancante, l'LLM produrrà inevitabilmente risposte errate, indipendentemente dalla sofisticatezza o dalle dimensioni del modello. Allo stesso modo, i sistemi di ricerca e analisi forniranno risultati falsi se l'indice sottostante è stato alimentato con dati rumorosi. In breve,le prestazioni dell'IA a valle si degradano rapidamente quando la precisione dell'estrazione a monte vacilla– indipendentemente dalle dimensioni o dalla potenza del modello. Garantire un'accuratezza quasi realistica nella fase di acquisizione dei dati è l'unico modo per fidarsi delle informazioni prodotte in seguito dalle soluzioni di intelligenza artificiale per l'aviazione.
Oltre gli strumenti generici: il caso dell'intelligenza artificiale per i documenti specifici per l'aviazione
Non tutti i processi di elaborazione dei documenti sono uguali. Gli strumenti di intelligenza artificiale generici per i documenti (spesso ottimizzati per fatture o moduli semplici) hanno difficoltà concomplessità dei documenti aeronauticiI documenti aeronautici contengono spesso tabelle dense, assiemi multilivello, terminologia specialistica (codici componente, capitoli ATA, ecc.) e persino annotazioni manoscritte. Un OCR o un parser di moduli standard non coglierà le sfumature: ad esempio, potrebbe leggere una pagina di un catalogo illustrato di componenti come un groviglio di testo, mentre un modello addestrato al settore aeronautico sa come segmentare i codici componente, la nomenclatura, gli intervalli di efficacia e le gerarchie di assemblaggio.
Precisione specifica del dominio:La nostra intelligenza artificiale documentale incentrata sull'aviazione è stata progettata fin dalle fondamenta per questa complessità. Non tratta una pagina IPC come una tabella qualsiasi, ma comprendestruttura e relazioni a livello parzialeAd esempio, quando si estrae un IPC Boeing, il modello cattura ilripartizione delle parti delle voci di riga, inclusi gli assemblaggi padre-figlio(ad esempio, riconoscendo che il componente 65-45764-10 è un componente del gruppo padre 69-33484-2, che a sua volta è di un gruppo superiore 65-38196-5). Questa preservazione della gerarchia è fondamentale: significa che l'IA non conosce solo i componenti, ma anche come si inseriscono nel velivolo. Gli strumenti generici semplicemente non offrono questo livello di strutturazione contestuale.


Leadership di precisione:La formazione specializzata garantisce una precisione superiore. La nostra intelligenza artificiale documentale raggiungeoltre il 98% di precisione a livello di campo, E 99%+ a livello del personaggiosui documenti aeronautici. In altre parole, oltre 98 campi estratti su 100 (come "Codice articolo", "Numero di serie", "Data di installazione", ecc.) sono esattamente corretti, una percentuale irraggiungibile dalla maggior parte dei servizi OCR standard su questi tipi di documenti. Un'accuratezza a livello di carattere superiore al 99% significa che anche in codici articolo lunghi o codici alfanumerici, gli errori sono estremamente rari. Questo livello di precisione è il risultato di modelli OCR specifici per dominio, controlli di convalida NLP e un continuo perfezionamento dei dati aeronautici. Supera di gran lunga ciò che un generico elaboratore di fatture otterrebbe se confrontato, ad esempio, con un registro di manutenzione o un modulo di conformità FAA.In questa nicchia, la nostra soluzione è leader in termini di precisione, costruito appositamente per le esigenze dell'aviazione.
Inoltre, metadati di conformitàe i dettagli specifici del modulo vengono gestiti in modo elegante. A differenza di uno strumento generico che potrebbe ignorare un campo di un modulo non standard, un'IA per documenti aeronautici sa come estrarre campi come il "Numero del Certificato di Tipo" da un Certificato di Aeronavigabilità o la sezione "Efficacia" da un Bollettino di Servizio, perché sono cruciali nel contesto. Concentrandosi sudettagli a livello di parte, contesto a livello di modulo e metadati normativi, la soluzione garantisce che nessun dato critico venga trascurato. Questa attenzione alla complessità dell'aviazione è ciò che distingue l'intelligenza artificiale specializzata in ambito documentale: parla il linguaggio dei documenti aeronautici, mentre i modelli generici rimangono incomprensibili.
L'intelligenza artificiale nei documenti aeronautici in cifre
Per illustrare le prestazioni e le capacità della nostra intelligenza artificiale documentale di livello aeronautico, ecco alcuni parametri e caratteristiche chiave:
- Precisione a livello di campo > 98%– I campi dati essenziali (ID parte, date, caselle di controllo di conformità, ecc.) vengono acquisiti correttamente con una precisione superiore al 98%, anche con layout di documento diversi. Questo riduce drasticamente la necessità di correzione umana.
- Precisione OCR a livello di carattere > 99%– Grazie al robusto OCR (e all'utilizzo di livelli di testo nativi quando disponibili), il riconoscimento dei caratteri è praticamente privo di errori. Ad esempio, numeri di serie o codici componente lunghi decine di caratteri vengono riprodotti esattamente, preservando gli identificatori critici.
- Supporto IPC Boeing (assemblaggi acquisiti)– Attualmente supportaDocumenti IPC della Boeing, analizzando ogni riga di articolo. L'estrattore interpreta lo schema IPC: estrae campi come numero di figura, numero di articolo, codice componente, nomenclatura, unità per assieme e intervalli di efficacia. Fondamentalmente,cattura le relazioni di assemblaggio genitore/figlio, ricostruendo la gerarchia delle parti in ogni assieme. Ciò significa che l'IA può rispondere a domande su come sono annidati i componenti o identificare tutte le sottoparti in un dato assieme: capacità irraggiungibili con i parser generici.
- Scala – 1.000 pagine contemporaneamente– Il sistema è stato testato sul campo presso uncapacità di ingestione di 1k pagine in parallelo, eseguendo 5 batch simultanei di 200 pagine ciascuno file-q7xvjvhip1lffe4hbnkuac. In pratica, ciò significa che un'intera libreria di manuali o un anno di registri possono essere elaborati in pochi minuti. L'elevata produttività garantisce che anchearretrati ad alto volumeoppure i flussi di documenti in tempo reale (come un improvviso scarico di nuovi record di manutenzione) possono essere gestiti senza problemi.
- Divisione e classificazione dei documenti in tempo reale– Manuali PDF di grandi dimensioni o set di documenti combinati vengono automaticamentesuddiviso in singoli documenti o sezioniper l'elaborazione mirata file-q7xvjvhip1lffe4hbnkuac. Un'intelligenza artificiale basataclassificatore di documentiInnanzitutto, determina il tipo di documento (ad esempio, distinguendo un Catalogo Illustrato dei Ricambi da un Manuale di Manutenzione o da un Certificato di Aeronavigabilità) per indirizzarlo alla pipeline di estrazione corretta file-q7xvjvhip1lffe4hbnkuac. Questa classificazione ha una percentuale di richiamo prossima al 100%, garantendo che nessun documento venga identificato erroneamente o saltato. La suddivisione e la classificazione avvengono al volo, consentendo l'elaborazione continua di flussi di documenti di tipo misto in modo accurato e in tempo reale.
- Output strutturato per una facile integrazione– I dati estratti non sono solo testo grezzo, ma vengono emessi come record strutturati (JSON, XML, ecc.) completi di metadati come tipo di documento, intestazioni di sezione e persino riferimenti di pagina. Questoacquisizione della struttura del documentoCiò significa che si mantiene il contesto: ogni punto dati sa da dove proviene (pagina X del manuale Y, sezione Z). Tale struttura è preziosa quando si inseriscono i dati in altri sistemi o audit.
In sintesi, la combinazione di altissima precisione e funzionalità specifiche per ogni dominio (come la cattura della gerarchia di assemblaggio) rende questa soluzione unica nel suo genere, in grado di gestire documenti aeronautici su larga scala. Vediamo ora come queste funzionalità si integrano in una pipeline di intelligenza artificiale.
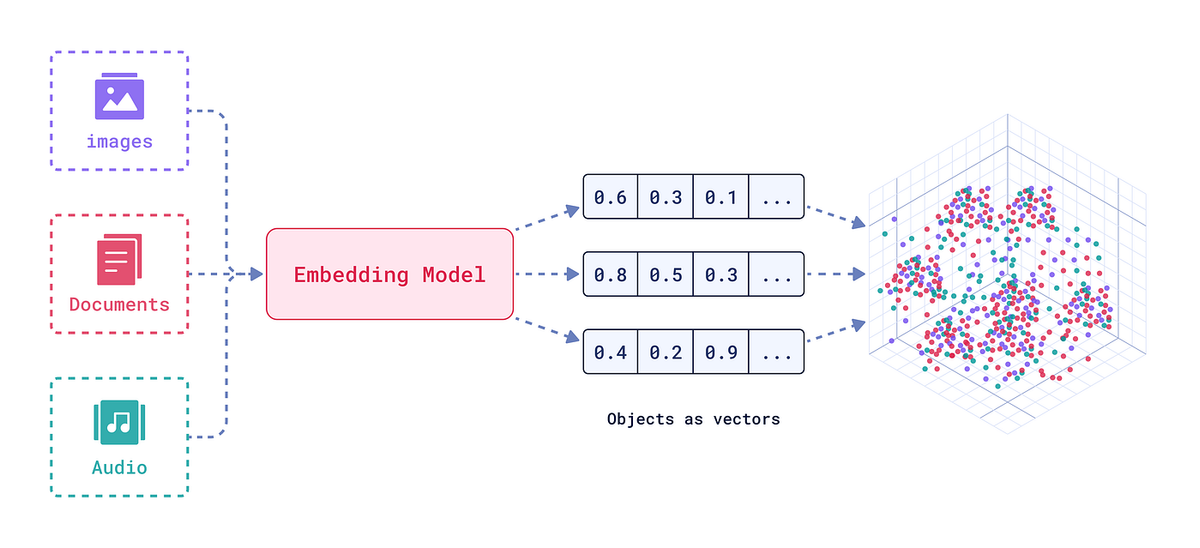
Panoramica della pipeline tecnica: dai documenti ai dati pronti per l'intelligenza artificiale
Per costruire un efficacePipeline di intelligenza artificiale per i dati aeronautici, consigliamo un approccio graduale. Ecco una panoramica della pipeline, dall'inserimento dei documenti grezzi alla distribuzione dei vettori per i modelli di intelligenza artificiale:
- Ingestione (PDF e scansioni):Accetta documenti da diverse fonti, che si tratti di scansioni ad alta risoluzione, PDF con testo incorporato o immagini. La pipeline può acquisiredocumenti cartacei scansionatie applicare l'OCR avanzato se necessario, oppure analizzare direttamente il testo dai PDF digitali (sfruttando il livello di testo per una precisione del 99,9% quando disponibile). La fase di acquisizione normalizza i formati dei file e mette in coda i documenti per l'elaborazione. È progettata per gestire caricamenti in blocco e input in streaming, avviando i processi downstream non appena arrivano nuovi file (supportando l'elaborazione basata sugli eventi per i sistemi in tempo reale).
- Classificazione:Successivamente, un classificatore basato sull'intelligenza artificiale identifica il tipo e lo scopo di ciascun documento. Ad esempio, etichetta i documenti come "Certificato di aeronavigabilità", "IPC - Boeing 737", "Scheda di manutenzione", "Bollettino FAA AD", ecc. Questo passaggio è cruciale perché la logica di estrazione è spesso specifica del modello. L'elevata accuratezza della classificazione (con un recall prossimo al 100%) garantisce che ogni documento venga indirizzato al modello di estrazione o al set di regole corretto. Se un documento contiene più sezioni (ad esempio, un PDF unito con diversi moduli), questa fase segmenta anche tali sezioni per tipo.
- Divisione automatizzata:I manuali di grandi dimensioni o i PDF che contengono più documenti vengono automaticamentediviso in unità logichefile-q7xvjvhip1lffe4hbnkuac. Ad esempio, un manuale di manutenzione di 500 pagine potrebbe essere suddiviso per capitolo o attività, oppure un PDF IPC che copre più sezioni verrà suddiviso per sezione/figura. Allo stesso modo, una pila di pagine di registro scansionate verrà suddivisa in immagini di singole pagine per l'elaborazione parallela. La suddivisione dell'input ha due scopi: consenteestrazione parallela(velocizzando notevolmente l'elaborazione) e garantisce il rispetto dei limiti di contesto (in modo che ogni blocco possa essere elaborato in modo indipendente per attività successive come l'incorporamento). Questo avviene in tempo reale: non appena viene acquisito un file di grandi dimensioni, il sistema inizia a suddividerlo e ad alimentare contemporaneamente pagine/sezioni nella fase di estrazione.
- Estrazione ad alta precisione:Questa è la fase centrale in cui entra in gioco il motore di estrazione dell'intelligenza artificiale dei documenti. Utilizzando una combinazione di modelli OCR specifici del modello, parser NLP e controlli di convalida, il sistemaestrae dati strutturati con precisione di livello aeronauticoI campi chiave vengono estratti in base al tipo di documento: per un IPC: numeri di parte, nomenclatura, riferimenti di assemblaggio, ecc.; per un registro di manutenzione: date, azioni intraprese, note del meccanico; per un modulo normativo: ID dei certificati, scadenze, firme, ecc.Integrità contestualeviene mantenuto: l'output conserva la sezione o la tabella da cui proviene un campo e i campi sono collegati (ad esempio, tutte le voci di una figura o tutte le voci con una data specifica). Il risultato è un set di dati strutturato che rappresenta le informazioni del documento. Con una precisione superiore al 98% a livello di campo, è necessaria una revisione umana minima ed eventuali cali di attendibilità o anomalie possono essere segnalate per l'ispezione.
- Incorporamento e vettorizzazione:Una volta estratti i dati testuali, questi possono essere trasformati in incorporamenti vettoriali per l'utilizzo da parte dell'IA. La pipeline si integra conprincipali modelli di incorporamento– puoi collegare il modello che preferisci (ad esempio, le API di incorporamento del testo di OpenAI, Sentence-BERT o altri codificatori basati su trasformatori) per convertire ogni blocco di documento o record di dati in un vettore ad alta dimensionalità. Supportiamo la personalizzazionestrategie di chunkingQui: ad esempio, è possibile incorporare ogni paragrafo o ogni sezione separatamente per ottimizzare il recupero a valle. Il sistema può suddividere automaticamente i campi di testo di grandi dimensioni (come i lunghi paragrafi manuali) in frammenti di dimensioni ideali per la finestra di contesto del proprio LLM, oppure è possibile definire regole di suddivisione (per frase, per sottosezione, ecc.). Questa flessibilità garantisce che gli incorporamenti catturino informazioni significative senza troncare il contesto. Al termine di questa fase, ogni documento (o sezione di documento) è rappresentato da uno o più vettori di incorporamento, in genere accompagnati da metadati (ID documento, titolo della sezione, riferimento alla fonte).
- Iniezione di database vettoriali:Infine, i vettori e i metadati sonoiniettato in un database vettorialedi tua scelta. La soluzione funziona immediatamente con i negozi di vettori più diffusi comeRedis(con vettori RediSearch),Pigna, O Elastico(la capacità di ricerca vettoriale di Elastic), tra le altre. Ciò significa che la conoscenza estratta dai documenti diventa immediatamente ricercabile tramite ricerca per similarità o utilizzabile nella generazione con recupero aumentato. Ad esempio, ora è possibile interrogare la raccolta di documenti con linguaggio naturale e recuperare i blocchi più rilevanti nello spazio vettoriale, oppure l'assistente AI può recuperare le sezioni pertinenti del manuale di manutenzione per rispondere a una domanda. La pipeline garantisce che, insieme a ciascun vettore, vengano memorizzati il testo originale e il riferimento al documento, in modo che quando viene trovata una corrispondenza vettoriale, sia possibile risalire al documento/pagina di origine. Sono supportati anche gli aggiornamenti in tempo reale: se arrivano nuovi documenti, i relativi incorporamenti possono essere inseriti al volo, mantenendo aggiornati il database dei vettori e la knowledge base dell'AI.
Questa pipeline garantisce un flusso fluido dagli input grezzi non strutturati alle informazioni strutturate e pronte per l'intelligenza artificiale. Ogni fase è ottimizzata per i casi d'uso aeronautici, dalla comprensione dei formati di documenti specifici di un dominio all'elaborazione scalabile su migliaia di pagine contemporaneamente. Il risultato finale è undatabase vettoriale ricco di conoscenzeche alimenta la ricerca, l'analisi o i modelli linguistici di grandi dimensioni condati accurati e ricchi di contesto.
Garantire prestazioni scalabili e affidabilità
Progettare l'elaborazione di documenti su scala aeronautica significa gestire entrambielevata produttività e alta affidabilitàDal punto di vista della produttività, come notato, la nostra intelligenza artificiale documentale può acquisire ed elaborare documenti in parallelo, con successoelaborazione di 1.000 pagine contemporaneamenteNei recenti test sul campo, file-q7xvjvhip1lffe4hbnkuac. Questo risultato è stato ottenuto con un approccio di scalabilità orizzontale: più lavoratori di estrazione operano simultaneamente su diversi batch di pagine. Il sistema è cloud-native e può scalare automaticamente con il carico, il che significa che, indipendentemente dal fatto che si abbiano 100 o 100.000 pagine da analizzare, può allocare le risorse per soddisfare la domanda. Per un team di intelligenza artificiale, questa scalabilità si traduce in tempi di attesa minimi tra l'inserimento dei dati e l'analisi, un aspetto fondamentale quando, ad esempio, è necessario integrare rapidamente la libreria di documentazione di un nuovo aeromobile nella piattaforma di analisi.
L’affidabilità non deriva solo dalla precisione pura e semplice, ma anchecatturare correttamente la struttura e il contesto. Per esempio, acquisizione della struttura del documentogarantisce che, quando i dati vengono utilizzati a valle, si conosca il contesto. Se una ricerca vettoriale restituisce uno snippet relativo a "valore di coppia: 50 Nm", il sistema sa da quale manuale di manutenzione e sezione proviene, e può recuperare l'intera sezione o l'immagine della pagina su richiesta. Questo è prezioso per la convalida e per garantire agli utenti finali la fiducia nell'output dell'IA: possono sempre fare riferimento allo snippet del documento originale utilizzato dall'IA. Gli output strutturati della nostra pipeline includono questi marcatori contestuali per impostazione predefinita.
Inoltre, la soluzione è stata testata su varianti di documenti reali. I documenti aeronautici possono essere disordinati: scansioni con timbri, scrittura a mano o layout leggermente diversi tra i produttori. L'intelligenza artificiale per i documenti utilizzaOCR d'insieme(combinando più motori OCR e un meccanismo di voto) quando si tratta di scansioni rumorose e utilizza regole di convalida (come controlli di checksum sui codici articolo, controlli del formato della data, ecc.) per rilevare eventuali anomalie di estrazione. Ciò significa che anche quando si superano i limiti di throughput, il sistema mantiene un elevato livello di accuratezza. Nei benchmark interni con i computer portatili Boeing, l'accuratezza dei caratteri OCR è stata misurata a99,9%Sui documenti con un livello di testo preesistente, e solo marginalmente inferiore sulle immagini scansionate, grazie a modelli OCR avanzati. Acquisendo una struttura specifica per dominio (come l'indice dei manuali o le sezioni dei registri), il sistema può anche suddividere e correggere gli errori in modo elegante: ad esempio, se una pagina è di qualità particolarmente scadente, viene isolata e segnalata anziché interrompere l'elaborazione di un intero batch.
Per i team di ingegneria dell'intelligenza artificiale, queste funzionalità eliminano un grosso problema: potete fidarvi dei dati provenienti dalla pipeline dei documenti. Non dovrete più occuparvi di correggere errori OCR o di scrivere espressioni regolari ad hoc per ogni nuovo tipo di documento. L'attenzione può invece spostarsi sulla creazione di potenti applicazioni di intelligenza artificiale (come modelli di manutenzione predittiva, creazione di knowledge graph o strumenti di auditing della conformità) su questo affidabile livello di dati.
L'impatto sull'intelligenza artificiale a valle: RAG, LLM e ricerca
Vale la pena sottolineare nuovamente come questa estrazione ad alta precisione alimenta le attività di intelligenza artificiale a valle. ConsiderareGenerazione aumentata dal recupero (RAG): in questo caso, un modello linguistico di grandi dimensioni (LLM) viene integrato con documenti o frammenti pertinenti estratti da una knowledge base. Se la knowledge base è un database di vettori di documenti aeronautici creato tramite un'estrazione approssimativa, l'LLM potrebbe ricevere testo irrilevante o errato, generando una risposta imprecisa o allucinata. Al contrario, alimentare l'LLM conframmenti puliti e accuratiGrazie alla nostra pipeline di intelligenza artificiale documentale, il modello è in grado di generare risposte basate sulla verità. Abbiamo osservato che, aumentando l'accuratezza a livello di campo oltre il 98%, miglioriamo significativamente la precisione dei risultati di recupero (meno corrispondenze false) e, di conseguenza, la qualità delle risposte in un contesto di domande e risposte in ambito aeronautico. In sostanza, l'LLM può concentrarsi sul suo compito di comprendere e formulare le risposte, anziché doversi occupare internamente di input confusi. Il risultato è un'assistenza AI molto più affidabile per ingegneri e decisori.
La stessa logica si applica alla semplice ricerca semantica o ai sistemi di domande e risposte che non implicano la generazione. Ad esempio, una compagnia aerea potrebbe costruire unportale di ricercaPer consentire ai tecnici di manutenzione di consultare registri di riparazione o manuali precedenti. Se l'indice alla base di tale ricerca si basa su dati estratti accuratamente, i risultati della ricerca sono affidabili: i record restituiti contengono effettivamente i termini di ricerca o le informazioni pertinenti. In caso contrario, la ricerca potrebbe tralasciare documenti critici (basso richiamo) o restituire documenti errati (falsi positivi), indebolendo la fiducia dell'utente. L'estrazione ad alta precisione garantisce che, quando si cerca "conformità AD pompa carburante", si ottenga effettivamente il documento pertinente della Direttiva di Aeronavigabilità e i relativi registri di conformità, non un mucchio di rumore di fondo.
Non importa quanto siano avanzati i tuoi modelli di intelligenza artificiale, anche se utilizzi un trasformatore all’avanguardia da 175 miliardi di parametri,i loro output possono essere fuorviati da dati di input erratiNel contesto dell'aviazione, dove la sicurezza e la conformità alle normative sono in gioco, questo non è solo un piccolo inconveniente; è un rischio serio. Ecco perché insistiamo su un livello di estrazione di alto livello. Agisce comeunica fonte di verità, convertendo i tuoi documenti non strutturati in un archivio di conoscenze pulito, interrogabile e pronto per l'intelligenza artificiale.
Conclusione: gettare le basi per il successo dell'intelligenza artificiale di livello aeronautico
Per i responsabili dell'intelligenza artificiale e i team tecnici del settore aeronautico, il messaggio è chiaro:investire nell'accuratezza dei dati all'inizio del tuo processo di intelligenza artificialeI documenti aeronautici complessi e di grandi volumi rappresentano una formidabile fonte di informazioni, ed estrarne i dati con una fedeltà pressoché perfetta è l'unico modo per renderli accessibili ai vostri sistemi di intelligenza artificiale. Risparmiare sulla qualità dell'estrazione è un falso risparmio; qualsiasi risparmio verrà vanificato da scarse prestazioni dell'intelligenza artificiale in futuro o, peggio ancora, dalla perdita di informazioni cruciali a causa di un punto dati errato. Implementando un'intelligenza artificiale documentale specializzata nel settore aeronautico con una precisione di circa il 98-99%, si creano solide basi per tutte le applicazioni a valle, dalla manutenzione predittiva all'ottimizzazione della flotta, fino all'audit di conformità e agli assistenti intelligenti.
In sintesi, L'intelligenza artificiale documentale ad alta precisione è il fulcro dell'intelligenza artificiale di livello aeronauticoTrasforma montagne di documenti non strutturati in dati affidabili e strutturati. Con questo in atto, il tuoLLM, grafici della conoscenza e dashboard di analisipuò decollare, fornendo informazioni accurate e fruibili che promuovono la sicurezza e l'efficienza delle operazioni. Senza di essa, anche l'IA più potente inciamperà in input instabili. Con l'adozione della trasformazione digitale e dell'IA da parte dell'industria aeronautica, chi si basa su un'estrazione dati pulita e precisa avrà un vantaggio decisivo. È come avere una bussola ultra-affidabile prima di un volo: non si decollerebbe senza, e allo stesso modo, nessun percorso di IA dovrebbe iniziare senza dati affidabili. Integrando una soluzione di IA documentale ad alta precisione nella tua pipeline, completa di modelli ottimizzati per il dominio, OCR robusto e integrazione perfetta con database vettoriali, garantisci che le tue iniziative di IA per l'aviazione siano pronte al decollo con sicurezza e precisione.
Tendenze nella manutenzione aeronautica che potrebbero acquisire slancio in circostanze incerte
Gli aerei rimangono in servizio più a lungo, le catene di approvvigionamento sono una polveriera e la tecnologia si evolve da un giorno all'altro. Scopri le tendenze di manutenzione che stanno prendendo piede e cosa significano per gli operatori che cercano di rimanere operativi e redditizi.

April 10, 2026
Mission Control: infrastruttura di intelligence ad alte prestazioni per decisioni mission‑critical alla massima velocità
Ogni leader con cui parlo, che sia nell’aerospazio, nella manifattura o nell’edilizia, mi dice la stessa cosa:
I nostri sistemi stanno diventando sempre più intelligenti, ma le nostre decisioni non stanno diventando più rapide o più sicure al ritmo richiesto dalle operazioni.
Nei contesti ad alta integrità, lo spazio tra dati e decisioni è il punto in cui il rischio si accumula. Man mano che le operazioni diventano più complesse, distribuite e sensibili al fattore tempo, le organizzazioni hanno bisogno di sistemi di intelligence non solo rapidi ma anche verificabili, deterministici e sicuri per progettazione.
Questa è la filosofia ingegneristica alla base di Mission Control, la nostra infrastruttura di intelligence ad alte prestazioni, progettata per una velocità decisionale in tempo reale, verificabile e crittograficamente sicura.

October 2, 2025
Scelta delle parti giuste dell'aeromobile con analisi della tolleranza ai danni
Il futuro della sicurezza aerea è tutto nei componenti. Componenti autentici e tracciabili garantiscono alle flotte la massima tolleranza ai danni e prestazioni ottimali, per la massima sicurezza ed efficienza negli approvvigionamenti.

September 30, 2025
Come entrare in nuovi mercati dell'aviazione: la guida completa per i fornitori di componenti
Vuoi entrare in nuovi mercati dell'aviazione? Scopri come i fornitori possono analizzare la domanda, gestire i componenti PMA e costruire la fiducia delle compagnie aeree. Una guida completa per la crescita globale.

