Zet AI‑inzichten om in gerichte actie
Document-AI van luchtvaartkwaliteit. Precisie die presteert.
juni 11, 2025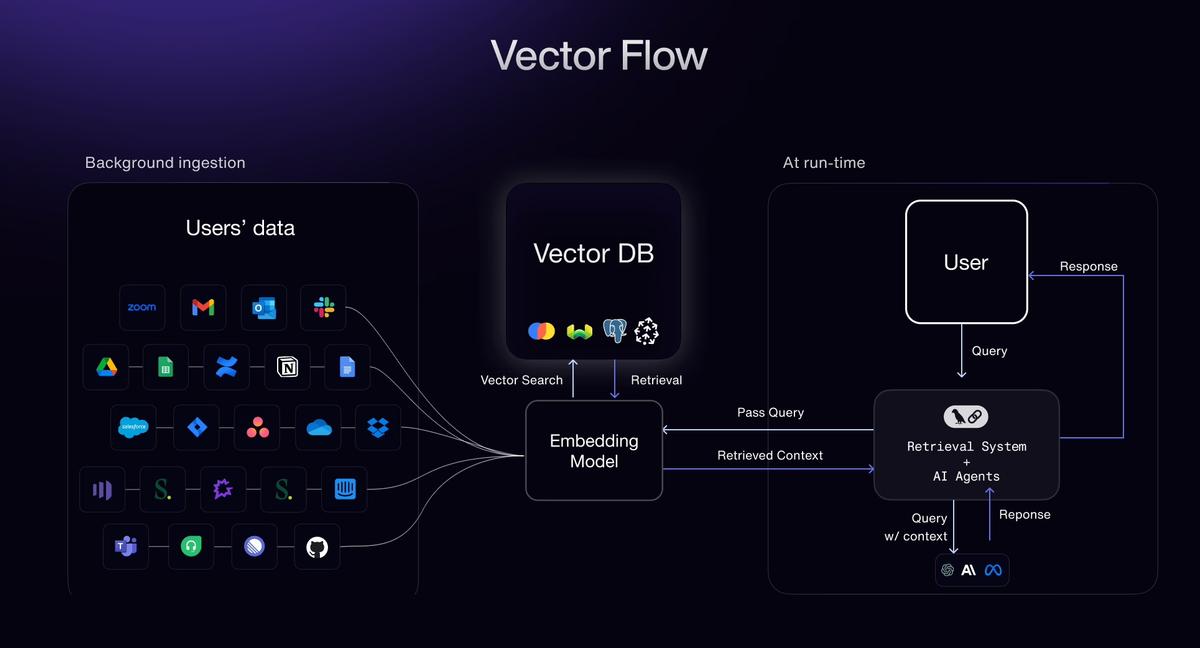
Inleiding: De stortvloed aan documenten in de luchtvaart en de noodzaak tot nauwkeurigheid
De luchtvaartindustrie wordt overspoeld met cruciale documenten – luchtwaardigheidscertificaten, geïllustreerde onderdelencatalogi (IPC's), onderhoudshandleidingen, FAA-servicebulletins/luchtwaardigheidsrichtlijnen, logboeken en meer. Deze ongestructureerde, omvangrijke documenten vormen de levensader van de luchtvaart en de naleving ervan. Zo kan één enkel Amerikaans commercieel vliegtuig tot wel7.500 pagina's nieuwe documenten per jaarom te voldoen aan de eisen van DOT en FAA. Ervoor zorgen dat AI-systemen deze berg aan data betrouwbaar kunnen interpreteren en gebruiken, is niet onderhandelbaar. In de bouwAI van luchtvaartkwaliteit, één principe springt eruit:De kwaliteit van de AI-uitkomsten is slechts zo goed als de nauwkeurigheid van de onderliggende data-extractieMet andere woorden, als de extractie van uw documentgegevens gebrekkig is, zal zelfs het meest geavanceerde AI-model die fouten verspreiden – een klassiek scenario van "garbage in, garbage out". AI-managers en technische teams moeten daarom prioriteit geven aanextractie van documentgegevens met hoge precisieals basis voor elke AI-pijplijn in de luchtvaart.
Ongestructureerde data in de luchtvaart: uitdagingen en noodzaak
Luchtvaartbedrijven zijn voor alles, van naleving van regelgeving tot dagelijkse bedrijfsvoering, afhankelijk van ongestructureerde documenten. Een paar voorbeelden:
- Regelgevende documenten:Luchtwaardigheidscertificaten, FAAServicebulletins (SB) En Luchtwaardigheidsrichtlijnen (AD)Bulletins, veiligheidscertificeringen en incidentenrapporten zijn verplicht en worden regelmatig gecontroleerd. Onjuiste gegevens kunnen leiden tot overtredingen van de regelgeving of tot vliegtuigen die aan de grond moeten blijven.
- Technische handleidingen: Onderhoudshandleidingen En IPC'sBevatten complexe onderdeelnummers, assemblageschema's en procedures waar ingenieurs en monteurs op vertrouwen. Deze beslaan vaak duizenden pagina's en komen in verschillende formaten (gescande pdf's, oude afdrukken), waardoor geautomatiseerde parsing lastig is.
- Operationele logboeken:Pilotlogboeken, onderhoudslogboeken en werkorders leggen continue operationele gegevens vast. Ze zijn meestal vrij van vorm en handgeschreven of getypt, wat de extractie ervan extra complex maakt.
- Inkoop- en inventarisdocumenten:Geïllustreerde onderdelencatalogi en stuklijsten, offerteaanvragen (RFQ's), inkooporders en garantiebewijzen worden gebruikt voor de inkoop van onderdelen en het voorraadbeheer. Fouten bij het extraheren van onderdeelnummers of aantallen kunnen leiden tot kostbare fouten in de voorraad.
Omgaan met ditdocumentenvloedis een uitdaging omdat de data ongestructureerd is – gevangen in beschrijvingen, tabellen en formulieren in natuurlijke taal. Naar schatting80% van de bedrijfsgegevens is ongestructureerd, verstopt in pdf's, e-mails en gescande formulieren. Luchtvaartbedrijven kennen dit probleem maar al te goed: volgens IDC kunnen werknemers zo'n 30% van hun tijd besteden aan het zoeken naar en consolideren van informatie in documenten. De gevolgen van slechte datakwaliteit zijn ernstig – IBM schat dat slechte data de Amerikaanse economie ongeveer $ 100.000 kost.$3,1 biljoen per jaarIn de luchtvaart is de inzet nog hoger: verkeerd gearchiveerde of verkeerd geïnterpreteerde onderhoudsgegevens kunnen een vloot aan de grond houden, en een onjuist onderdeelnummer kan leiden tot een mislukte reparatie of een veiligheidsrisico. Documenten met een groot volume en hoge inzet vereisen een uiterst nauwkeurige extractie.
Garbage In, Garbage Out: Waarom nauwkeurige extractie belangrijk is
Moderne AI-modellen – of het nu gaat om eenLLM (Groot Taalmodel)Het beantwoorden van onderhoudsvragen of een anomaliedetectiesysteem dat nalevingsproblemen signaleert – zijn slechts zo goed als de data die erin wordt ingevoerd. Als een OCR-engine "O-ring onderdeel 65-45764-10" verkeerd interpreteert als "O-ring onderdeel 65-45764-1O" (waardoor een nul voor een 'O' wordt aangezien), kan een AI-systeem de kritieke onderdeelhistorie niet vinden, of erger nog, een onjuiste aanbeveling geven. Zeer nauwkeurige data-extractie is niet alleen een leuke extra; het is eenvoorwaarde voor een nauwkeurige AI-uitkomstin de luchtvaart. Dit geldt vooral voorophaling-versterkte generatie (RAG)pipelines en zoektoepassingen. In een RAG-opstelling wordt een LLM zoals GPT-4o aangevuld met feitelijke fragmenten uit uw documentendatabase. Als deze fragmenten onjuist of met ontbrekende context worden geëxtraheerd, zal de LLM onvermijdelijk foutieve antwoorden opleveren, ongeacht hoe geavanceerd of groot het model is. Evenzo zullen zoek- en analysesystemen onjuiste resultaten opleveren als de onderliggende index is gevoed met ruis. Kortom,De prestaties van downstream AI nemen snel af wanneer de nauwkeurigheid van upstream-extractie afneemt– ongeacht de grootte of het vermogen van het model. Het garanderen van een bijna-grondwaarheidsgetrouwe nauwkeurigheid tijdens de data-invoerfase is de enige manier om te vertrouwen op de inzichten die later door uw AI-oplossingen voor de luchtvaart worden gegenereerd.
Verder dan generieke tools: het pleidooi voor luchtvaartspecifieke document-AI
Niet alle documentverwerking is gelijk. Generieke AI-tools voor documenten (zoals die vaak geoptimaliseerd zijn voor facturen of eenvoudige formulieren) worstelen met decomplexiteit van luchtvaartdocumentenLuchtvaartdocumenten bevatten vaak dichte tabellen, samenstellingen met meerdere niveaus, gespecialiseerde terminologie (onderdeelcodes, ATA-hoofdstukken, enz.) en zelfs handgeschreven annotaties. Een universele OCR of formulierparser mist nuances – zo kan een pagina met een geïllustreerde onderdelencatalogus worden gelezen als een wirwar aan tekst, terwijl een model dat is opgeleid in de luchtvaart weet hoe hij onderdeelnummers, nomenclatuur, effectiviteitsbereiken en samenstellingshiërarchieën moet segmenteren.
Domeinspecifieke precisie:Onze op de luchtvaart gerichte Document AI is vanaf de grond af ontworpen voor deze complexiteit. Het behandelt een IPC-pagina niet als zomaar een tabel – het begrijpt destructuur en relaties op deelniveauBij het extraheren van bijvoorbeeld een Boeing IPC legt het model deUitsplitsing van onderdelen per regel inclusief ouder-kind-assemblages(bijv. herkennen dat onderdeel 65-45764-10 een component is onder bovenliggende assembly 69-33484-2, die op zijn beurt weer onder een hogere assembly 65-38196-5 valt). Dit behoud van hiërarchie is cruciaal: het betekent dat uw AI niet alleen de onderdelen kent, maar ook hoe ze in het vliegtuig passen. Generieke tools bieden dit niveau van contextuele structurering simpelweg niet.


Nauwkeurigheid Leiderschap:Gespecialiseerde training levert superieure nauwkeurigheid. Onze Document AI bereiktmeer dan 98% nauwkeurigheid op veldniveau, En 99%+ op karakterniveauop luchtvaartdocumenten. Met andere woorden, meer dan 98 van de 100 geëxtraheerde velden (zoals "Onderdeelnummer", "Serienummer", "Installatiedatum", enz.) zijn exact correct – een percentage dat de meeste standaard OCR-services voor dit soort documenten niet kunnen evenaren. Een nauwkeurigheid van meer dan 99% op tekenniveau betekent dat fouten zelfs bij lange onderdeelnummers of alfanumerieke codes uiterst zeldzaam zijn. Dit precisieniveau is het resultaat van domeinspecifieke OCR-modellen, NLP-validatiecontroles en continue finetuning van luchtvaartgegevens. Het overtreft ruimschoots wat een generieke factuurverwerker zou bereiken wanneer deze bijvoorbeeld een onderhoudslogboek of een FAA-nalevingsformulier gebruikt.In deze niche is onze oplossing de leider op het gebied van nauwkeurigheid, speciaal gebouwd voor de eisen van de luchtvaart.
Bovendien, nalevingsmetagegevensen formulierspecifieke details worden elegant verwerkt. In tegenstelling tot een generieke tool die een niet-standaard formulierveld overslaat, weet een AI voor luchtvaartdocumenten velden zoals "Typecertificaatnummer" uit een luchtwaardigheidscertificaat of de sectie "Effectiviteit" uit een servicebulletin te extraheren, omdat deze cruciaal zijn in de context. Door te focussen opdetails op onderdeelniveau, context op formulierniveau en regelgevende metadataDe oplossing zorgt ervoor dat er geen kritieke gegevens achterblijven. Deze focus op luchtvaartcomplexiteit is wat gespecialiseerde Document AI onderscheidt: het spreekt de taal van luchtvaartdocumenten, terwijl generieke modellen taalgebonden blijven.
Luchtvaartdocument AI in cijfers
Om de prestaties en mogelijkheden van onze Document AI van luchtvaartkwaliteit te illustreren, vindt u hier enkele belangrijke statistieken en functies:
- Nauwkeurigheid op veldniveau > 98%– Essentiële gegevensvelden (onderdeel-ID's, datums, compliance-selectievakjes, enz.) worden correct vastgelegd met een nauwkeurigheid van meer dan 98%, zelfs in verschillende documentindelingen. Dit vermindert de noodzaak voor menselijke correctie aanzienlijk.
- OCR-nauwkeurigheid op tekenniveau > 99%– Dankzij robuuste OCR (en het gebruik van native tekstlagen indien beschikbaar) verloopt de tekenherkenning vrijwel foutloos. Zo worden bijvoorbeeld serienummers of onderdeelcodes van tientallen tekens exact gereproduceerd, waardoor belangrijke identificatiegegevens behouden blijven.
- Boeing IPC-ondersteuning (assemblage vastgelegd)– Ondersteunt momenteelBoeing IPC-documenten, waarbij elk regelartikel wordt geanalyseerd. De extractor begrijpt het IPC-schema: hij haalt velden op zoals figuurnummer, artikelnummer, onderdeelnummer, nomenclatuur, eenheden per assemblage en effectiviteitsbereiken. Cruciaal is dat hijlegt de relaties tussen ouders en kinderen vast, waarbij de hiërarchie van onderdelen in elke assembly wordt gereconstrueerd. Dit betekent dat uw AI vragen kan beantwoorden over hoe componenten genest zijn of alle subonderdelen binnen een bepaalde assembly kan identificeren – mogelijkheden die met generieke parsers niet haalbaar zijn.
- Schaal – 1.000 pagina's gelijktijdig– Het systeem is in het veld getest op eeningestiedoorvoer van 1k pagina's parallel, door 5 gelijktijdige batches van elk 200 pagina's uit te voeren - file-q7xvjvhip1lffe4hbnkuac. In de praktijk betekent dit dat een hele bibliotheek met handleidingen of een jaar aan logboeken binnen enkele minuten verwerkt kan worden. Hoge doorvoer zorgt ervoor dat zelfsachterstanden met een hoog volumeof realtime documentstromen (zoals een plotselinge stort van nieuwe onderhoudsgegevens) kunnen worden verwerkt zonder dat het systeem vastloopt.
- Realtime documentsplitsing en -classificatie– Grote PDF-handleidingen of gecombineerde documentensets worden automatischopgesplitst in afzonderlijke documenten of sectiesvoor gerichte verwerkingfile-q7xvjvhip1lffe4hbnkuac. Een AI-gebaseerdedocumentclassificatorBepaalt eerst het documenttype (bijvoorbeeld het onderscheiden van een geïllustreerde onderdelencatalogus van een onderhoudshandleiding of een luchtwaardigheidscertificaat) om het naar de juiste extractie-pipeline te routeren: file-q7xvjvhip1lffe4hbnkuac. Deze classificatie is bijna 100% terug te halen, waardoor geen enkel document verkeerd wordt geïdentificeerd of overgeslagen. Splitsing en classificatie gebeuren direct, waardoor continue feeds van verschillende documenttypen nauwkeurig en in realtime kunnen worden verwerkt.
- Gestructureerde output voor eenvoudige integratie– De geëxtraheerde data bestaat niet alleen uit ruwe tekst – ze wordt uitgevoerd als gestructureerde records (JSON, XML, enz.), compleet met metadata zoals documenttype, sectiekoppen en zelfs paginaverwijzingen.documentstructuur vastleggenbetekent dat u de context behoudt: elk datapunt weet waar het vandaan komt (pagina X van handleiding Y, sectie Z). Een dergelijke structuur is van onschatbare waarde bij het invoeren van de data in andere systemen of audits.
Kortom, de combinatie van ultrahoge nauwkeurigheid en domeinspecifieke functionaliteiten (zoals het vastleggen van de assemblagehiërarchie) maakt deze oplossing uniek in staat om luchtvaartdocumenten op grote schaal te verwerken. Laten we nu eens kijken hoe deze mogelijkheden kunnen worden geïntegreerd in een AI-pijplijn.
Technisch overzicht van de pijplijn: van documenten tot AI-klare data
Om een effectieveAI-pijplijn voor luchtvaartgegevens, raden we een gefaseerde aanpak aan. Hier is een overzicht van de pijplijn, van het invoeren van ruwe documenten tot het leveren van vectoren voor AI-modellen:
- Opname (PDF's en scans):Accepteer documenten van verschillende bronnen – of het nu gaat om scans met hoge resolutie, pdf's met ingesloten tekst of afbeeldingen. De pijplijn kangescande papieren dossiersen pas indien nodig geavanceerde OCR toe, of parseer tekst direct uit digitale PDF's (gebruikmakend van de tekstlaag voor een nauwkeurigheid van 99,9% indien beschikbaar). De opnamefase normaliseert bestandsformaten en plaatst documenten in de wachtrij voor verwerking. Deze is ontworpen om bulkuploads en streaming-inputs te verwerken, waarbij downstream-taken worden gestart zodra nieuwe bestanden binnenkomen (ondersteuning voor gebeurtenisgestuurde verwerking voor realtimesystemen).
- Classificatie:Vervolgens identificeert een AI-gestuurde classifier het type en doel van elk document (file-q7xvjvhip1lffe4hbnkuac). Het labelt documenten bijvoorbeeld als "Luchtwaardigheidscertificaat", "IPC – Boeing 737", "Onderhoudstaakkaart", "FAA AD Bulletin", enz. Deze stap is cruciaal omdat extractielogica vaak sjabloonspecifiek is. Hoge classificatienauwkeurigheid (met een recall van bijna 100%) zorgt ervoor dat elk document naar het juiste extractiemodel of de juiste regelset wordt geleid. Als een document meerdere secties bevat (bijvoorbeeld een samengevoegde PDF met verschillende formulieren), worden deze secties in deze fase ook op type gesegmenteerd.
- Geautomatiseerde splitsing:Grote handleidingen of PDF's die meerdere documenten bevatten, worden automatischopgesplitst in logische eenhedenfile-q7xvjvhip1lffe4hbnkuac. Een onderhoudshandleiding van 500 pagina's kan bijvoorbeeld worden gesplitst per hoofdstuk of taak, of een IPC PDF met meerdere secties wordt gesplitst per sectie/figuur. Op dezelfde manier wordt een stapel gescande logboekpagina's gesplitst in afzonderlijke pagina-afbeeldingen voor parallelle verwerking. Het splitsen van de invoer dient twee doelen:parallelle extractie(wat de verwerking enorm versnelt) en zorgt ervoor dat contextgrenzen worden gerespecteerd (zodat elk fragment onafhankelijk kan worden behandeld voor downstream-taken zoals embedding). Dit gebeurt in realtime; zodra een groot bestand wordt verwerkt, begint het systeem het te splitsen en worden pagina's/secties gelijktijdig naar de extractiefase gestuurd.
- Hoge nauwkeurigheid extractie:Dit is de kernfase waarin de Document AI-extractie-engine in werking treedt. Met behulp van een combinatie van sjabloonspecifieke OCR-modellen, NLP-parsers en validatiecontroles kan het systeemextraheert gestructureerde gegevens met een nauwkeurigheid van luchtvaartkwaliteitBelangrijke velden worden geselecteerd op basis van het documenttype: voor een IPC: onderdeelnummers, nomenclatuur, assemblagereferenties, enz.; voor een onderhoudslogboek: data, uitgevoerde acties, mechanische notities; voor een regelgevingsformulier: certificaat-ID's, vervaldata, handtekeningen, enz.Contextuele integriteitblijft behouden: de uitvoer behoudt de sectie of tabel waaruit een veld afkomstig is, en velden zijn gekoppeld (bijvoorbeeld alle regelposten onder een figuur of alle items onder een bepaalde datum). Het resultaat is een gestructureerde dataset die de informatie in het document weergeeft. Met een nauwkeurigheid van >98% op veldniveau is er minimale menselijke controle nodig en kunnen eventuele vertrouwensdalingen of afwijkingen worden gemarkeerd voor inspectie.
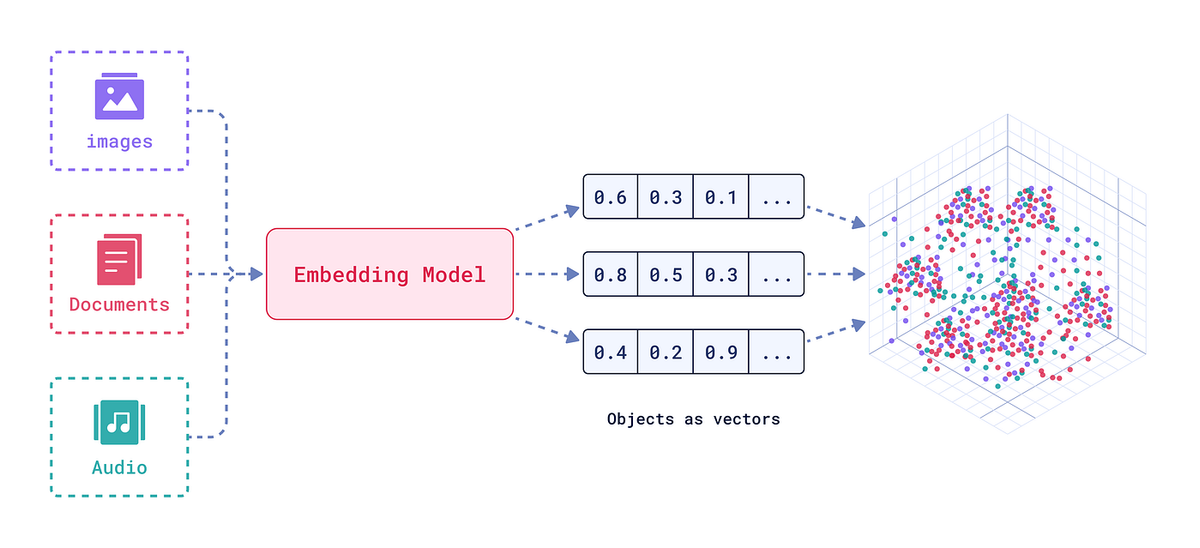
- Insluiten en vectoriseren:Zodra tekstuele data is geëxtraheerd, kan deze worden omgezet in vector-embeddings voor AI-gebruik. De pijplijn integreert metbelangrijke inbeddingsmodellen– u kunt uw favoriete model (bijv. OpenAI's tekst-embedding API's, Sentence-BERT of andere transformer-gebaseerde encoders) gebruiken om elk documentfragment of datarecord om te zetten in een hoogdimensionale vector. We ondersteunen aangepastechunking-strategieënHier: u kunt bijvoorbeeld elke alinea of sectie afzonderlijk insluiten om het ophalen van informatie stroomafwaarts te optimaliseren. Het systeem kan grote tekstvelden (zoals lange handmatige alinea's) automatisch opdelen in fragmentgroottes die ideaal zijn voor uw LLM-contextvenster, of u kunt chunkingregels definiëren (per zin, per subsectie, enz.). Deze flexibiliteit zorgt ervoor dat de insluitingen zinvolle stukjes informatie vastleggen zonder de context af te breken. Aan het einde van deze stap wordt elk document (of elke documentsectie) weergegeven door een of meer insluitingsvectoren, meestal vergezeld van metadata (document-ID, sectietitel, bronvermelding).
- Vectordatabase-injectie:Ten slotte zijn de vectoren en metadatageïnjecteerd in een vectordatabasenaar keuze. De oplossing werkt direct met populaire vectorwinkels zoalsRedis(met RediSearch-vectoren),Dennenappel, of Elastisch(onder andere de vectorzoekfunctie van Elastic). Dit betekent dat de geëxtraheerde kennis uit documenten direct doorzoekbaar is via een gelijkeniszoekfunctie of bruikbaar is voor het genereren van gegevens met behulp van retrieval-augmented generation. Zo kunt u nu uw documentcollectie doorzoeken met natuurlijke taal en de meest relevante fragmenten in de vectorruimte ophalen, of uw AI-assistent kan relevante secties uit de onderhoudshandleiding ophalen om een vraag te beantwoorden. De pipeline zorgt ervoor dat samen met elke vector de originele tekst en documentreferentie worden opgeslagen, zodat u, wanneer een vectormatch wordt gevonden, deze kunt herleiden naar het brondocument/de bronpagina. Realtime updates worden ook ondersteund: als er nieuwe documenten binnenkomen, kunnen de embeddings direct worden ingevoegd, zodat de vectordatabase en de kennisbank van uw AI up-to-date blijven.
Deze pijplijn zorgt voor een soepele doorstroming van ruwe, ongestructureerde input naar AI-ready, gestructureerde informatie. Elke fase is geoptimaliseerd voor gebruik in de luchtvaart – van het begrijpen van domeinspecifieke documentformaten tot het opschalen van de verwerking over duizenden pagina's tegelijk. Het eindresultaat is eenkennisrijke vectordatabasedie zoeken, analyses of grote taalmodellen aanstuurt metnauwkeurige, contextrijke gegevens.
Zorgen voor schaalbare prestaties en betrouwbaarheid
Bij het ontwerpen van een architectuur voor documentverwerking op luchtvaartschaal moet u rekening houden met zowelhoge doorvoer en hoge betrouwbaarheidAan de doorvoerkant kan onze Document AI, zoals opgemerkt, documenten parallel opnemen en verwerken – met succesgelijktijdig verwerken van 1.000 pagina'sin recente veldtestsfile-q7xvjvhip1lffe4hbnkuac. Dit werd bereikt met een horizontale schaalbenadering: meerdere extractiewerkers die tegelijkertijd op verschillende batches pagina's werken. Het systeem is cloud-native en kan automatisch schalen met de belasting, wat betekent dat het resources kan toewijzen om aan de vraag te voldoen, of u nu 100 of 100.000 pagina's moet parseren. Voor een AI-team vertaalt deze schaalbaarheid zich in een minimale wachttijd tussen data-invoer en inzicht – cruciaal wanneer u bijvoorbeeld snel de documentatiebibliotheek van een nieuw vliegtuig in uw analyseplatform moet integreren.
Betrouwbaarheid komt voort uit meer dan alleen pure nauwkeurigheid; het gaat ook omstructuur en context correct vastleggen. Bijvoorbeeld, documentstructuur vastleggenZorgt ervoor dat u de context kent wanneer de data downstream wordt gebruikt. Als een vectorzoekopdracht een fragment oplevert over "koppelwaarde: 50 Nm", weet het systeem uit welke onderhoudshandleiding en sectie dat afkomstig is en kan het de volledige sectie of pagina-afbeelding op aanvraag ophalen. Dit is van onschatbare waarde voor validatie en voor eindgebruikers die de AI-uitvoer willen vertrouwen – ze kunnen altijd teruggrijpen naar het originele documentfragment dat de AI heeft gebruikt. De gestructureerde uitvoer van onze pijplijn bevat deze contextuele markeringen standaard.
Bovendien is de oplossing getest op documentvariaties in de praktijk. Luchtvaartdocumenten kunnen rommelig zijn – scans met stempels, handschrift of licht afwijkende lay-outs tussen fabrikanten. De Document AI maakt gebruik vanensemble-OCRbenaderingen (combinatie van meerdere OCR-engines en een stemmechanisme) bij het verwerken van scans met veel ruis, en het maakt gebruik van validatieregels (zoals checksumcontroles op onderdeelnummers, controles van datumnotaties, enz.) om eventuele extractieafwijkingen op te sporen. Dit betekent dat het systeem, zelfs bij het overschrijden van de doorvoerlimieten, een hoge nauwkeurigheidsdrempel hanteert. In interne benchmarks met Boeing IPC's werd de OCR-tekennauwkeurigheid gemeten op99,9%op documenten met een bestaande tekstlaag, en slechts marginaal lager op puur gescande afbeeldingen dankzij geavanceerde OCR-modellen. Door domeinspecifieke structuren vast te leggen (zoals inhoudsopgaven van handleidingen of secties in logboeken), kan het systeem fouten ook netjes opsplitsen en herstellen – bijvoorbeeld als één pagina van bijzonder slechte kwaliteit is, wordt deze geïsoleerd en gemarkeerd in plaats van een hele batch te verstoren.
Voor AI-engineeringteams nemen deze mogelijkheden een groot probleem weg: u kunt vertrouwen op de data die uit uw documentpijplijn komt. U hoeft geen OCR-fouten op te lossen of ad-hoc regexes te schrijven voor elk nieuw documenttype. U kunt zich nu richten op het bouwen van krachtige AI-applicaties (zoals predictieve onderhoudsmodellen, het maken van kennisgrafieken of tools voor compliance-audits) op basis van deze betrouwbare datalaag.
De impact op downstream AI: RAG, LLM's en zoeken
Het is de moeite waard om nogmaals te benadrukken hoe deze uiterst precieze extractie downstream AI-taken voedt.Retrieval-Augmented Generation (RAG): hier wordt een groot taalmodel (LLM) aangevuld met relevante documenten of fragmenten die uit een kennisbank zijn gehaald. Als uw kennisbank een vectordatabase voor luchtvaartdocumenten is die is opgebouwd uit slordige extractie, kan de LLM irrelevante of onjuiste tekst krijgen, wat kan leiden tot een onnauwkeurig of hallucinerend antwoord. Daarentegen kan het voeden van de LLM metschone, nauwkeurige fragmentenDankzij onze Document AI-pijplijn kan het model antwoorden genereren die gebaseerd zijn op waarheid. We hebben geconstateerd dat door de nauwkeurigheid op veldniveau boven de 98% te brengen, we de nauwkeurigheid van de resultaten aanzienlijk verbeteren (minder foutieve matches) en daarmee de kwaliteit van de antwoorden in een vraag-en-antwoordsessie in de luchtvaart. In wezen kan de LLM zich concentreren op het begrijpen en formuleren van antwoorden, in plaats van intern te worstelen met onleesbare input. Het resultaat is een veel betrouwbaardere AI-ondersteuning voor ingenieurs en besluitvormers.
Dezelfde logica geldt voor eenvoudige semantische zoek- of vraag-antwoordsystemen die geen generatie vereisen. Een luchtvaartmaatschappij zou bijvoorbeeld eenzoekportaalvoor onderhoudstechnici om oude reparatiegegevens of handleidingen te raadplegen. Als de index achter die zoekopdracht is gebaseerd op nauwkeurig geëxtraheerde gegevens, zijn de zoekresultaten betrouwbaar – de geretourneerde records bevatten daadwerkelijk de zoektermen of relevante informatie. Zo niet, dan kan de zoekopdracht cruciale documenten missen (lage recall) of onjuiste documenten aan het licht brengen (valspositieve resultaten), wat het vertrouwen van de gebruiker ondermijnt. Zeer nauwkeurige extractie zorgt ervoor dat wanneer u zoekt naar "brandstofpomp AD-naleving", u daadwerkelijk het relevante document met de luchtwaardigheidsrichtlijn en de bijbehorende nalevingsgegevens krijgt, en niet een hoop ruis.
Hoe geavanceerd uw AI-modellen ook zijn – zelfs als u gebruikmaakt van een ultramoderne transformator met 175 miljard parameters –hun uitkomsten kunnen op een dwaalspoor worden gebracht door slechte invoergegevensIn de luchtvaart, waar veiligheid en naleving van regelgeving op het spel staan, is dit niet zomaar een klein ongemak; het is een ernstig risico. Daarom staan we erop dat er een extractielaag van de bovenste laag is. Deze fungeert als deenkele bron van waarheid, waarmee u uw ongestructureerde documenten omzet in een overzichtelijke, doorzoekbare en AI-geschikte kennisopslagplaats.
Conclusie: de basis leggen voor succes met AI op luchtvaartniveau
Voor AI-leiders en technische teams in de luchtvaartsector is de boodschap duidelijk:Investeer in datanauwkeurigheid aan het begin van uw AI-pijplijnGrote hoeveelheden complexe luchtvaartdocumenten vormen een formidabele bron van waarheid – en het met bijna perfecte betrouwbaarheid extraheren van de data is de enige manier om die waarheid voor uw AI-systemen te ontsluiten. Bezuinigen op de extractiekwaliteit is een valse besparing; eventuele besparingen worden later tenietgedaan door slechte AI-prestaties, of erger nog, een cruciaal inzicht dat gemist wordt door een onjuist datapunt. Door een op de luchtvaart gespecialiseerde Document AI met een nauwkeurigheid van ~98-99%+ te implementeren, creëert u een solide basis voor alle downstream-toepassingen, van voorspellend onderhoud en vlootoptimalisatie tot compliance-audits en intelligente assistenten.
Samenvattend,Hoogprecieze Document AI is de hoeksteen van AI op luchtvaartniveauHet verandert bergen ongestructureerd papierwerk in betrouwbare, gestructureerde gegevens. Met dat op orde, uwLLM's, kennisgrafieken en analysedashboardskan vliegen – het levert nauwkeurige, bruikbare inzichten die de veiligheid en efficiëntie van de operaties bevorderen. Zonder AI zal zelfs de krachtigste AI struikelen over de zwakke input. Nu de luchtvaartindustrie digitale transformatie en AI omarmt, zullen degenen die bouwen op een basis van schone, nauwkeurige data-extractie een doorslaggevend voordeel hebben. Het is alsof je een ultrabetrouwbaar kompas hebt voor een vlucht – je zou niet zonder opstijgen, en evenzo zou geen enkele AI-reis moeten beginnen zonder betrouwbare data. Door een zeer nauwkeurige Document AI-oplossing in uw pijplijn te integreren – compleet met domein-afgestemde modellen, robuuste OCR en naadloze integratie met vectordatabases – zorgt u ervoor dat uw AI-initiatieven in de luchtvaart met vertrouwen en precisie van start gaan.
Trends in luchtvaartonderhoud die in onzekere omstandigheden aan momentum kunnen winnen
Vliegtuigen blijven langer in gebruik, toeleveringsketens zijn een kruitvat en de technologie ontwikkelt zich van de ene op de andere dag. Ontdek de onderhoudstrends die aan populariteit winnen en wat ze betekenen voor exploitanten die in de lucht en winstgevend willen blijven.

April 10, 2026
Mission Control: High-performance intelligent infrastructuur voor missiekritische beslissingssnelheid
Elke leider met wie ik spreek in de luchtvaart, maakindustrie of bouw zegt hetzelfde:
Onze systemen worden slimmer, maar onze beslissingen worden niet sneller of veiliger in het tempo dat de operaties vereisen.
In omgevingen met hoge integriteit is de kloof tussen gegevens en beslissingen de plek waar risico’s zich opstapelen. Naarmate operaties complexer, meer verspreid en tijdkritischer worden, hebben organisaties intelligentesystemen nodig die niet alleen snel zijn, maar ook verifieerbaar, deterministisch en veilig-by-design.
Dit is de technische filosofie achter Mission Control, onze high‑performance intelligence‑infrastructuur, gebouwd voor realtime, controleerbare en cryptografisch beveiligde beslissingssnelheid.

October 2, 2025
De juiste vliegtuigonderdelen kiezen met schadetolerantieanalyse
De toekomst van luchtvaartveiligheid draait om de onderdelen. Authentieke, traceerbare onderdelen zorgen voor optimale schadetolerantie en prestaties van vloten, voor maximale veiligheid en inkoopefficiëntie.

September 30, 2025
Hoe u nieuwe luchtvaartmarkten betreedt: de complete gids voor onderdelenleveranciers
Betreedt u nieuwe luchtvaartmarkten? Ontdek hoe leveranciers de vraag kunnen analyseren, PMA-onderdelen kunnen beheren en vertrouwen kunnen opbouwen bij luchtvaartmaatschappijen. Een complete gids voor wereldwijde groei.

