Orquestre insights de IA em ações
IA de documentos de nível aeronáutico. Precisão que funciona.
junho 11, 2025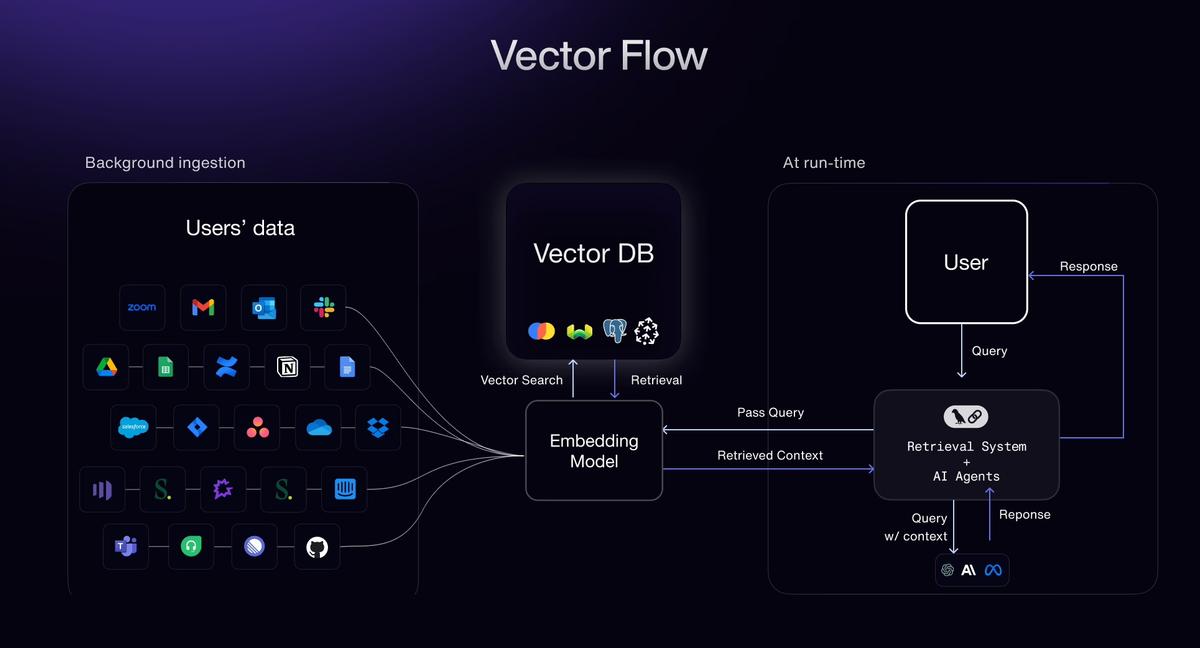
Introdução: O dilúvio de documentos da aviação e o imperativo da precisão
A indústria da aviação está inundada de documentos críticos – Certificados de Aeronavegabilidade, Catálogos Ilustrados de Peças (IPCs), manuais de manutenção, Boletins de Serviço/Diretrizes de Aeronavegabilidade da FAA, diários de bordo e muito mais. Esses documentos não estruturados e de alto volume são a essência das operações e da conformidade da aviação. Por exemplo, uma única aeronave comercial americana pode produzir até7.500 páginas de novos documentos por anopara atender aos requisitos do DOT e da FAA. Garantir que os sistemas de IA possam interpretar e utilizar essa montanha de dados de forma confiável é inegociável. Na construçãoIA de nível de aviação, um princípio se destaca:a qualidade dos resultados da IA depende da precisão da extração de dados subjacenteEm outras palavras, se a extração de dados do seu documento for falha, mesmo o modelo de IA mais avançado propagará esses erros – um cenário clássico de “entrada de lixo, saída de lixo”. Os líderes de IA e as equipes técnicas devem, portanto, priorizarextração de dados de documentos de alta precisãocomo a base de qualquer pipeline de IA de aviação.
Dados não estruturados na aviação: desafios e necessidades
Empresas de aviação dependem de documentos não estruturados para tudo, desde a conformidade regulatória até as operações diárias. Veja alguns exemplos:
- Documentos regulatórios:Certificados de aeronavegabilidade, FAABoletins de Serviço (SB) e Diretrizes de Aeronavegabilidade (DA)Boletins, certificações de segurança e relatórios de incidentes são obrigatórios e auditados com frequência. Qualquer informação incorreta pode resultar em violações de conformidade ou na paralisação da aeronave.
- Manuais Técnicos: Manuais de Manutenção e IPCsContêm números de peças, diagramas de montagem e procedimentos complexos nos quais engenheiros e mecânicos confiam. Muitas vezes, abrangem milhares de páginas e vêm em formatos variados (PDFs digitalizados, impressões antigas), dificultando a análise automatizada.
- Registros Operacionais:Diários de bordo de pilotos, registros de manutenção e ordens de serviço capturam dados operacionais contínuos. Geralmente, são de formato livre e manuscritos ou digitados, adicionando outra camada de complexidade à extração.
- Documentos de aquisição e estoque:Catálogos de peças ilustrados e listas de peças, solicitações de cotação (RFQs), ordens de compra e registros de garantia são usados para aquisição de peças e gestão de estoque. Erros na extração de números ou quantidades de peças podem levar a erros de inventário dispendiosos.
Lidando com issodilúvio de documentosé desafiador porque os dados não são estruturados – presos em descrições, tabelas e formulários de linguagem natural. Estima-se que80% dos dados empresariais não são estruturados, escondidos em PDFs, e-mails e formulários digitalizados. As empresas de aviação conhecem bem esse problema: de acordo com a IDC, os funcionários podem gastar cerca de 30% do seu tempo simplesmente pesquisando e consolidando informações em documentos. A consequência da baixa qualidade dos dados é grave – a IBM estimou que dados ruins custam à economia dos EUA cerca deUS$ 3,1 trilhões anualmenteNa aviação, os riscos são ainda maiores: registros de manutenção arquivados incorretamente ou mal interpretados podem paralisar uma frota, e um número de peça incorreto pode significar um reparo malsucedido ou um risco à segurança. Documentos de alto volume e alto risco exigem precisão de extração da mais alta ordem.
Lixo entra, lixo sai: por que a extração de precisão é importante
Modelos modernos de IA – seja umaLLM (Modelo de Linguagem Ampla)Responder a perguntas de manutenção ou um sistema de detecção de anomalias que sinaliza problemas de conformidade – são tão eficazes quanto os dados que são inseridos neles. Se um mecanismo de OCR interpretar incorretamente "O-ring part 65-45764-10" como "O-ring part 65-45764-1O" (confundindo um zero com um "O"), um sistema de IA pode não encontrar o histórico de peças críticas ou, pior, gerar uma recomendação incorreta. A extração de dados de alta precisão não é apenas algo útil; é umapré-requisito para qualquer resultado preciso de IAna aviação. Isto é especialmente verdadeiro parageração aumentada de recuperação (RAG)pipelines e aplicativos de busca. Em uma configuração RAG, um LLM como o GPT-4o é complementado com trechos factuais do seu banco de dados de documentos. Se esses trechos forem extraídos incorretamente ou com contexto ausente, o LLM inevitavelmente produzirá respostas incorretas, independentemente de quão sofisticado ou grande seja o modelo. Da mesma forma, sistemas de busca e análise fornecerão resultados falsos se o índice subjacente tiver sido alimentado com dados ruidosos. Em resumo,o desempenho da IA a jusante degrada-se rapidamente quando a precisão da extração a montante falha– independentemente do tamanho ou da capacidade do modelo. Garantir a precisão quase real na fase de ingestão de dados é a única maneira de confiar nos insights produzidos posteriormente por suas soluções de IA para aviação.
Além das ferramentas genéricas: o caso da IA em documentos específicos da aviação
Nem todo processamento de documentos é igual. Ferramentas genéricas de IA para documentos (o tipo frequentemente otimizado para faturas ou formulários simples) têm dificuldades com acomplexidade dos documentos de aviaçãoDocumentos de aviação frequentemente contêm tabelas densas, montagens multinível, terminologia especializada (códigos de peças, capítulos ATA, etc.) e até mesmo anotações manuscritas. Um OCR ou analisador de formulários universal não perceberá nuances – por exemplo, pode ler uma página de Catálogo de Peças Ilustrado como um amontoado de texto, enquanto um modelo treinado em aviação sabe como segmentar números de peças, nomenclatura, faixas de efetividade e hierarquias de montagens.
Precisão específica de domínio:Nossa IA de Documentos focada em aviação foi projetada do zero para essa complexidade. Ela não trata uma página IPC como qualquer tabela – ela entende oestrutura e relacionamentos em nível de parte. Por exemplo, ao extrair um IPC da Boeing, o modelo captura odetalhamento de peças de itens de linha, incluindo montagens pai-filho(por exemplo, reconhecendo que a peça 65-45764-10 é um componente sob o conjunto pai 69-33484-2, que por sua vez está sob um conjunto superior 65-38196-5). Essa preservação da hierarquia é crucial: significa que sua IA não apenas conhece as peças, mas também como elas se encaixam na aeronave. Ferramentas genéricas simplesmente não oferecem esse nível de estruturação contextual.


Liderança de Precisão:Treinamento especializado proporciona precisão superior. Nossa IA de Documentos alcançamais de 98% de precisão no nível de campo, e 99%+ no nível do personagemem documentos de aviação. Em outras palavras, mais de 98 de 100 campos extraídos (como "Número da Peça", "Número de Série", "Data de Instalação", etc.) estão exatamente corretos – uma taxa inatingível pela maioria dos serviços de OCR prontos para uso nesses tipos de documentos. Uma precisão em nível de caracteres superior a 99% significa que, mesmo em números de peça longos ou códigos alfanuméricos, os erros são extremamente raros. Esse nível de precisão é resultado de modelos de OCR específicos de domínio, verificações de validação de PLN e ajustes finos contínuos em dados de aviação. Ele supera em muito o que um processador de faturas genérico alcançaria ao analisar, por exemplo, um registro de manutenção ou um formulário de conformidade da FAA.Neste nicho, nossa solução é líder em precisão, construído especificamente para atender às demandas da aviação.
Além disso, metadados de conformidadee detalhes específicos do formulário são tratados com elegância. Ao contrário de uma ferramenta genérica que pode ignorar um campo de formulário não padrão, uma IA de Documentos de Aviação sabe extrair campos como "Número do Certificado de Tipo" de um Certificado de Aeronavegabilidade ou a seção "Eficácia" de um Boletim de Serviço, porque estes são cruciais no contexto. Ao focar emdetalhes em nível de peça, contexto em nível de formulário e metadados regulatórios, a solução garante que nenhum dado crítico seja deixado para trás. Esse foco na complexidade da aviação é o que diferencia a Document AI especializada – ela fala a linguagem dos documentos de aviação, enquanto os modelos genéricos permanecem sem linguagem.
Documento de Aviação IA em Números
Para ilustrar o desempenho e os recursos da nossa Document AI de nível de aviação, aqui estão algumas métricas e recursos principais:
- Precisão em nível de campo > 98%– Campos de dados essenciais (IDs de peças, datas, caixas de seleção de conformidade, etc.) são capturados corretamente com mais de 98% de precisãofile-q7xvjvhip1lffe4hbnkuac, mesmo em diferentes layouts de documentos. Isso reduz drasticamente a necessidade de correção humana.
- Precisão de OCR em nível de caractere > 99%– Graças ao OCR robusto (e ao uso de camadas de texto nativas, quando disponíveis), o reconhecimento de caracteres é praticamente isento de erros. Por exemplo, números de série ou códigos de peças com dezenas de caracteres são reproduzidos com exatidão, preservando identificadores críticos.
- Suporte IPC da Boeing (montagens capturadas)– Atualmente suportaDocumentos do IPC da Boeing, analisando cada item de linha. O extrator entende o esquema IPC: ele extrai campos como número da figura, número do item, número da peça, nomenclatura, unidades por conjunto e intervalos de efetividade. Crucialmente, elecaptura relacionamentos de montagem pai/filho, reconstruindo a hierarquia das peças em cada montagem. Isso significa que sua IA pode responder a perguntas sobre como os componentes estão aninhados ou identificar todas as subpeças em uma determinada montagem – recursos inatingíveis com analisadores genéricos.
- Escala – 1.000 páginas simultaneamente– O sistema foi testado em campo em umtaxa de transferência de ingestão de 1k páginas em paralelo, executando 5 lotes simultâneos de 200 páginas cada arquivo-q7xvjvhip1lffe4hbnkuac. Na prática, isso significa que uma biblioteca inteira de manuais ou um ano de diários de bordo podem ser processados em minutos. A alta taxa de transferência garante que mesmopendências de alto volumeou fluxos de documentos em tempo real (como um despejo repentino de novos registros de manutenção) podem ser manipulados sem engasgos.
- Divisão e classificação de documentos em tempo real– Manuais PDF grandes ou conjuntos de documentos combinados são automaticamentedividido em documentos ou seções individuaispara processamento direcionadofile-q7xvjvhip1lffe4hbnkuac. Um baseado em IAclassificador de documentosprimeiro determina o tipo de documento (por exemplo, distinguindo um Catálogo de Peças Ilustrado de um Manual de Manutenção ou um Certificado de Aeronavegabilidade) para encaminhá-lo ao pipeline de extração correto file-q7xvjvhip1lffe4hbnkuac. Essa classificação tem uma taxa de recuperação próxima a 100%, garantindo que nenhum documento seja identificado incorretamente ou ignorado. A divisão e a classificação ocorrem em tempo real, permitindo que alimentações contínuas de tipos de documentos mistos sejam processadas com precisão em tempo real.
- Saída estruturada para fácil integração– Os dados extraídos não são apenas texto bruto – são gerados como registros estruturados (JSON, XML, etc.) completos com metadados como tipo de documento, cabeçalhos de seção e até referências de página.captura de estrutura de documentosignifica que você retém o contexto: cada ponto de dados sabe de onde veio (página X do manual Y, seção Z). Essa estrutura é inestimável ao alimentar os dados em outros sistemas ou auditorias.
Em suma, a combinação de altíssima precisão e recursos personalizados para cada domínio (como captura de hierarquia de montagem) torna esta solução excepcionalmente capaz de processar documentos de aviação em escala. A seguir, vamos ver como esses recursos se integram a um pipeline de IA.
Visão geral do pipeline técnico: de documentos a dados prontos para IA
Para construir uma estratégia eficazPipeline de IA para dados de aviação, recomendamos uma abordagem em etapas. Aqui está uma visão geral do pipeline, desde a ingestão de documentos brutos até a entrega de vetores para modelos de IA:
- Ingestão (PDFs e digitalizações):Aceite documentos de várias fontes – sejam digitalizações de alta resolução, PDFs com texto incorporado ou imagens. O pipeline pode ingerirregistros em papel digitalizadose aplique OCR avançado se necessário, ou analise diretamente o texto de PDFs digitais (aproveitando a camada de texto para precisão de 99,9% quando disponível). O estágio de ingestão normaliza os formatos de arquivo e enfileira os documentos para processamento. Ele foi projetado para lidar com uploads em massa e entradas de streaming, iniciando trabalhos posteriores assim que novos arquivos chegam (com suporte ao processamento orientado a eventos para sistemas em tempo real).
- Classificação:Em seguida, um classificador com tecnologia de IA identifica o tipo e a finalidade de cada documento (file-q7xvjvhip1lffe4hbnkuac). Por exemplo, ele rotula documentos como "Certificado de Aeronavegabilidade", "IPC – Boeing 737", "Cartão de Tarefa de Manutenção", "Boletim de AD da FAA" etc. Esta etapa é crucial porque a lógica de extração geralmente é específica do modelo. A alta precisão da classificação (com recuperação próxima de 100%) garante que cada documento seja encaminhado para o modelo de extração ou conjunto de regras correto. Se um documento contiver várias seções (por exemplo, um PDF mesclado com vários formulários), esta etapa também segmenta essas seções por tipo.
- Divisão automatizada:Manuais grandes ou PDFs que contêm vários documentos são automaticamentedividido em unidades lógicasfile-q7xvjvhip1lffe4hbnkuac. Por exemplo, um manual de manutenção de 500 páginas pode ser dividido por capítulo ou tarefa, ou um PDF do IPC abrangendo várias seções será dividido por seção/figura. Da mesma forma, uma pilha de páginas digitalizadas do diário de bordo será separada em imagens de páginas individuais para processamento paralelo. A divisão da entrada serve a dois propósitos: permiteextração paralela(acelerando enormemente o processamento) e garante que os limites de contexto sejam respeitados (para que cada bloco possa ser tratado de forma independente para tarefas posteriores, como incorporação). Isso é feito em tempo real; assim que um arquivo grande é ingerido, o sistema começa a dividi-lo e a alimentar páginas/seções na etapa de extração simultaneamente.
- Extração de alta precisão:Este é o estágio central onde o mecanismo de extração de Document AI entra em ação. Usando uma combinação de modelos OCR específicos de modelo, analisadores NLP e verificações de validação, o sistemaextrai dados estruturados com precisão de nível de aviação. Os campos principais são extraídos de acordo com o tipo de documento – para um IPC: números de peças, nomenclatura, referências de montagem, etc.; para um registro de manutenção: datas, ações tomadas, notas mecânicas; para um formulário regulatório: IDs de certificados, expirações, assinaturas, etc.Integridade contextualé mantido: a saída preserva a seção ou tabela de origem de um campo, e os campos são vinculados (por exemplo, todos os itens de linha em uma Figura ou todas as entradas em uma determinada data). O resultado é um conjunto de dados estruturado que representa as informações do documento. Com precisão >98% no nível do campo, a necessidade de revisão humana é mínima, e quaisquer quedas de confiança ou anomalias podem ser sinalizadas para inspeção.
- Incorporação e vetorização:Uma vez extraídos, os dados textuais podem ser transformados em embeddings vetoriais para consumo de IA. O pipeline integra-se comprincipais modelos de incorporação– você pode conectar o modelo de sua escolha (por exemplo, APIs de incorporação de texto da OpenAI, Sentence-BERT ou outros codificadores baseados em transformadores) para converter cada pedaço de documento ou registro de dados em um vetor de alta dimensão. Oferecemos suporte personalizadoestratégias de fragmentaçãoAqui: por exemplo, você pode incorporar cada parágrafo ou cada seção separadamente para otimizar a recuperação posterior. O sistema pode dividir automaticamente campos de texto grandes (como parágrafos manuais longos) em tamanhos de snippet ideais para sua janela de contexto do LLM, ou você pode definir regras de divisão (por frase, por subseção, etc.). Essa flexibilidade garante que as incorporações capturem informações significativas sem truncar o contexto. Ao final dessa etapa, cada documento (ou seção do documento) é representado por um ou mais vetores de incorporação, normalmente acompanhados de metadados (ID do documento, título da seção, referência da fonte).
- Injeção de banco de dados vetorial:Por fim, os vetores e metadados sãoinjetado em um banco de dados vetorialde sua escolha. A solução funciona imediatamente com lojas de vetores populares comoRedis(com vetores RediSearch),Pinha, ou Elástico(Recurso de busca vetorial do Elastic), entre outros. Isso significa que o conhecimento extraído de documentos torna-se imediatamente pesquisável por meio de busca por similaridade ou utilizável na geração de recuperação aumentada. Por exemplo, agora você pode consultar sua coleção de documentos em linguagem natural e recuperar os trechos mais relevantes no espaço vetorial, ou seu assistente de IA pode buscar seções relevantes do manual de manutenção para responder a uma pergunta. O pipeline garante que, juntamente com cada vetor, o texto original e a referência do documento sejam armazenados, para que, quando uma correspondência de vetor for encontrada, você possa rastreá-la até o documento/página de origem. Atualizações em tempo real também são suportadas – se novos documentos chegarem, seus embeddings podem ser inseridos dinamicamente, mantendo o banco de dados de vetores e a base de conhecimento da sua IA atualizados.
Este pipeline garante um fluxo suave de entradas brutas não estruturadas para informações estruturadas e prontas para IA. Cada etapa é otimizada para casos de uso na aviação – desde a compreensão de formatos de documentos específicos de um domínio até a expansão do processamento em milhares de páginas simultaneamente. O resultado final é umbanco de dados vetorial rico em conhecimentoque potencializa pesquisas, análises ou grandes modelos de linguagem comdados precisos e ricos em contexto.
Garantindo desempenho escalável e confiabilidade
A arquitetura para processamento de documentos em escala de aviação significa lidar com ambosalto rendimento e alta confiabilidade. No lado da taxa de transferência, conforme observado, nossa IA de documentos pode ingerir e processar documentos em paralelo – com sucessoprocessando 1.000 páginas simultaneamenteEm testes de campo recentes, file-q7xvjvhip1lffe4hbnkuac. Isso foi alcançado com uma abordagem de escalonamento horizontal: vários extratores operando em diferentes lotes de páginas simultaneamente. O sistema é nativo da nuvem e pode ser escalonado automaticamente com a carga, o que significa que, independentemente de você ter 100 ou 100.000 páginas para analisar, ele pode alocar recursos para atender à demanda. Para uma equipe de IA, essa escalabilidade se traduz em um tempo de espera mínimo entre a ingestão de dados e o insight – crucial quando você precisa, por exemplo, integrar rapidamente a biblioteca de documentação de uma nova aeronave à sua plataforma de análise.
A confiabilidade vem de mais do que apenas precisão bruta; também se trata decapturando estrutura e contexto corretamente. Por exemplo, captura de estrutura de documentogarante que, quando os dados forem usados posteriormente, você conheça o contexto. Se uma busca vetorial retornar um trecho sobre "valor de torque: 50 Nm", o sistema saberá de qual manual de manutenção e seção ele veio, e poderá recuperar a seção inteira ou a imagem da página sob demanda. Isso é inestimável para a validação e para que os usuários finais confiem na saída da IA – eles sempre podem consultar o trecho do documento original que a IA utilizou. As saídas estruturadas do nosso pipeline incluem esses marcadores contextuais por padrão.
Além disso, a solução foi testada em variações de documentos do mundo real. Documentos de aviação podem ser confusos – digitalizações com carimbos, caligrafia ou layouts ligeiramente diferentes entre os fabricantes. O Document AI utilizaconjunto OCRabordagens (combinando múltiplos mecanismos de OCR e um mecanismo de votação) ao lidar com digitalizações ruidosas, e emprega regras de validação (como verificações de soma de verificação em números de peças, verificações de formato de data, etc.) para detectar quaisquer anomalias de extração. Isso significa que, mesmo ultrapassando os limites de produtividade, o sistema mantém um alto padrão de precisão. Em benchmarks internos com IPCs da Boeing, a precisão dos caracteres do OCR foi medida em99,9%em documentos com uma camada de texto existente e apenas um pouco menor em imagens digitalizadas puras, graças aos modelos avançados de OCR. Ao capturar a estrutura específica do domínio (como o sumário de manuais ou seções em diários de bordo), o sistema também pode dividir e se recuperar de erros com facilidade – por exemplo, se uma página tiver qualidade particularmente ruim, ela é isolada e sinalizada em vez de descarrilar um lote inteiro.
Para as equipes de engenharia de IA, esses recursos eliminam uma grande dor de cabeça: você pode confiar nos dados que saem do seu pipeline de documentos. Você não precisa mais corrigir erros de OCR ou escrever expressões regulares ad hoc para cada novo tipo de documento. O foco pode, em vez disso, mudar para a construção de aplicativos de IA poderosos (como modelos de manutenção preditiva, construção de gráficos de conhecimento ou ferramentas de auditoria de conformidade) sobre essa camada de dados confiável.
O Impacto na IA Downstream: RAG, LLMs e Pesquisa
Vale a pena enfatizar novamente como essa extração de alta precisão alimenta as tarefas de IA subsequentes. ConsidereGeração Aumentada de Recuperação (RAG): aqui, um modelo de linguagem de grande porte (LLM) é complementado com documentos relevantes ou trechos obtidos de uma base de conhecimento. Se a sua base de conhecimento for um banco de dados de vetores de documentos de aviação construído a partir de uma extração desleixada, o LLM pode receber texto irrelevante ou incorreto – levando-o a gerar uma resposta imprecisa ou alucinada. Em contraste, alimentar o LLM comtrechos limpos e precisosdo nosso pipeline de Document AI significa que o modelo pode gerar respostas baseadas na verdade. Observamos que, ao aumentar a precisão em nível de campo para mais de 98%, melhoramos significativamente a precisão dos acertos de recuperação (menos correspondências falsas) e, consequentemente, a qualidade das respostas em um ambiente de perguntas e respostas sobre aviação. Em essência, o LLM pode se concentrar em sua tarefa de compreender e compor respostas, em vez de se esforçar internamente com entradas confusas. O resultado é uma assistência de IA muito mais confiável para engenheiros e tomadores de decisão.
A mesma lógica se aplica a sistemas de busca semântica simples ou de perguntas e respostas que não envolvem geração. Por exemplo, uma companhia aérea pode construir umaportal de pesquisapara técnicos de manutenção consultarem registros ou manuais de reparos anteriores. Se o índice por trás dessa busca for construído com base em dados extraídos com precisão, os resultados da busca serão confiáveis – os registros retornados contêm genuinamente os termos da busca ou informações relevantes. Caso contrário, a busca pode perder documentos críticos (baixa recordação) ou revelar documentos incorretos (falsos positivos), minando a confiança do usuário. A extração de alta precisão garante que, ao buscar por "conformidade com AD de bomba de combustível", você obtenha o documento da Diretiva de Aeronavegabilidade relevante e os registros de conformidade relacionados, sem um monte de ruído.
Não importa o quão avançados sejam seus modelos de IA – mesmo que você empregue um transformador de última geração com 175 bilhões de parâmetros –suas saídas podem ser desviadas por dados de entrada incorretosNo contexto da aviação, onde a segurança e a conformidade regulatória estão em jogo, isso não é apenas um pequeno inconveniente; é um risco sério. É por isso que insistimos em uma camada de extração de nível superior. Ela atua comoúnica fonte de verdade, convertendo seus documentos não estruturados em um repositório de conhecimento limpo, consultável e pronto para IA.
Conclusão: Estabelecendo as bases para o sucesso da IA de nível de aviação
Para líderes de IA e equipes técnicas no setor de aviação, a mensagem é clara:investir na precisão dos dados no início do seu pipeline de IADocumentos complexos e de alto volume sobre aviação são uma fonte formidável de verdade – e extrair seus dados com fidelidade quase perfeita é a única maneira de revelar essa verdade para seus sistemas de IA. Economizar na qualidade da extração é uma falsa economia; qualquer economia será anulada pelo baixo desempenho da IA posteriormente ou, pior, por um insight crítico perdido devido a um ponto de dados incorreto. Ao implementar uma IA de documentos especializada em aviação com precisão de ~98-99%+, você estabelece uma base sólida para todas as aplicações posteriores, desde manutenção preditiva e otimização de frota até auditoria de conformidade e assistentes inteligentes.
Resumindo, A IA de documentos de alta precisão é o eixo da IA de nível de aviação. Transforma montanhas de papelada desestruturada em dados confiáveis e estruturados. Com isso, seuLLMs, gráficos de conhecimento e painéis analíticospode voar – fornecendo insights precisos e acionáveis que impulsionam a segurança e a eficiência nas operações. Sem ela, até mesmo a IA mais poderosa tropeçará na entrada instável. À medida que a indústria da aviação adota a transformação digital e a IA, aqueles que se baseiam em uma base de extração de dados limpa e precisa terão uma vantagem decisiva. É como ter uma bússola ultraconfiável antes de um voo – você não decolaria sem uma e, da mesma forma, nenhuma jornada de IA deve começar sem dados confiáveis. Ao incorporar uma solução de IA de documentos de alta precisão em seu pipeline – completa com modelos ajustados por domínio, OCR robusto e integração perfeita com bancos de dados vetoriais – você garante que suas iniciativas de IA de aviação sejam liberadas para decolar com confiança e precisão.
Tendências de manutenção da aviação que podem ganhar força em circunstâncias incertas
As aeronaves estão em serviço por mais tempo, as cadeias de suprimentos são um barril de pólvora e a tecnologia está evoluindo da noite para o dia. Descubra as tendências de manutenção que estão ganhando força e o que elas significam para as operadoras que buscam se manter no ar e lucrativas.

April 10, 2026
Mission Control: Infraestrutura de Inteligência de Alto Desempenho para Velocidade Crítica na Tomada de Decisões
Todo líder com quem converso nos setores aeroespacial, de manufatura ou de construção diz a mesma coisa:
Nossos sistemas estão ficando mais inteligentes, mas nossas decisões não estão se tornando mais rápidas nem mais seguras no ritmo que as operações exigem.
Em ambientes de alta integridade, a lacuna entre dados e decisões é onde o risco se acumula. À medida que as operações se tornam mais complexas, distribuídas e sensíveis ao tempo, as organizações precisam de sistemas de inteligência que não sejam apenas rápidos, mas também verificáveis, determinísticos e seguros por concepção.
Esta é a filosofia de engenharia por trás do Mission Control, nossa infraestrutura de inteligência de alto desempenho, criada para oferecer velocidade de decisão em tempo real, auditável e com segurança criptográfica.

October 2, 2025
Escolhendo as peças certas da aeronave com análise de tolerância a danos
O futuro da segurança da aviação está nas peças. Peças autênticas e rastreáveis proporcionam às frotas tolerância a danos e desempenho ideais para máxima segurança e eficiência na aquisição.

September 30, 2025
Como entrar em novos mercados de aviação: o guia completo para fornecedores de peças
Entrando em novos mercados de aviação? Aprenda como os fornecedores podem analisar a demanda, gerenciar peças PMA e construir a confiança das companhias aéreas. Um guia completo para o crescimento global.

