Превращайте аналитические выводы ИИ в реальные действия
Vector DB. Раскройте неструктурированный интеллект авиации.
июня 15, 2025
Векторные базы данных индексируют многомерные векторы встраивания для обеспечения семантического поиска по неструктурированным данным, в отличие от традиционных реляционных или документных хранилищ, которые используют точные совпадения по ключевым словам. Вместо таблиц или документов векторные хранилища управляют плотными числовыми векторами (часто 768–3072 измерений), представляющими семантику текста или изображения. Во время запроса база данных находит ближайших соседей к вектору запроса, используя алгоритмы поиска приближенных ближайших соседей (ANN). Например, основанный на графах индекс, такой как Hierarchical Navigable Small Worlds (HNSW), создает многоуровневые графы близости: небольшой верхний слой для грубого поиска и более крупные нижние слои для уточнения (см. рисунок ниже). Поиск «прыгает» вниз по этим слоям — быстро локализуясь в кластере перед исчерпывающим поиском локальных соседей. Это позволяет компенсировать отзыв (поиск истинных ближайших соседей) задержкой: повышение параметра поиска HNSW (efSearch) увеличивает отзыв за счет более высокого времени запроса.
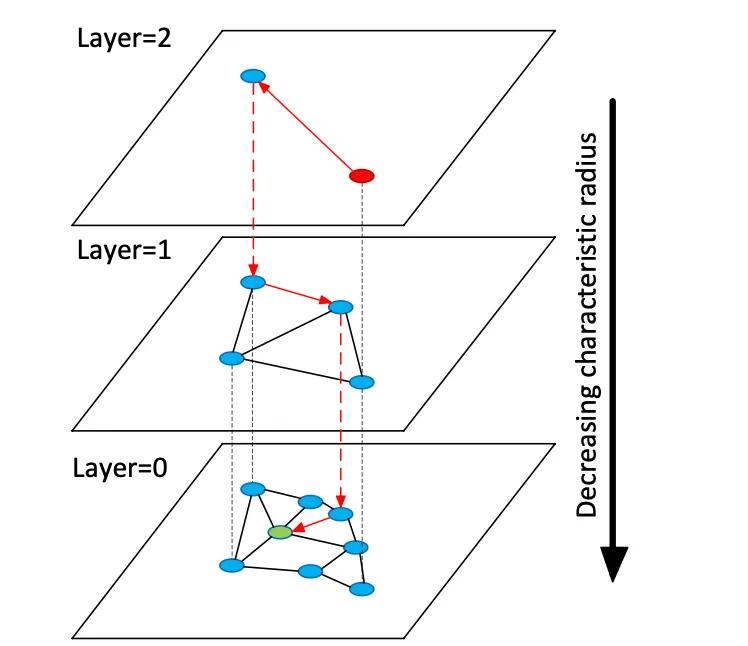
Рисунок: Граф поиска HNSW ANN — векторы организованы в слои для ускорения запросов к ближайшим соседям (адаптировано из объяснения Redis Vector Sets от Devmy).
В отличие от точного поиска в реляционных таблицах, векторный поиск может улавливать смысл: запросы находят семантически схожие элементы, а не только точные совпадения ключевых слов. Для авиационных данных (например, руководств или журналов ремонта) это означает, что инженеры могут извлекать релевантный контент, даже если формулировка отличается. Векторные расстояния (косинус, скалярное произведение или евклидово) количественно определяют сходство. Когда вложения нормализуются, косинусное сходство и скалярное произведение дают эквивалентные рейтинги. На практике обычно нормализуют векторы и используют косинусное сходство в качестве метрики релевантности. Ключевые компромиссы включают полноту против задержки: большие индексы и более высокие параметры поиска улучшают полноту, но увеличивают задержку. Векторные базы данных предоставляют настраиваемые индексы (HNSW, IVF, плоское сканирование) для баланса скорости против точности.
Встраиваемые модели
Современные модели встраивания преобразуют текст (или другие данные) в векторы. Ведущие модели включают text-embedding-3-large от OpenAI, embed-multilingual-v3 от Cohere, модели Gemini/BGE от Google, семейства E5 и GTE от Meta и многие модели HuggingFace (например, варианты Sentence-BERT). Эти модели различаются по размерности, охвату данных и стоимости вывода. Например, text-embedding-3-large от OpenAI создает 3072-мерные векторы, что значительно больше, чем более ранняя Ada-002 (1536D). Модели Cohere v3 обычно выводят 1024D (английский или многоязычный) или меньше (например, 384D «облегченные» версии). E5-large и GTE-large от Meta также производят 1024D вложения, тогда как их базовые или «малые» варианты дают 768D или 384D. Вложения Vertex-AI от Google включают 768D текстовые модели и 3072D «gemini-embedding-001» большую модель. В целом, более высокие измерения часто улучшают семантическую точность, но требуют больше памяти и вычислений: e5-base (768D) индексировал набор данных более чем в 2 раза быстрее, чем ada-002 (1536D) в одном бенчмарке.
Модели встраивания также различаются по данным обучения и многоязычности. API встраивания OpenAI и Cohere являются проприетарными (с соответствующими затратами и ограничениями на использование), в то время как E5/GTE от Meta и многие модели HuggingFace имеют открытый исходный код (лицензируются Apache). Модели E5 и GTE поддерживают более 50 языков, как и многоязычные модели Cohere-v3. Такое многоязычное покрытие ценно для международной авиационной документации. Адаптация домена имеет решающее значение для специализированных словарей (например, язык глав ATA, номенклатура деталей). По умолчанию эти модели обучаются на веб-тексте и общих корпусах; они могут не идеально улавливать авиационный жаргон. Командам следует рассмотреть возможность тонкой настройки или использования адаптеров в журналах обслуживания или руководствах. На практике корпоративные системы часто начинаются с сильных общих встраиваний (например, OpenAI или E5), а затем настраиваются на специфичный для домена текст.
С точки зрения производительности модели различаются по задержке. Меньшие модели (например, E5-base-768) быстрее в выводе, тогда как большие проприетарные модели (OpenAI 3072D) медленнее и могут разрешать только один запрос за раз. Если локальное оборудование ограничено, можно использовать меньшие или квантованные модели. Лицензирование имеет значение: OpenAI и Cohere взимают плату за запрос и имеют политики использования, в то время как открытые модели, такие как E5/GTE или BGE от Google (открывается через VertexAI с квотами), избегают затрат на API. Подводя итог, любая векторная база данных может принимать вложения из любой из этих моделей, но архитекторы должны взвешивать размерность встраивания, стоимость, многоязычную поддержку и соответствие домену при выборе моделей для авиационных данных.
Типы векторных баз данных
Существует целый ряд систем векторных баз данных — от облегченных библиотек до полноценных платформ:
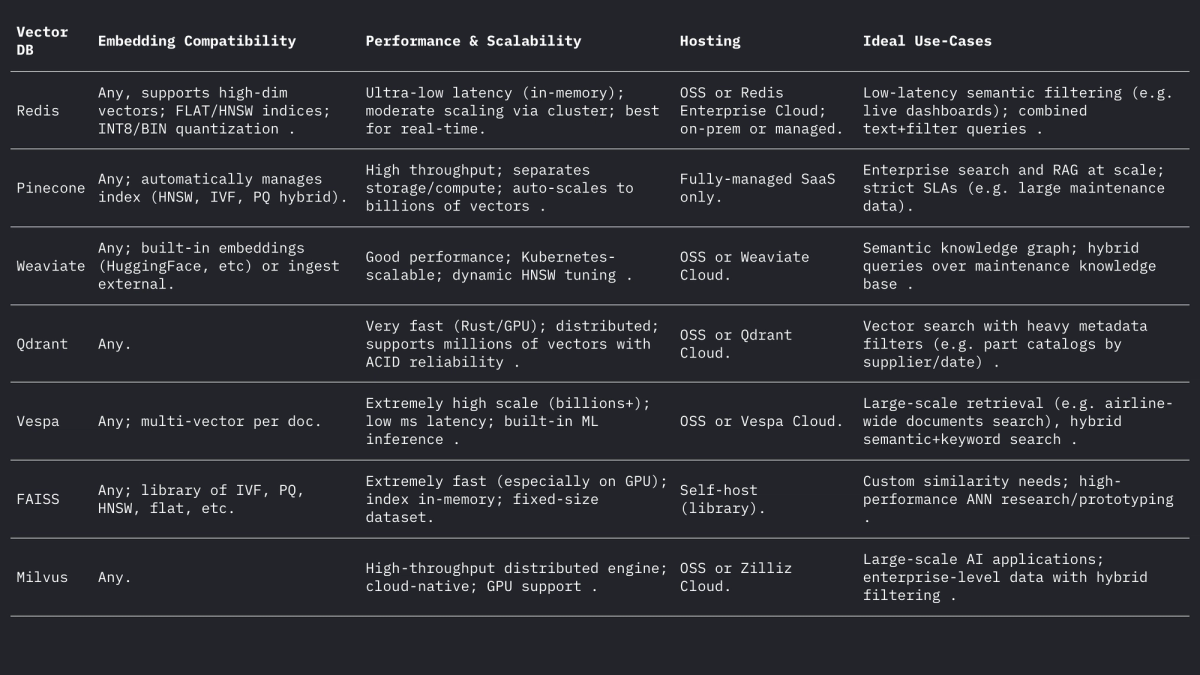
- Redis (векторные наборы) — Redis — это хранилище ключей и значений в памяти с модулем векторного индекса. Он поддерживает индексы FLAT (точный перебор) и HNSW. Векторные наборы Redis однозначно допускают динамические обновления: графики HNSW поддерживаются двунаправленно, поэтому векторы можно добавлять или удалять «на лету» с немедленным эффектом. Redis поддерживает квантование (8-битное или двоичное) для уменьшения памяти (до 4×–32×) с минимальной потерей точности. Он также обеспечивает гибридную фильтрацию: векторы могут храниться вместе с текстовыми тегами или числовыми полями и фильтроваться (например, .year > 2020) в одном запросе. Как движок в памяти, Redis обеспечивает сверхнизкую задержку за счет использования оперативной памяти. Он масштабируется горизонтально с помощью кластеризации, хотя размеры кластеров, как правило, меньше, чем у выделенных векторных платформ. Redis доступен как с открытым исходным кодом или через Redis Enterprise Cloud.
- Pinecone – полностью управляемый облачный сервис векторного поиска. Pinecone абстрагирует всю инфраструктуру: он отделяет хранилище от вычислений и масштабируется до миллиардов векторов, поддерживая быстрое время запросов. Он автоматически управляет индексами под капотом (смешивая HNSW, IVF, PQ и т. д.) для оптимальной производительности. Компромисс заключается в стоимости и непрозрачности: Pinecone прост в использовании (без операций), но дороже, чем OSS. Он превосходит по производительности и рабочим нагрузкам с высокой пропускной способностью и ограничениями SLA, поддерживая гибридные (ключевое слово + вектор) запросы и корпоративные функции. Pinecone идеально подходит для команд, которым нужна масштабируемость и надежность корпоративного уровня без управления серверами.
- Weaviate — векторная база данных с открытым исходным кодом, ориентированная на графы (также предлагается как управляемая услуга). Weaviate позволяет использовать богатую схему и структурирование графа знаний вместе с векторами. Он предлагает API GraphQL для объединения семантического поиска векторов с традиционными запросами (гибридный поиск). Weaviate в основном использует индексы HNSW (и может использовать плоский индекс для небольших наборов данных). Он автоматически настраивает параметры поиска или допускает асинхронное индексирование для пропускной способности. С модулями для глубокого обучения Weaviate может даже генерировать векторы (например, с помощью моделей HuggingFace). Он масштабируется через Kubernetes и облачные или локальные кластеры. Сильные стороны Weaviate — гибридный семантический + символьный поиск и гибкость в моделировании данных; он подходит, когда отношения (например, иерархии деталей и самолетов) имеют такое же значение, как и сходство векторов.
- Qdrant — векторная поисковая система с открытым исходным кодом на Rust. Qdrant предлагает высокопроизводительный индекс ANN с богатой фильтрацией метаданных. Он поддерживает индексы HNSW с динамическим автомасштабированием и предоставляет HTTP API. Примечательно, что Qdrant делает акцент на строгой фильтрации и надежности — он поддерживает распределенное развертывание, транзакции ACID и ускорение GPU. Он очень хорошо работает с большими наборами данных и возвращает высокий уровень полноты. Qdrant Cloud упрощает развертывание, но он столь же надежен при самостоятельном размещении. Это делает Qdrant сильным выбором, когда вам нужны комбинированные векторные сходства и структурированные фильтры (например, поиск только в определенных моделях самолетов или диапазонах дат).
- Vespa – поисковая и аналитическая система с открытым исходным кодом, изначально разработанная Yahoo. Vespa уникальным образом объединяет векторный поиск с классическим поиском с инвертированным индексом. Она может обрабатывать миллиарды векторов с чрезвычайной пропускной способностью: платформа заявляет о поддержке тысяч QPS при задержках <100 мс по огромным данным. Vespa поддерживает многовекторный поиск на документ и гибридный поиск (семантический + ключевое слово). Ее индексация ANN включает HNSW (и новые варианты, такие как HNSW-IF, которые объединяют фильтрацию инвертированных файлов). Как полноценный сервер приложений, Vespa также поддерживает пользовательские модели ранжирования и конвейеры вывода ML. Поэтому она хорошо подходит для крупномасштабных, критически важных поисковых приложений (например, поисковых порталов по всей авиакомпании), где требуются масштаб и гибридная релевантность. Vespa может управляться самостоятельно или использоваться через Vespa Cloud.
- FAISS – исследовательская библиотека Meta для поиска по сходству. FAISS – это не отдельная база данных, а набор высокооптимизированных индексов (Flat, IVF, PQ, HNSW и т. д.), которые работают на CPU/GPU. Она обеспечивает исключительную скорость (особенно с GPU) и гибкость: можно использовать практически любую метрику расстояния или метод индексирования. Однако FAISS не включает в себя механизм хранения/запросов или фильтрацию метаданных – вы должны интегрировать его в свою собственную систему. Она наиболее подходит, когда требуется максимальная производительность и контроль над алгоритмами индексирования. Например, FAISS широко используется в компьютерном зрении и исследованиях МО, где полнота и скорость имеют первостепенное значение, а размеры данных фиксированы. В авиации FAISS может лежать в основе пользовательского инструмента поиска для очень высокоразмерных вложений (например, распознавание деталей на основе изображений), но для этого требуется окружающая архитектура.
- Milvus — популярная векторная база данных с открытым исходным кодом, разработанная для крупномасштабных рабочих нагрузок. Milvus предлагает как автономные, так и распределенные режимы, поддерживая миллиарды векторов с высокой степенью согласованности. Он предоставляет несколько типов индексов (HNSW, IVF, Annoy и т. д.) и метрик (косинус, L2 и т. д.), а также гибридный поиск с помощью скалярной фильтрации. Milvus — это GPU-ускоритель и облачный сервис (интегрируется с Kubernetes). Он включает в себя корпоративные функции, такие как моментальные снимки и шифрование, и активно разрабатывается Zilliz. Архитектура Milvus создана для масштабирования и производительности, что делает ее идеальной для приложений с интенсивным использованием данных, таких как анализ огромных архивов руководств или журналов датчиков. Zilliz также предлагает Milvus Cloud для управляемого хостинга.
Каждая из этих систем обрабатывает векторы и фильтры по-разному, но все они поддерживают L2, внутреннее произведение (точка) и косинусные расстояния (часто путем хранения нормализованных векторов). На форуме Weaviate отмечается, что он может даже хранить векторы до 65535 измерений, что намного превышает типичные размеры встраивания, демонстрируя гибкость современных движков. Резюме:
Варианты использования в авиации
Семантический поиск: Техническое обслуживание самолетов включает в себя обширные коллекции руководств, сервисных бюллетеней и нормативных документов. Система векторного поиска позволяет инженерам задавать запросы на естественном языке (или даже голосовые запросы) и извлекать соответствующие отрывки или документы семантически. Например, вместо поиска по ключевым словам «утечка моторного масла» встроенный поиск может найти параграфы бюллетеня, описывающие «утечку гидравлической жидкости», если они контекстно схожи. Как показал Infosys/AWS, хранение каждого технического документа в виде векторов позволяет агентам на базе LLM отвечать на запросы по техническому обслуживанию, извлекая наиболее релевантные документы из репозитория.
Нечеткое сопоставление деталей: авиационные детали часто имеют криптические идентификаторы (NSN или номера деталей) и описательные названия, которые различаются у разных поставщиков. Векторные вложения описаний деталей или даже номеров деталей (обрабатываемых как текст) могут выявить почти дубликаты, которые не находят при сопоставлении на основе правил. В других областях вложения слов использовались для семантического нечеткого сопоставления имен; аналогично, вложения дескрипторов деталей могут сопоставлять деталь с ее ближайшим описанием в каталогах поставщиков, даже если написание или коды различаются. Это может объединить инвентарь из нескольких источников.
Классификация и кластеризация журналов: Журналы ремонта и неисправностей обычно представляют собой текст в свободной форме. Модели внедрения могут преобразовывать записи журнала в векторы, а кластеризация этих векторов может автоматически группировать схожие шаблоны неисправностей. Например, фреймворк «HELP» кластеризует потоковые системные журналы по их внедрению для обнаружения повторяющихся шаблонов журналов. В авиации аналогичная кластеризация может определять общие режимы отказов или классифицировать записи о незапланированном техническом обслуживании без предопределенных меток, что позволяет проводить аналитику по частым проблемам (например, кластеризация инцидентов «странной вибрации»). Эта неконтролируемая семантическая группировка помогает в анализе тенденций и прогнозировании рабочей нагрузки.
Conversational Retrieval (RAG): Встраивания лежат в основе систем Retrieval-Augmented Generation (RAG), которые обеспечивают работу чат-ботов с документами. Пример чат-бота в формате PDF демонстрирует архитектуру: извлечение текста из руководств, разбиение его на части, встраивание каждой части и сохранение в векторном хранилище (например, FAISS). Во время выполнения каждый пользовательский запрос встраивается и используется для извлечения k наиболее релевантных частей через векторный индекс. Эти части формируют контекст для LLM для ответа на вопрос. Для авиации конвейер RAG позволяет техническому специалисту «общаться» с цифровым двойником самолета: например, спрашивая «Какова процедура замены переключателя обогрева Пито?» и получая точный ответ из руководств OEM.
Индексация прогнозируемых отказов: исторические записи по техническому обслуживанию описывают отказы и исправления. Можно индексировать описания отказов как векторы, чтобы описание нового инцидента сопоставлялось с аналогичными прошлыми случаями. Исследования в области прогнозируемого обслуживания показали, что вычисление семантического сходства текста отказа с использованием вложений трансформатора (с косинусным или пирсоновским сходством) успешно группирует связанные отказы. На практике, когда механик регистрирует новое описание неисправности, система может извлекать прошлые инциденты с высоким сходством вложений, чтобы предлагать вероятные первопричины или проверки, эффективно «прогнозируя» на основе близости в пространстве вложений.
Практические соображения по проектированию
Размерность встраивания: встраивания с более высокой размерностью охватывают больше нюансов, но требуют больше затрат на хранение и вычисления. Обычный выбор — 768, 1024, 1536 или 3072 измерений. Например, более крупные модели OpenAI используют 1536–3072 измерений, тогда как базовый E5/GTE Meta использует 768 или 1024. В пилотном эксперименте индексация того же корпуса заняла в 2,4 раза больше времени с встраиваниями 1536D, чем 768D. Таким образом, если пропускная способность и задержка имеют решающее значение (например, фильтрация сотен запросов/сек на устройстве), может быть достаточно 768D или 1024D. Если целью является максимальный отзыв (и оборудование позволяет), приемлемы более крупные измерения. Для авиации можно начать с 1024D (сбалансированное) и протестировать меньшие и большие модели на задачах поиска в доменных данных.
Метрика расстояния: выбор косинуса (или нормализованного скалярного произведения) по сравнению с необработанным евклидовым зависит от встраивания. Большинство современных текстовых встраиваний сравниваются с помощью косинусного сходства. Например, Текгёз и др. обнаружили, что метрики косинуса/Пирсона дают наилучшее сходство для описаний отказов. Redis и другие поддерживают явное указание «КОСИНУСА» (за кулисами нормализации векторов), тогда как многие системы используют внутреннее произведение на предварительно нормализованных векторах. На практике косинус и внутреннее произведение эквивалентны, если встраивания нормализованы. Евклидово расстояние менее распространено для текста, но концептуально похоже, когда векторы находятся на сфере. Рекомендация: используйте косинус для текстовых встраиваний.
Метаданные и гибридное структурирование: важно хранить векторные вложения вместе со структурированными метаданными (модель самолета, глава ATA, дата, номер детали и т. д.) для уточненного поиска. Все современные векторные хранилища позволяют прикреплять метаданные к каждому вектору. Например, Redis Vector Sets позволяют фильтровать по атрибутам JSON в одном запросе (например, WHERE aircraft_model = 'A320' AND ATA = '21'). Qdrant обеспечивает мощную булеву фильтрацию для сужения результатов векторов по метаданным. При проектировании схемы определите поля метаданных (например, model, ata, date, part_no) и индексируйте их обычным образом, помечая текстовое поле как VECTOR. В гибридных запросах система сначала применяет фильтр метаданных (или объединяет его с помощью штрафа за счет), а затем ищет только подмножество для ближайших соседей, повышая точность. Убедитесь, что критические фильтры (например, номер борта самолета или временной диапазон) находятся в индексированных скалярных полях для использования фильтрации БД.
Настройка задержки и пропускной способности: параметры индекса ANN должны быть настроены на целевую задержку. Для HNSW повышение параметра efSearch дает более высокий отзыв, но линейно увеличивает время запроса. Практический подход заключается в бенчмаркинге отзыва против задержки на удержанном наборе: начните с низкого ef для скорости, затем увеличивайте до плато отзыва. Weaviate даже поддерживает «динамический ef», который масштабирует ef с желаемым количеством результатов. Для пакетных рабочих нагрузок можно использовать индексы FLAT (точные) для максимальной точности, тогда как для запросов в реальном времени длительностью в десятки миллисекунд лучше использовать HNSW или IVF с настроенными параметрами. Квантование (8-битное, квантование продукта) — еще один рычаг: например, настройки Redis Q8 против BIN значительно сокращают память и ускоряют поиск за счет небольшого снижения точности.
Обновления индекса: если ваши данные часто меняются (новые записи журнала или ручные обновления), выбирайте системы, которые поддерживают динамическую индексацию. Реализация HNSW в Redis позволяет выполнять вставки и удаления «на лету» без перестройки индекса. Weaviate может обновлять HNSW асинхронно (чтобы записи не блокировали чтения). Другие, такие как FAISS, обычно требуют повторной индексации, поэтому используйте их для в основном статических корпусов. Планируйте повторную индексацию, если поступают новые руководства или необходимо добавить ежедневные журналы. Во многих авиационных системах руководства меняются медленно, но поступают ежедневные журналы/записи отправки, поэтому могут работать гибридные подходы (запись новых векторов в «горячий» индекс на день и слияние каждую ночь).
Краткое содержание
Векторные базы данных и модели встраивания вместе обеспечивают богатый семантический интеллект по данным об авиации. Высококачественные встраивания (например, модели 768–3072D) преобразуют руководства, журналы и описания деталей в доступные для поиска векторы, в то время как специализированные векторные хранилища (Redis, Pinecone, Weaviate, Qdrant, Vespa, FAISS, Milvus) предоставляют индексы ANN и фильтрацию, необходимые в масштабе. В таблице выше сравниваются основные функции: Redis и Qdrant превосходны в низкой задержке с фильтрацией; Pinecone и Milvus блестят в больших масштабах; Weaviate и Vespa поддерживают гибридные (граф+вектор) запросы; FAISS обеспечивает максимальную производительность для пользовательских конвейеров. Выбор встраивания (модель, размерность, нормализация) и настройка индекса (параметры HNSW, квантование) должны быть сбалансированы для отзыва против скорости. В совокупности эти технологии позволяют командам по машинному обучению в авиации создавать передовые инструменты (семантические поисковые интерфейсы, чат-боты для технического обслуживания, предиктивную аналитику), которые преобразуют неструктурированные журналы и руководства в полезные аналитические данные.
Тенденции в сфере технического обслуживания авиации, которые могут получить импульс в неопределенных обстоятельствах
Самолеты остаются в эксплуатации дольше, цепочки поставок — это пороховая бочка, а технологии развиваются в одночасье. Узнайте о тенденциях в области технического обслуживания, которые набирают обороты, и о том, что они значат для операторов, пытающихся оставаться в воздухе и получать прибыль.

April 10, 2026
Mission Control: высокопроизводительная интеллектуальная инфраструктура для критически важных решений с максимальной скоростью
Каждый руководитель, с которым я разговариваю в сфере аэрокосмической промышленности, производства или строительства, говорит одно и то же:
Наши системы становятся умнее, но наши решения не принимаются быстрее и безопаснее с той скоростью, которую требуют операции.
В средах с высокими требованиями к надежности разрыв между данными и решениями — это место, где накапливаются риски. По мере того как операции становятся все более сложными, распределенными и чувствительными ко времени, организациям нужны интеллектуальные системы, которые не просто быстры, но и проверяемые, детерминированные и безопасные по своему замыслу.
Это инженерная философия, лежащая в основе Mission Control, нашей высокопроизводительной интеллектуальной инфраструктуры, созданной для обеспечения скорости принятия решений в режиме реального времени, с возможностью аудита и криптографической защитой.

October 2, 2025
Выбор правильных деталей самолета с анализом допустимых повреждений
Будущее безопасности полетов зависит от запасных частей. Оригинальные, прослеживаемые запасные части обеспечивают оптимальную устойчивость к повреждениям и производительность для авиапарков, обеспечивая максимальную безопасность и эффективность закупок.

September 30, 2025
Как выйти на новые рынки авиации: полное руководство для поставщиков запчастей
Выходите на новые рынки авиационной техники? Узнайте, как поставщики могут анализировать спрос, управлять запасными частями PMA и завоевывать доверие авиакомпаний. Полное руководство по глобальному росту.

