Превращайте аналитические выводы ИИ в реальные действия
ИИ для документов авиационного класса. Точность, которая работает.
июня 11, 2025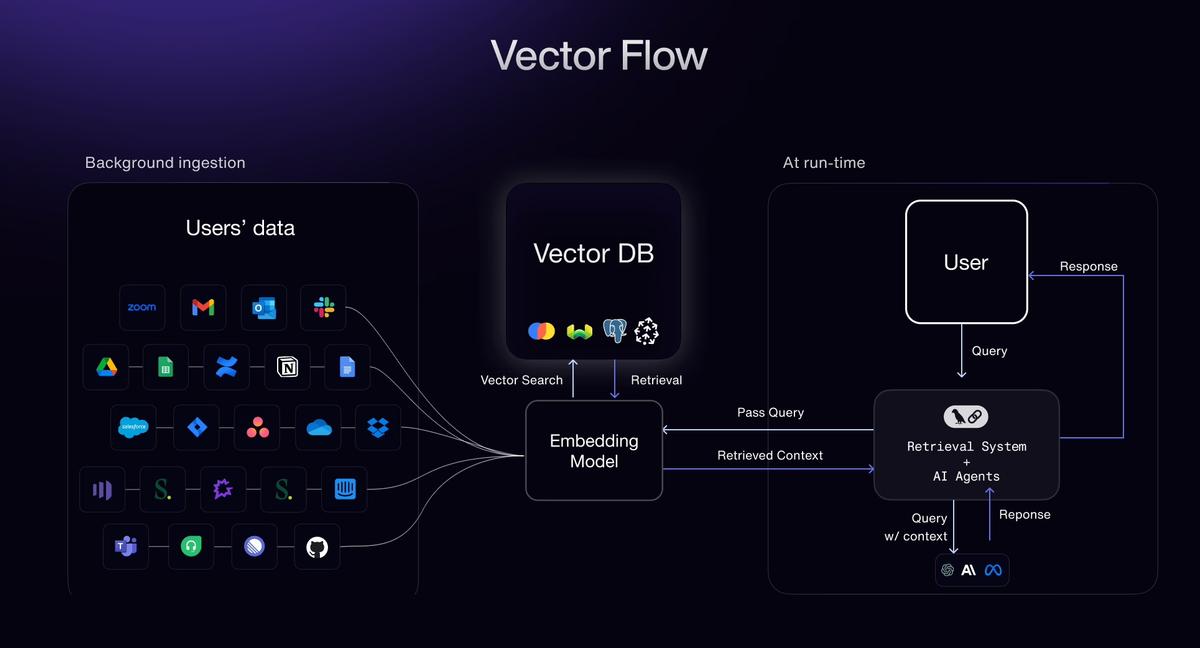
Введение: поток авиационных документов и императив точности
Авиационная отрасль переполнена критически важными документами — сертификатами летной годности, иллюстрированными каталогами деталей (IPC), руководствами по техническому обслуживанию, сервисными бюллетенями FAA/директивами летной годности, бортовыми журналами и многим другим. Эти неструктурированные, объемные документы являются источником жизненной силы авиационных операций и соответствия требованиям. Например, один коммерческий самолет США может производить до7500 страниц новых документов в годдля соответствия требованиям DOT и FAA. Обеспечение того, чтобы системы ИИ могли надежно интерпретировать и использовать эту гору данных, не подлежит обсуждению. В строительствеИИ авиационного класса, выделяется один принцип:Качество результатов ИИ зависит только от точности извлечения базовых данных.. Другими словами, если извлечение данных из вашего документа имеет недостатки, даже самая продвинутая модель ИИ будет распространять эти ошибки — классический сценарий «мусор на входе, мусор на выходе». Поэтому руководители ИИ и технические группы должны расставить приоритетывысокоточное извлечение данных из документовкак основа любого конвейера авиационного ИИ.
Неструктурированные данные в авиации: проблемы и необходимость
Предприятия авиации зависят от неструктурированных документов во всем, от соответствия нормативным требованиям до ежедневных операций. Рассмотрим лишь несколько примеров:
- Нормативные документы:Сертификаты летной годности, FAAСервисные бюллетени (SB) и Директивы летной годности (AD)бюллетени, сертификаты безопасности и отчеты об инцидентах являются обязательными и часто проверяются. Любая неверная информация может привести к нарушению правил или приземлению самолета.
- Технические руководства: Руководства по техническому обслуживанию и МПКсодержат сложные номера деталей, схемы сборки и процедуры, на которые полагаются инженеры и механики. Они часто занимают тысячи страниц и представлены в разных форматах (сканированные PDF-файлы, устаревшие распечатки), что затрудняет автоматизированный анализ.
- Оперативные журналы:Журналы регистрации пилотов, журналы технического обслуживания и рабочие заказы фиксируют текущие эксплуатационные данные. Обычно они имеют свободную форму и написаны от руки или напечатаны, что добавляет еще один уровень сложности для извлечения.
- Документы по закупкам и инвентаризации:Иллюстрированные каталоги деталей и списки деталей, запросы на предложение (RFQ), заказы на покупку и гарантийные записи используются для закупки деталей и управления запасами. Ошибки при извлечении номеров деталей или количеств могут привести к дорогостоящим ошибкам в инвентаризации.
Как с этим справитьсяпоток документовявляется сложным, поскольку данные неструктурированы — заключены в описания на естественном языке, таблицы и формы. Предполагается, что80% корпоративных данных неструктурированы, скрываясь в PDF-файлах, электронных письмах и отсканированных формах. Авиационные компании хорошо знают эту боль: по данным IDC, сотрудники могут тратить ~30% своего времени просто на поиск и консолидацию информации в документах. Последствия плохого качества данных серьезны — IBM подсчитала, что плохие данные обходятся экономике США примерно в3,1 триллиона долларов в год. В авиации ставки еще выше: неправильно заполненные или неправильно прочитанные записи о техническом обслуживании могут привести к остановке флота, а неправильный номер детали может означать неудачный ремонт или риск для безопасности. Документы большого объема с высокими ставками требуют точности извлечения высочайшего порядка.
Мусор на входе, мусор на выходе: почему важна точность извлечения
Современные модели ИИ – будь тоLLM (Большая языковая модель)ответы на вопросы по обслуживанию или система обнаружения аномалий, указывающая на проблемы соответствия, — настолько хороши, насколько хороши данные, которые в них подаются. Если OCR-движок неправильно считывает «O-ring part 65-45764-10» как «O-ring part 65-45764-1O» (перепутав ноль с «O»), система ИИ может не найти критическую историю детали или, что еще хуже, выдать неверную рекомендацию. Высокоточное извлечение данных — это не просто приятное дополнение; этопредпосылка для любого точного результата ИИв авиации. Это особенно актуально длягенерация дополненной поисковой информации (RAG)конвейеры и поисковые приложения. В настройке RAG LLM, например GPT-4o, дополняется фактическими фрагментами из вашей базы данных документов. Если эти фрагменты извлечены неправильно или с отсутствующим контекстом, LLM неизбежно выдаст неверные ответы, независимо от того, насколько сложна или велика модель. Аналогично, поисковые и аналитические системы выдадут ложные результаты, если базовый индекс был заполнен шумными данными. Короче говоря,Производительность ИИ-данных на нисходящем этапе быстро снижается, когда точность извлечения данных на восходящем этапе снижается– независимо от размера или мастерства модели. Обеспечение точности, близкой к наземной, на этапе приема данных – единственный способ доверять выводам, которые впоследствии будут получены вашими решениями в области авиационного ИИ.
Помимо универсальных инструментов: аргументы в пользу ИИ-документов, предназначенных специально для авиации
Не все документы обрабатываются одинаково. Инструменты AI для обработки документов общего назначения (часто оптимизированные для счетов-фактур или простых форм) испытывают трудности ссложность авиационных документов. Авиационные документы часто содержат плотные таблицы, многоуровневые сборки, специализированную терминологию (коды деталей, главы ATA и т. д.) и даже рукописные аннотации. Универсальный OCR или анализатор форм упустит нюансы — например, он может прочитать страницу иллюстрированного каталога деталей как беспорядок текста, тогда как обученная в авиации модель знает, как сегментировать номера деталей, номенклатуру, диапазоны эффективности и иерархии сборок.
Точность, специфичная для домена:Наш ориентированный на авиацию ИИ документов был разработан с нуля для этой сложности. Он не рассматривает страницу IPC как просто любую таблицу — он понимаетструктура и отношения на уровне частей. Например, при извлечении IPC Boeing модель фиксируетразбивка частей позиций, включая родительско-дочерние сборки(например, распознавание того, что деталь 65-45764-10 является компонентом родительской сборки 69-33484-2, которая, в свою очередь, находится в более высокой сборке 65-38196-5). Это сохранение иерархии имеет решающее значение: это означает, что ваш ИИ не просто знает детали, но и то, как они соединяются вместе в самолете. Универсальные инструменты просто не предлагают этот уровень контекстного структурирования.


Лидерство в точности:Специализированная подготовка обеспечивает превосходную точность. Наш ИИ-документ достигаетточность более 98% на полевом уровне, и 99%+ на уровне персонажана авиационных документах. Другими словами, более 98 из 100 извлеченных полей (таких как «Номер детали», «Серийный номер», «Дата установки» и т. д.) абсолютно верны — показатель, недостижимый большинством готовых OCR-сервисов для этих типов документов. Точность на уровне символов, превышающая 99%, означает, что даже в длинных номерах деталей или буквенно-цифровых кодах ошибки встречаются крайне редко. Такой уровень точности является результатом доменно-специфичных моделей OCR, проверок валидности NLP и постоянной тонкой настройки авиационных данных. Он намного превосходит то, чего мог бы достичь универсальный процессор счетов-фактур, если бы его бросили, скажем, на журнал технического обслуживания или форму соответствия FAA.В этой нише наше решение является лидером по точности., специально созданный для нужд авиации.
Более того, метаданные соответствияи детали, специфичные для формы, обрабатываются изящно. В отличие от универсального инструмента, который может пропустить нестандартное поле формы, ИИ авиационного документа знает, что нужно извлекать поля, такие как «Номер сертификата типа» из Сертификата летной годности или раздел «Эффективность» из Сервисного бюллетеня, потому что они имеют решающее значение в контексте. Сосредоточившись надетали на уровне частей, контекст на уровне форм и нормативные метаданные, решение гарантирует, что никакие критические данные не будут упущены. Этот акцент на сложности авиации отличает специализированный Document AI — он говорит на языке авиационных документов, тогда как общие модели остаются косноязычными.
Авиационный документ ИИ в цифрах
Чтобы проиллюстрировать производительность и возможности нашего ИИ-решения для обработки документов авиационного уровня, приведем некоторые ключевые показатели и характеристики:
- Точность на уровне поля > 98%– Основные поля данных (идентификаторы деталей, даты, флажки соответствия и т. д.) правильно фиксируются с точностью более 98%file-q7xvjvhip1lffe4hbnkuac, даже в разных макетах документов. Это значительно снижает необходимость в человеческом вмешательстве.
- Точность распознавания символов на уровне символов > 99%– Благодаря надежному OCR (и использованию собственных текстовых слоев, когда это возможно), распознавание символов происходит практически без ошибокfile-q7xvjvhip1lffe4hbnkuac. Например, серийные номера или коды деталей длиной в десятки символов воспроизводятся точно, сохраняя критически важные идентификаторы.
- Поддержка Boeing IPC (сборки захвачены)– В настоящее время поддерживаетДокументы Boeing IPC, разбирая каждую позицию. Экстрактор понимает схему IPC: он извлекает такие поля, как Номер рисунка, Номер элемента, Номер детали, Номенклатура, Единицы на сборку и Диапазоны эффективности. Важно, что онфиксирует отношения родитель/потомок, реконструируя иерархию деталей в каждой сборке. Это означает, что ваш ИИ может отвечать на запросы о том, как вложены компоненты, или идентифицировать все подчасти в данной сборке — возможности, недостижимые с помощью универсальных парсеров.
- Масштаб – 1000 страниц одновременно– Система прошла полевые испытания наПропускная способность приема 1 тыс. страниц параллельно, запустив 5 параллельных пакетов по 200 страниц каждыйfile-q7xvjvhip1lffe4hbnkuac. На практике это означает, что целая библиотека руководств или годовые журналы могут быть обработаны за считанные минуты. Высокая пропускная способность гарантирует, что дажебольшие объемы невыполненных заказовили потоки документов в реальном времени (например, внезапный сброс новых записей о техническом обслуживании) могут обрабатываться без перебоев.
- Разделение и классификация документов в реальном времени– Большие руководства в формате PDF или комбинированные наборы документов автоматическиразделен на отдельные документы или разделыдля целевой обработкиfile-q7xvjvhip1lffe4hbnkuac. Основанный на ИИклассификатор документовсначала определяет тип документа (например, отличая иллюстрированный каталог деталей от руководства по техническому обслуживанию или сертификата летной годности), чтобы направить его в правильный конвейер извлеченияfile-q7xvjvhip1lffe4hbnkuac. Эта классификация имеет почти 100% отзыв, гарантируя, что ни один документ не будет неправильно идентифицирован или пропущен. Разделение и классификация происходят на лету, что позволяет обрабатывать непрерывные потоки документов смешанных типов точно в режиме реального времени.
- Структурированный вывод для легкой интеграции– Извлеченные данные – это не просто сырой текст – они выводятся в виде структурированных записей (JSON, XML и т. д.) с метаданными, такими как тип документа, заголовки разделов и даже ссылки на страницы. Этозахват структуры документаозначает, что вы сохраняете контекст: каждая точка данных знает, откуда она взялась (страница X руководства Y, раздел Z). Такая структура бесценна при передаче данных в другие системы или аудиты.
В целом, сочетание сверхвысокой точности и доменно-ориентированных функций (например, захват иерархии сборки) делает это решение уникальным для обработки авиационных документов в масштабе. Далее давайте посмотрим, как эти возможности подключаются к конвейеру ИИ.
Обзор технического конвейера: от документов до данных, готовых к использованию ИИ
Чтобы построить эффективнуюКонвейер ИИ для авиационных данных, мы рекомендуем поэтапный подход. Вот обзор конвейера, от приема необработанных документов до доставки векторов для моделей ИИ:
- Прием (PDF-файлы и сканы):Принимать документы из различных источников — будь то сканы высокого разрешения, PDF-файлы со встроенным текстом или изображения. Конвейер может приниматьотсканированные бумажные записии применять расширенное OCR при необходимости или напрямую анализировать текст из цифровых PDF-файлов (используя текстовый слой для точности 99,9 %, если он доступен). Этап приема нормализует форматы файлов и помещает документы в очередь для обработки. Он предназначен для обработки массовых загрузок и потоковых входных данных, инициируя последующие задания, как только поступают новые файлы (поддержка обработки, управляемой событиями, для систем реального времени).
- Классификация:Затем классификатор на базе искусственного интеллекта определяет тип и назначение каждого документаfile-q7xvjvhip1lffe4hbnkuac. Например, он маркирует документы как «Сертификат летной годности», «IPC – Boeing 737», «Карта задач по техническому обслуживанию», «Бюллетень FAA AD» и т. д. Этот шаг имеет решающее значение, поскольку логика извлечения часто зависит от шаблона. Высокая точность классификации (с почти 100% отзывом) гарантирует, что каждый документ будет направлен в правильную модель извлечения или набор правил. Если документ содержит несколько разделов (например, объединенный PDF-файл с несколькими формами), этот этап также сегментирует эти разделы по типу.
- Автоматическое разделение:Большие руководства или PDF-файлы, содержащие несколько документов, автоматическиразделить на логические единицыfile-q7xvjvhip1lffe4hbnkuac. Например, руководство по техническому обслуживанию объемом 500 страниц может быть разделено по главам или задачам, или IPC PDF, охватывающий несколько разделов, будет разделен по разделам/рисункам. Аналогично, стопка отсканированных страниц бортового журнала будет разделена на отдельные изображения страниц для параллельной обработки. Разделение ввода служит двум целям: оно позволяетпараллельная экстракция(значительно ускоряя обработку) и обеспечивает соблюдение границ контекста (чтобы каждый фрагмент мог обрабатываться независимо для последующих задач, таких как встраивание). Это делается в режиме реального времени; как только принимается большой файл, система начинает его разделять и одновременно подавать страницы/разделы на стадию извлечения.
- Высокоточное извлечение:Это основной этап, на котором вступает в действие механизм извлечения документов AI. Используя комбинацию моделей OCR, специфичных для шаблонов, анализаторов NLP и проверок валидности, системаизвлекает структурированные данные с точностью авиационного уровня. Ключевые поля вытягиваются в соответствии с типом документа — для IPC: номера деталей, номенклатура, ссылки на узлы и т. д.; для журнала технического обслуживания: даты, выполненные действия, заметки механика; для нормативной формы: идентификаторы сертификатов, сроки действия, подписи и т. д.Контекстная целостностьподдерживается: вывод сохраняет, из какого раздела или таблицы пришло поле, и поля связаны (например, все элементы строки под рисунком или все записи под определенной датой). Результатом является структурированный набор данных, представляющий информацию документа. При точности >98% на уровне поля требуется очень минимальная человеческая проверка, и любые падения уверенности или аномалии могут быть отмечены для проверки.
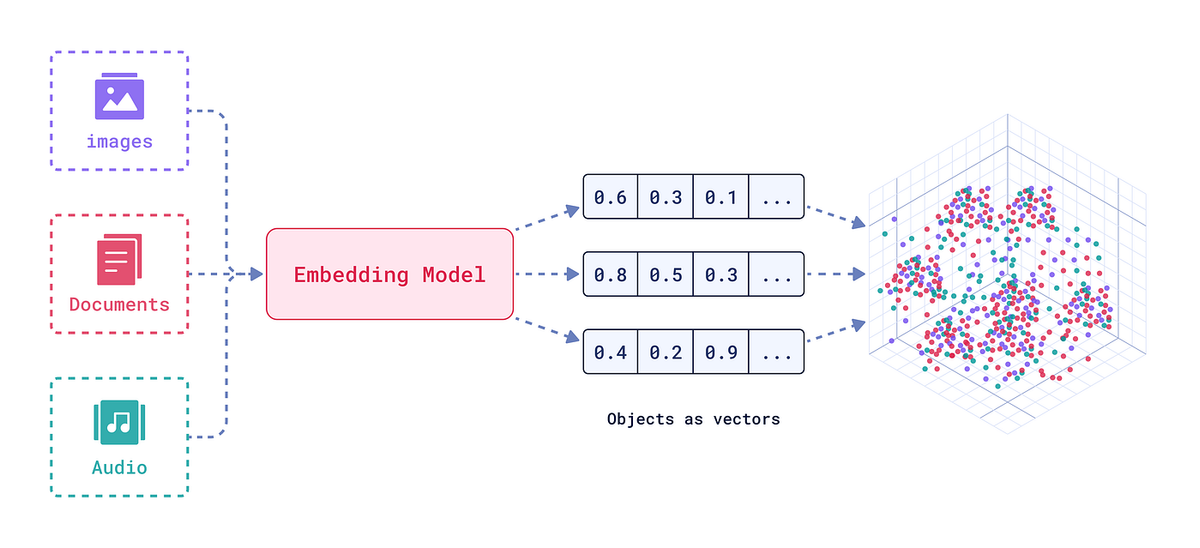
- Встраивание и векторизация:После извлечения текстовых данных их можно преобразовать в векторные вложения для потребления ИИ. Конвейер интегрируется сосновные модели встраивания– вы можете подключить свою модель по выбору (например, API встраивания текста OpenAI, Sentence-BERT или другие преобразователи на основе кодировщиков) для преобразования каждого фрагмента документа или записи данных в многомерный вектор. Мы поддерживаем пользовательскиестратегии фрагментацииздесь: например, вы можете встроить каждый абзац или каждый раздел отдельно, чтобы оптимизировать последующий поиск. Система может автоматически разбивать большие текстовые поля (например, длинные ручные абзацы) на фрагменты, размеры которых идеально подходят для вашего контекстного окна LLM, или вы можете определить правила разбиения на фрагменты (по предложению, по подразделу и т. д.). Такая гибкость гарантирует, что встраивания будут захватывать значимые фрагменты информации без усечения контекста. К концу этого шага каждый документ (или раздел документа) будет представлен одним или несколькими векторами встраивания, обычно сопровождаемыми метаданными (идентификатор документа, заголовок раздела, ссылка на источник).
- Внедрение векторной базы данных:Наконец, векторы и метаданныевведено в векторную базу данныхпо вашему выбору. Решение работает из коробки с популярными векторными магазинами, такими какРедис(с векторами RediSearch),Шишка, или Эластичный(возможность поиска векторов Elastic) и т. д. Это означает, что извлеченные из документов знания становятся доступными для немедленного поиска с помощью поиска по сходству или могут использоваться в генерации с расширенным поиском. Например, теперь вы можете запрашивать свою коллекцию документов на естественном языке и извлекать наиболее релевантные фрагменты в векторном пространстве, или ваш помощник ИИ может извлекать соответствующие разделы руководства по техническому обслуживанию, чтобы ответить на вопрос. Конвейер гарантирует, что вместе с каждым вектором сохраняются исходный текст и ссылка на документ, поэтому при обнаружении совпадения вектора вы можете проследить его до исходного документа/страницы. Также поддерживаются обновления в реальном времени — если поступают новые документы, их вставки можно вставлять на лету, поддерживая базу данных векторов и базу знаний вашего ИИ в актуальном состоянии.
Этот конвейер обеспечивает плавный поток от сырых неструктурированных входных данных до структурированной информации, готовой к использованию ИИ. Каждый этап оптимизирован для вариантов использования в авиации — от понимания форматов документов, специфичных для домена, до масштабирования обработки на тысячи страниц одновременно. Конечный результат —База данных векторов с богатыми знаниямикоторый поддерживает поиск, аналитику или большие языковые модели сточные, контекстно-обогащенные данные.
Обеспечение масштабируемой производительности и надежности
Разработка архитектуры для обработки документов в масштабах авиации подразумевает обработку каквысокая пропускная способность и высокая надежность. Что касается пропускной способности, как уже отмечалось, наш ИИ-документ может принимать и обрабатывать документы параллельно – успешно.обработка 1000 страниц одновременнов недавних полевых испытанияхfile-q7xvjvhip1lffe4hbnkuac. Это было достигнуто с помощью подхода горизонтального масштабирования: несколько рабочих извлечения одновременно работают с разными пакетами страниц. Система является облачной и может автоматически масштабироваться с нагрузкой, то есть, независимо от того, нужно ли вам проанализировать 100 или 100 000 страниц, она может выделять ресурсы для удовлетворения спроса. Для команды ИИ эта масштабируемость означает минимальное время ожидания между приемом данных и пониманием — критически важно, когда вам нужно, скажем, быстро добавить библиотеку документации нового самолета в свою аналитическую платформу.
Надежность достигается не только за счет точности; она также зависит отправильное отражение структуры и контекста. Например, захват структуры документагарантирует, что при использовании данных ниже по потоку вы знаете контекст. Если векторный поиск выводит фрагмент о «значении крутящего момента: 50 Нм», система знает, из какого руководства по техническому обслуживанию и раздела он был получен, и может по запросу получить изображение всего раздела или страницы. Это бесценно для проверки и для того, чтобы конечные пользователи доверяли выходным данным ИИ — они всегда могут сослаться на исходный фрагмент документа, который использовал ИИ. Структурированные выходные данные нашего конвейера включают эти контекстные маркеры по умолчанию.
Кроме того, решение было протестировано на реальных вариациях документов. Авиационные документы могут быть запутанными — сканы со штампами, рукописный текст или немного отличающиеся макеты между производителями. Document AI используетансамбль OCRподходы (объединение нескольких OCR-движков и механизма голосования) при работе с шумными сканированиями, и он использует правила проверки (например, проверки контрольной суммы номеров деталей, проверки формата даты и т. д.) для обнаружения любых аномалий извлечения. Это означает, что даже при превышении пределов пропускной способности система поддерживает высокую планку точности. Во внутренних тестах с Boeing IPC точность символов OCR была измерена на уровне99,9%на документах с существующим текстовым слоем и лишь незначительно ниже на чистых сканированных изображениях благодаря усовершенствованным моделям OCR. Захватывая доменно-специфическую структуру (например, оглавление руководств или разделы в журналах регистрации), система также может разделять и восстанавливаться после ошибок изящно — например, если одна страница особенно плохого качества, она изолируется и помечается, а не сбивает с пути всю партию.
Для команд инженеров ИИ эти возможности устраняют основную головную боль: вы можете доверять данным, поступающим из вашего конвейера документов. Вам не придется устранять ошибки OCR или писать специальные регулярные выражения для каждого нового типа документа. Вместо этого фокус может сместиться на создание мощных приложений ИИ (например, моделей предиктивного обслуживания, построения графа знаний или инструментов аудита соответствия) поверх этого надежного слоя данных.
Влияние на ИИ в нисходящем направлении: RAG, LLM и поиск
Стоит еще раз подчеркнуть, как это высокоточное извлечение используется для последующих задач ИИ. РассмотримИзвлечение-Дополненная Генерация (RAG): здесь большая языковая модель (LLM) дополняется соответствующими документами или фрагментами, извлеченными из базы знаний. Если ваша база знаний представляет собой векторную базу данных авиационных документов, созданную путем неаккуратного извлечения, LLM может быть предоставлен нерелевантный или неправильный текст, что приведет к генерации неточного или галлюцинаторного ответа. Напротив, предоставление LLMчистые, точные фрагментыиз нашего конвейера Document AI означает, что модель может генерировать ответы, основанные на истине. Мы заметили, что, повышая точность на уровне поля выше 98%, мы значительно повышаем точность результатов поиска (меньше ложных совпадений) и, таким образом, качество ответов в условиях вопросов и ответов по авиации. По сути, LLM может сосредоточиться на своей работе по пониманию и составлению ответов, а не на внутренней борьбе с искаженными входными данными. Результатом является гораздо более надежная помощь ИИ для инженеров и лиц, принимающих решения.
Та же логика применима к простому семантическому поиску или системам вопросов и ответов, которые не предполагают генерацию. Например, авиакомпания может построитьпоисковый порталдля техников по техническому обслуживанию для запроса прошлых записей о ремонте или руководств. Если индекс, лежащий в основе этого поиска, построен на точно извлеченных данных, результаты поиска заслуживают доверия — возвращенные записи действительно содержат термины запроса или соответствующую информацию. В противном случае поиск может пропустить важные документы (низкая полнота) или обнаружить неправильные (ложные срабатывания), что подорвет доверие пользователя. Высокоточное извлечение гарантирует, что при поиске «соответствие AD топливного насоса» вы действительно получите соответствующий документ Директивы о летной годности и связанные с ним записи о соответствии, а не кучу шума.
Неважно, насколько продвинуты ваши модели ИИ, даже если вы используете современный преобразователь с 175 миллиардами параметров,их результаты могут быть сбиты с толку неверными входными данными. В контексте авиации, где безопасность и соответствие нормативным требованиям находятся на кону, это не просто незначительное неудобство; это серьезный риск. Вот почему мы настаиваем на верхнем уровне извлечения. Он действует какединственный источник истины, преобразуя ваши неструктурированные документы в чистое, доступное для запросов и готовое к использованию ИИ хранилище знаний.
Заключение: закладываем основу для успеха ИИ авиационного уровня
Для руководителей и технических групп по ИИ в авиационном секторе послание очевидно:Инвестируйте в точность данных на начальном этапе вашего конвейера ИИ. Объемные, сложные авиационные документы являются мощным источником истины, и извлечение их данных с почти идеальной точностью — единственный способ раскрыть эту истину для ваших систем ИИ. Экономия на качестве извлечения — ложная экономия; любая экономия будет сведена на нет плохой производительностью ИИ позже или, что еще хуже, критически важным пониманием, упущенным из-за плохой точки данных. Развертывая специализированный для авиации ИИ документов с точностью ~98-99%+, вы создаете прочную основу для всех последующих приложений, от предиктивного обслуживания и оптимизации парка до аудита соответствия и интеллектуальных помощников.
В итоге, Высокоточный ИИ-документ — основа ИИ авиационного уровня. Он превращает горы неструктурированной бумажной работы в надежные, структурированные данные. С этим на месте, вашLLM, графы знаний и аналитические панелиможет взлететь — предоставляя точные, действенные идеи, которые обеспечивают безопасность и эффективность операций. Без этого даже самый мощный ИИ будет спотыкаться на шатких входных данных. Поскольку авиационная отрасль принимает цифровую трансформацию и ИИ, те, кто строит на основе чистого, точного извлечения данных, получат решающее преимущество. Это как иметь сверхнадежный компас перед полетом — вы бы не взлетели без него, и точно так же ни одно путешествие ИИ не должно начинаться без надежных данных. Внедряя высокоточное решение Document AI в свой конвейер — в комплекте с настроенными на домен моделями, надежным OCR и бесшовной интеграцией с векторными базами данных — вы гарантируете, что ваши инициативы в области авиационного ИИ будут допущены к взлету с уверенностью и точностью.
Тенденции в сфере технического обслуживания авиации, которые могут получить импульс в неопределенных обстоятельствах
Самолеты остаются в эксплуатации дольше, цепочки поставок — это пороховая бочка, а технологии развиваются в одночасье. Узнайте о тенденциях в области технического обслуживания, которые набирают обороты, и о том, что они значат для операторов, пытающихся оставаться в воздухе и получать прибыль.

April 10, 2026
Mission Control: высокопроизводительная интеллектуальная инфраструктура для критически важных решений с максимальной скоростью
Каждый руководитель, с которым я разговариваю в сфере аэрокосмической промышленности, производства или строительства, говорит одно и то же:
Наши системы становятся умнее, но наши решения не принимаются быстрее и безопаснее с той скоростью, которую требуют операции.
В средах с высокими требованиями к надежности разрыв между данными и решениями — это место, где накапливаются риски. По мере того как операции становятся все более сложными, распределенными и чувствительными ко времени, организациям нужны интеллектуальные системы, которые не просто быстры, но и проверяемые, детерминированные и безопасные по своему замыслу.
Это инженерная философия, лежащая в основе Mission Control, нашей высокопроизводительной интеллектуальной инфраструктуры, созданной для обеспечения скорости принятия решений в режиме реального времени, с возможностью аудита и криптографической защитой.

October 2, 2025
Выбор правильных деталей самолета с анализом допустимых повреждений
Будущее безопасности полетов зависит от запасных частей. Оригинальные, прослеживаемые запасные части обеспечивают оптимальную устойчивость к повреждениям и производительность для авиапарков, обеспечивая максимальную безопасность и эффективность закупок.

September 30, 2025
Как выйти на новые рынки авиации: полное руководство для поставщиков запчастей
Выходите на новые рынки авиационной техники? Узнайте, как поставщики могут анализировать спрос, управлять запасными частями PMA и завоевывать доверие авиакомпаний. Полное руководство по глобальному росту.

