AIによるインサイトを行動へとつなげる
航空グレードのドキュメント AI。優れた精度でパフォーマンスを発揮します。
7月 06, 2025はじめに:航空業界の文書の氾濫と正確性の必要性
航空業界は、耐空証明、図解部品カタログ(IPC)、整備マニュアル、FAAサービス速報/耐空性指令、ログブックなど、重要な文書で溢れています。これらの非構造化かつ膨大な量の文書は、航空運航とコンプライアンスの生命線です。例えば、米国の民間航空機1機あたり、最大で年間7,500ページの新規文書DOTとFAAの要件を満たす必要があります。AIシステムがこの膨大なデータを確実に解釈し、活用できることを保証することは不可欠です。航空グレードのAI1 つの原則が際立っています。AI出力の品質は、基礎となるデータ抽出の精度によってのみ決まる。つまり、文書データの抽出に欠陥があれば、どんなに高度なAIモデルでもそのエラーは伝播してしまうということです。これは典型的な「ゴミを入れればゴミが出る」という状況です。そのため、AIリーダーと技術チームは、以下の点を優先する必要があります。高精度な文書データ抽出あらゆる航空 AI パイプラインの基盤として。
航空業界における非構造化データ:課題と必要性
航空企業は、規制遵守から日常業務まで、あらゆる場面で非構造化文書に依存しています。いくつかの例を見てみましょう。
- 規制文書:耐空証明、FAAサービス速報(SB) そして 耐空性指令(AD)速報、安全認証、事故報告書は必須であり、頻繁に監査されます。不正確な情報があると、コンプライアンス違反や航空機の運航停止につながる可能性があります。
- 技術マニュアル: メンテナンスマニュアル そして IPCエンジニアや整備士が頼りにする複雑な部品番号、組立図、手順書などが含まれています。これらは数千ページに及ぶことが多く、スキャンしたPDFや過去の印刷物など、さまざまな形式で提供されるため、自動解析は困難です。
- 操作ログ:パイロットログブック、整備記録、作業指示書には、進行中の運用データが記録されます。これらは通常、自由形式で手書きまたは入力されているため、抽出がさらに複雑になります。
- 調達および在庫ドキュメント:イラスト付き部品カタログと部品リスト、見積依頼書(RFQ)、発注書、保証記録は、部品調達と在庫管理に使用されます。部品番号や数量の抽出ミスは、コストのかかる在庫ミスにつながる可能性があります。
これに対処する文書の洪水データが構造化されていないため、つまり自然言語による記述、表、フォームに閉じ込められているため、困難です。推定によると、企業データの80%は非構造化データであるPDF、メール、スキャンした書類の中に隠れているデータ。航空会社はこの悩みをよく理解している。IDCによると、従業員は書類間の情報検索と統合に約30%の時間を費やしている。データ品質の低さは深刻な結果をもたらす。IBMは、不良データが米国経済に約1000億ドルの損失をもたらしていると推定している。年間3.1兆ドル航空業界では、そのリスクはさらに大きくなります。整備記録のファイリングミスや読み間違いは航空機の運航停止につながり、部品番号の誤りは修理の失敗や安全上のリスクにつながる可能性があります。大量の重要な文書は、最高レベルの抽出精度が求められます。
ゴミを入れればゴミが出る:精密抽出が重要な理由
現代のAIモデル – それがLLM(大規模言語モデル)メンテナンスに関する質問に答えたり、コンプライアンス問題を警告する異常検知システムなど、AIシステムの精度は、入力されるデータの質に左右されます。OCRエンジンが「Oリング部品番号 65-45764-10」を「Oリング部品番号 65-45764-1O」(ゼロを「O」と読み間違える)と誤読した場合、AIシステムは重要な部品の履歴を見つけられなかったり、最悪の場合、誤った推奨結果を出力する可能性があります。高精度なデータ抽出は、単にあれば良いというものではなく、正確なAI結果の前提条件航空業界では特に検索拡張生成(RAG)パイプラインや検索アプリケーションでも同様です。RAG構成では、GPT-4oのようなLLMは、ドキュメントデータベースから抽出された事実に基づくスニペットで拡張されます。これらのスニペットが誤って抽出されたり、コンテキストが欠落していたりすると、モデルがどれほど洗練されていたり大規模であったとしても、LLMは必然的に誤った結果を生成します。同様に、検索システムや分析システムも、基盤となるインデックスにノイズの多いデータが入力された場合、誤った結果を返します。つまり、上流の抽出精度が低下すると、下流のAIパフォーマンスは急速に低下するモデルの規模や性能に関わらず、データ取り込み段階でほぼ真実に近い精度を確保することが、航空AIソリューションによって後から得られる知見を信頼できる唯一の方法です。
汎用ツールを超えて:航空業界に特化したドキュメントAIの事例
すべての文書処理が同じというわけではありません。一般的な文書AIツール(請求書や簡単なフォームに最適化されているものが多い)は、航空文書の複雑さ航空文書には、複雑な表、多層構造のアセンブリ、専門用語(部品コード、ATA章など)、さらには手書きの注釈が含まれることがよくあります。汎用的なOCRやフォームパーサーでは、ニュアンスを捉えきれません。例えば、図解部品カタログのページをテキストの羅列として読み取ってしまう可能性がありますが、航空業界向けに訓練されたモデルは、部品番号、名称、有効範囲、アセンブリ階層をセグメント化する方法を理解しています。
ドメイン固有の精度:航空業界に特化したDocument AIは、この複雑な状況に対応するためにゼロから設計されました。IPCページを単なる表として扱うのではなく、部品レベルの構造と関係例えば、ボーイングのIPCを抽出する場合、モデルは親子アセンブリを含む行項目部品の内訳(例えば、部品65-45764-10が親アセンブリ69-33484-2の下位コンポーネントであり、さらに上位アセンブリ65-38196-5の下位コンポーネントであることを認識するなど)。この階層構造の維持は非常に重要です。AIは部品だけでなく、それらが航空機内でどのように組み合わされているかまで把握できるからです。汎用ツールでは、このようなレベルのコンテキスト構造化は不可能です。


精度リーダーシップ:専門的なトレーニングにより優れた精度を実現。当社のDocument AIは現場レベルで98%以上の精度、 そして キャラクターレベルで99%以上航空文書の精度は、非常に高い精度です。つまり、抽出された100項目(「部品番号」、「シリアル番号」、「取り付け日」など)のうち98項目以上が正確に認識されます。これは、これらの文書タイプにおいて、ほとんどの市販OCRサービスでは達成できない精度です。文字レベルの精度は99%を超えており、長い部品番号や英数字コードであっても、エラーは極めてまれです。このレベルの精度は、ドメイン固有のOCRモデル、NLP検証チェック、そして航空データに対する継続的な微調整の結果です。これは、一般的な請求書処理ソフトが、例えば整備記録やFAAコンプライアンスフォームなどを処理した場合に達成できる精度をはるかに上回ります。このニッチ市場において、当社のソリューションは精度のリーダーです航空業界の要求に合わせて特別に設計されました。
さらに、 コンプライアンスメタデータフォーム固有の詳細も適切に処理されます。非標準フォームフィールドを省略してしまうような汎用ツールとは異なり、航空文書AIは、耐空証明の「型式証明番号」やサービス速報の「有効性」といった、文脈上重要なフィールドを抽出します。部品レベルの詳細、フォームレベルのコンテキスト、規制メタデータこのソリューションは、重要なデータが取り残されることがないよう徹底しています。航空業界の複雑な状況に特化している点が、特化型Document AIの特徴です。汎用モデルでは理解しにくいのに対し、この特化型Document AIは航空文書の言語を理解します。
数字で見る航空文書AI
航空グレードの Document AI のパフォーマンスと機能を説明するために、いくつかの主要な指標と機能をご紹介します。
- フィールドレベルの精度 > 98%– 重要なデータフィールド(部品ID、日付、コンプライアンスチェックボックスなど)は、ドキュメントレイアウトが異なっていても、98%以上の精度で正確にキャプチャされます。これにより、人手による修正の必要性が大幅に削減されます。
- 文字レベルのOCR精度 > 99%– 堅牢なOCR(および利用可能な場合はネイティブテキストレイヤーの使用)により、文字認識はほぼエラーフリーです。例えば、数十文字に及ぶシリアル番号や部品コードも正確に再現され、重要な識別子が保持されます。
- ボーイングIPCサポート(アセンブリキャプチャ)– 現在サポートボーイングIPC文書全ての行項目を解析します。抽出ツールはIPCスキーマを理解しており、図番号、品目番号、部品番号、名称、組立単位数、有効範囲などのフィールドを取得します。重要なのは、親子アセンブリ関係をキャプチャします各アセンブリ内のパーツの階層を再構築します。これにより、AIはコンポーネントのネスト方法に関するクエリに回答したり、特定のアセンブリに含まれるすべてのサブパーツを識別したりできるようになります。これは、汎用パーサーでは実現できない機能です。
- 規模 – 1,000ページ同時処理– このシステムは、1kページの並列取り込みスループット200ページずつのバッチを5つ同時に実行することで、ファイルq7xvjvhip1lffe4hbnkuacを処理できます。実際には、マニュアルライブラリ全体や1年分のログブックを数分で処理できます。高いスループットにより、大量のバックログまたは、リアルタイムのドキュメント ストリーム (新しい保守記録の突然の大量送信など) も、処理が滞ることなく処理できます。
- リアルタイムのドキュメント分割と分類– 大きなPDFマニュアルや複合ドキュメントセットは自動的に個別の文書またはセクションに分割対象を絞った処理ファイル-q7xvjvhip1lffe4hbnkuac。AIベースの文書分類器まずドキュメントの種類を判別し(例:イラスト付き部品カタログと整備マニュアル、耐空証明書を区別)、適切な抽出パイプライン(file-q7xvjvhip1lffe4hbnkuac)にルーティングします。この分類はほぼ100%の再現率を誇り、ドキュメントの誤認や漏れを防ぎます。分割と分類はリアルタイムで行われるため、混在するドキュメント種別の連続フィードをリアルタイムかつ正確に処理できます。
- 簡単に統合できる構造化された出力– 抽出されたデータは単なる生のテキストではなく、文書の種類、セクションヘッダー、さらにはページ参照などのメタデータを含む構造化されたレコード(JSON、XMLなど)として出力されます。ドキュメント構造のキャプチャつまり、コンテキストが保持されます。すべてのデータポイントは、その出所(マニュアルYのXページ、セクションZ)を把握できます。このような構造は、データを他のシステムや監査に取り込む際に非常に役立ちます。
つまり、超高精度とドメインに特化した機能(アセンブリ階層のキャプチャなど)を組み合わせることで、このソリューションは航空文書を大規模に処理できる独自の能力を備えています。次に、これらの機能がAIパイプラインにどのように組み込まれるかを見てみましょう。
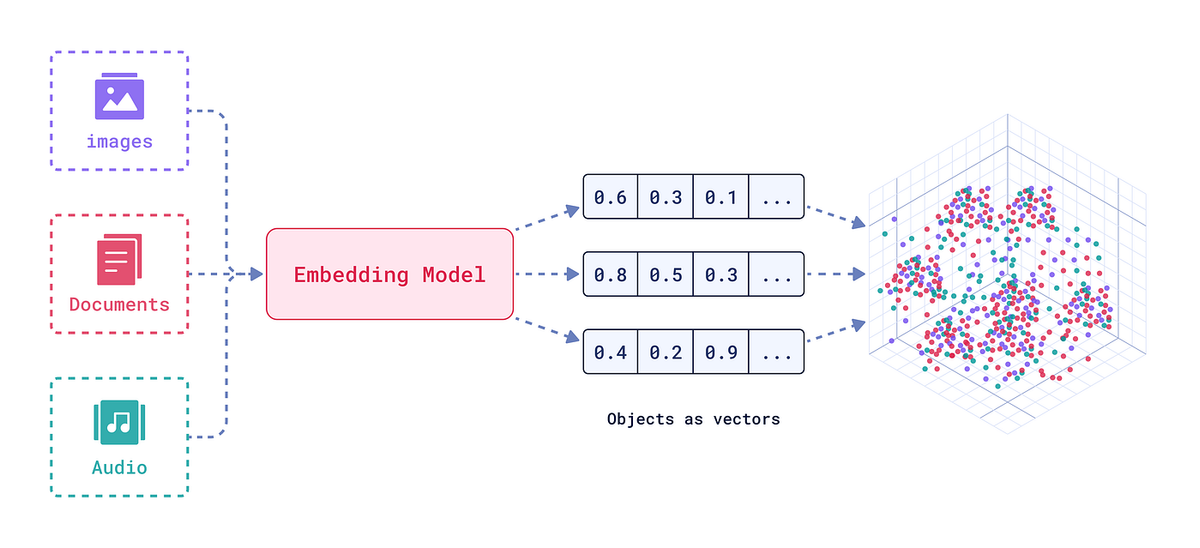
技術パイプラインの概要: ドキュメントから AI 対応データまで
効果的な航空データ向けAIパイプライン段階的なアプローチをお勧めします。生のドキュメントの取り込みからAIモデルへのベクトル配信までのパイプラインの概要は次のとおりです。
- 取り込み(PDFとスキャン):高解像度のスキャン、テキストが埋め込まれたPDF、画像など、さまざまなソースからドキュメントを受け入れます。パイプラインはスキャンされた紙の記録必要に応じて高度な OCR を適用するか、デジタル PDF から直接テキストを解析します(テキスト レイヤーを活用することで、利用可能な場合は 99.9% の精度を実現します)。取り込み段階では、ファイル形式を正規化し、処理対象のドキュメントをキューに入れます。一括アップロードとストリーミング入力を処理するように設計されており、新しいファイルが到着するとすぐに下流のジョブを開始します(リアルタイム システムのイベント駆動型処理をサポートします)。
- 分類:次に、AIを活用した分類器が各文書の種類と目的を識別します。例えば、文書に「耐空証明」「IPC - ボーイング737」「整備作業カード」「FAA AD Bulletin」などのラベルを付けます。抽出ロジックはテンプレートに依存されることが多いため、このステップは非常に重要です。高い分類精度(ほぼ100%の再現率)により、各文書が適切な抽出モデルまたはルールセットにルーティングされます。文書に複数のセクションが含まれている場合(例:複数のフォームが結合されたPDF)、この段階でそれらのセクションも種類別に分割されます。
- 自動分割:複数の文書を含む大きなマニュアルやPDFは自動的に論理単位に分割するfile-q7xvjvhip1lffe4hbnkuac。例えば、500ページのメンテナンスマニュアルは章やタスクごとに分割され、複数のセクションにまたがるIPC PDFはセクション/図ごとに分割されます。同様に、ログブックのスキャンされたページは、並列処理のために個々のページ画像に分割されます。入力を分割することには2つの目的があります。並列抽出(処理を大幅に高速化)そしてコンテキスト境界が尊重されることを保証します(これにより、埋め込みなどの下流タスクにおいて、各チャンクを独立して処理できます)。これはリアルタイムで行われ、大きなファイルが取り込まれるとすぐに、システムはファイルを分割し、ページ/セクションを抽出段階に同時に送り込みます。
- 高精度抽出:これはDocument AI抽出エンジンが作動する中核段階です。テンプレート固有のOCRモデル、NLPパーサー、検証チェックを組み合わせて、システムは航空グレードの精度で構造化データを抽出します主要なフィールドは、ドキュメントの種類に応じて抽出されます。IPC の場合: 部品番号、命名法、アセンブリ参照など。メンテナンス ログの場合: 日付、実行されたアクション、メカニック メモ。規制フォームの場合: 証明書 ID、有効期限、署名など。文脈の整合性構造化データセットは維持されます。出力では、フィールドがどのセクションまたは表から取得されたかが保持され、フィールドはリンクされています(例えば、図のすべての行項目、または特定の日付のすべてのエントリなど)。結果として、文書の情報を表す構造化されたデータセットが生成されます。フィールドレベルで98%を超える精度を実現しているため、人によるレビューは最小限で済み、信頼性の低下や異常があれば検査のためにフラグを付けることができます。
- 埋め込みとベクトル化:テキストデータが抽出されると、AIで利用できるようにベクトル埋め込みに変換できます。パイプラインは主要な埋め込みモデル– お好みのモデル(OpenAIのテキスト埋め込みAPI、Sentence-BERT、その他のトランスフォーマーベースのエンコーダなど)をプラグインして、各ドキュメントチャンクまたはデータレコードを高次元ベクトルに変換できます。カスタムモデルをサポートしています。チャンキング戦略例えば、各段落または各セクションを個別に埋め込むことで、下流の検索を最適化できます。システムは、大きなテキストフィールド(長いマニュアル段落など)をLLMコンテキストウィンドウに最適なスニペットサイズに自動的に分割するか、チャンク化ルール(文ごと、サブセクションごとなど)を定義することもできます。この柔軟性により、埋め込みによってコンテキストを切り捨てることなく、意味のある情報を確実に取得できます。このステップの最後には、各ドキュメント(またはドキュメントセクション)は1つ以上の埋め込みベクトルで表され、通常はメタデータ(ドキュメントID、セクションタイトル、ソース参照)が付随します。
- ベクターデータベースインジェクション:最後に、ベクトルとメタデータはベクターデータベースに注入お好みに合わせてお選びください。このソリューションは、次のような人気のベクターストアですぐにご利用いただけます。レディス(RediSearchベクターを使用)松ぼっくり、 または 弾性(Elasticのベクトル検索機能)など、様々な機能が追加されました。これにより、ドキュメントから抽出された知識は、類似性検索による即時検索や、検索拡張型生成に利用できるようになります。例えば、自然言語でドキュメントコレクションをクエリし、ベクトル空間で最も関連性の高いチャンクを取得したり、AIアシスタントが関連するメンテナンスマニュアルのセクションを取得して質問に答えたりすることが可能になります。パイプラインは、各ベクトルと共に元のテキストとドキュメント参照を保存するため、ベクトルの一致が見つかった場合、元のドキュメント/ページまで遡ることができます。リアルタイム更新もサポートされており、新しいドキュメントが追加されると、その埋め込みを即座に挿入することで、ベクトルDBとAIの知識ベースを最新の状態に維持できます。
このパイプラインは、生の非構造化入力からAI対応の構造化情報へのスムーズな流れを実現します。各段階は航空業界のユースケースに合わせて最適化されており、ドメイン固有の文書形式の理解から数千ページにわたる同時処理のスケールアウトまで、幅広い用途に対応します。その結果、知識豊富なベクターデータベース検索、分析、大規模言語モデルを強化する正確で文脈に富んだデータ。
スケーラブルなパフォーマンスと信頼性の確保
航空規模の文書処理の設計は、高スループットと高信頼性スループットに関しては、前述の通り、Document AIは文書を並行して取り込み、処理することができます。1,000ページを同時に処理最近のフィールドテストでは、file-q7xvjvhip1lffe4hbnkuac で確認されました。これは、複数の抽出ワーカーが同時に異なるページバッチを処理するという水平スケーリングアプローチによって実現されました。このシステムはクラウドネイティブで、負荷に応じて自動スケーリングできるため、解析対象が100ページでも10万ページでも、需要に合わせてリソースを割り当てることができます。AIチームにとって、このスケーラビリティは、データの取り込みから分析結果を得るまでの待ち時間を最小限に抑えることにつながります。これは、例えば、新しい航空機のドキュメントライブラリを分析プラットフォームに迅速に導入する必要がある場合などに非常に重要です。
信頼性は単なる正確さから生まれるのではなく、構造と文脈を正しく捉える。 例えば、 ドキュメント構造のキャプチャデータが下流で使用される際に、コンテキストが確実に把握されます。ベクトル検索で「トルク値:50 Nm」に関するスニペットが表示された場合でも、システムはそれがどのメンテナンスマニュアルのどのセクションから取得されたかを認識し、必要に応じてセクション全体またはページ画像を取得できます。これは検証において非常に重要であり、エンドユーザーがAI出力を信頼するのに役立ちます。エンドユーザーは、AIが使用した元のドキュメントスニペットをいつでも参照できます。当社のパイプラインの構造化出力には、これらのコンテキストマーカーが設計上含まれています。
さらに、このソリューションは現実世界の様々な文書でテストされています。航空業界の文書は、スタンプや手書きのスキャン、メーカー間でレイアウトがわずかに異なるなど、複雑なものになりがちです。Document AIは、アンサンブルOCRノイズの多いスキャンデータを処理する際には、複数のOCRエンジンと投票メカニズムを組み合わせたアプローチを採用し、部品番号のチェックサムチェックや日付形式のチェックなどの検証ルールを適用して、抽出の異常を検出します。これにより、スループットの限界を超えても、システムは高い精度を維持します。ボーイング社のIPCを用いた社内ベンチマークでは、OCRの文字精度は99.9%テキストレイヤーが既に存在する文書では、高度なOCRモデルのおかげで、スキャン画像のみでもわずかに低下する程度です。ドメイン固有の構造(マニュアルの目次や航海日誌のセクションなど)をキャプチャすることで、システムはエラーを分割して適切に回復することもできます。例えば、あるページの品質が特に悪い場合、バッチ全体を混乱させるのではなく、そのページだけを切り離してフラグを付けます。
AIエンジニアリングチームにとって、これらの機能により大きな悩みの種が解消されます。ドキュメントパイプラインから出力されるデータを信頼できるからです。OCRエラーのクリーンアップや、新しいドキュメントタイプごとにアドホックな正規表現を記述する手間が省けます。代わりに、この信頼性の高いデータレイヤー上に、強力なAIアプリケーション(予知保全モデル、ナレッジグラフ構築、コンプライアンス監査ツールなど)を構築することに集中できるようになります。
下流AIへの影響:RAG、LLM、検索
この高精度な抽出が下流のAIタスクにどのように貢献するかを改めて強調しておく価値がある。検索拡張生成(RAG)ここでは、大規模言語モデル(LLM)に、知識ベースから取得した関連文書やスニペットが補完されます。知識ベースが航空文書ベクターDBで、抽出がずさんな場合、LLMに無関係なテキストや不正確なテキストが与えられ、不正確な回答や幻覚的な回答が生成される可能性があります。一方、LLMに以下のテキストを入力すると、クリーンで正確なスニペットDocument AIパイプラインから得られるデータは、モデルが真実に基づいた回答を生成できることを意味します。フィールドレベルの精度を98%以上に高めることで、検索ヒットの精度(誤一致の減少)が大幅に向上し、航空業界のQ&Aにおける回答の質が向上することが確認されています。つまり、LLMは、文字化けした入力データに悩まされることなく、理解と回答作成という本来の業務に集中できるのです。その結果、エンジニアや意思決定者にとって、AIによる支援の信頼性は格段に向上します。
同じ論理は、生成を伴わない単純なセマンティック検索や質問応答システムにも当てはまります。例えば、航空会社は検索ポータル整備技術者が過去の修理記録やマニュアルを検索する際に役立ちます。検索の背後にあるインデックスが正確に抽出されたデータに基づいて構築されていれば、検索結果は信頼できます。つまり、返されるレコードには、検索語句や関連情報が確実に含まれています。そうでない場合、重要な文書が見落とされたり(再現率が低い)、誤った文書が見つかったり(誤検知)、ユーザーの信頼が損なわれる可能性があります。高精度な抽出により、「燃料ポンプのADコンプライアンス」と検索した場合でも、ノイズではなく、関連する耐空性指令文書とコンプライアンス記録が確実に表示されます。
AIモデルがどんなに進歩していても、最先端の1750億パラメータの変換器を使用していても、入力データの誤りによって出力が誤る可能性がある安全性と規制遵守が問われる航空業界において、これは単なる些細な不便ではなく、深刻なリスクです。だからこそ私たちは最上層の排気層にこだわっています。それは真実の唯一の情報源非構造化ドキュメントを、クリーンでクエリ可能な AI 対応の知識リポジトリに変換します。
結論:航空グレードAIの成功のための基盤の構築
航空分野の AI リーダーや技術チームにとって、メッセージは明確です。AIパイプラインの開始時にデータの精度に投資する大量かつ複雑な航空文書は、信頼できる情報源であり、そのデータをほぼ完璧な精度で抽出することが、AIシステムにその真実を解き放つ唯一の方法です。抽出品質を軽視するのは得策ではありません。節約した分は、後々AIのパフォーマンス低下によって帳消しになってしまいます。あるいは、データポイントの不具合によって重要な洞察を見逃してしまう可能性さえあります。98~99%以上の精度を誇る航空業界特化型のDocument AIを導入することで、予知保全やフリート最適化からコンプライアンス監査、インテリジェントアシスタントに至るまで、あらゆる下流アプリケーションのための強固な基盤を構築できます。
要約すれば、 高精度ドキュメントAIは航空グレードAIの要です膨大な量の非構造化書類を、信頼性の高い構造化データに変換します。これにより、LLM、ナレッジグラフ、分析ダッシュボード航空業界は飛躍的に成長し、安全性と効率性を高める正確で実用的な洞察を提供します。この洞察がなければ、どんなに強力なAIでも、不確かな入力にはつまずいてしまうでしょう。航空業界がデジタルトランスフォーメーションとAIを採用する中で、クリーンで正確なデータ抽出を基盤とする企業が決定的な優位性を獲得するでしょう。これは、飛行前に極めて信頼性の高いコンパスを持っているようなものです。コンパスがなければ離陸できないでしょう。同様に、信頼できるデータがなければAIの旅は始まりません。ドメイン調整されたモデル、堅牢なOCR、ベクターデータベースとのシームレスな統合を備えた高精度のDocument AIソリューションをパイプラインに組み込むことで、航空AIイニシアチブを確実かつ正確に開始できるようになります。
不確実な状況下で勢いを増す可能性のある航空機整備のトレンド
航空機の運航期間が長くなり、サプライチェーンは火薬庫のように不安定になり、テクノロジーは急速に進化しています。勢いを増すメンテナンスのトレンドと、運航維持と収益確保を目指す運航事業者にとっての意味を探ります。

April 10, 2026
ミッションコントロール:ミッションクリティカルな意思決定スピードを実現する高性能インテリジェンス基盤
私が航空宇宙、製造業、建設業界で話をするどのリーダーも、口をそろえて同じことを言います。
私たちのシステムはどんどん賢くなっていますが、現場が求めるスピードに見合うほど、私たちの意思決定は速くも安全にもなっていません。
高い完全性が求められる環境では、データと意思決定の間にあるギャップこそがリスクの蓄積する場所になります。業務がより複雑に、分散的に、そして時間に敏感になるにつれて、組織には単に高速であるだけでなく、検証可能で決定論的、かつ設計段階からセキュアであるインテリジェンスシステムが必要になります。
これは、Mission Controlの背後にあるエンジニアリング哲学です。Mission Control は、リアルタイムで監査可能かつ暗号学的に安全な意思決定スピードを実現するために構築された、高性能なインテリジェンス基盤です。

October 2, 2025
損傷許容度解析による適切な航空機部品の選択
航空安全の未来は部品にかかっています。純正で追跡可能な部品は、航空機の損傷耐性と性能を最大限に高め、安全性と調達効率を最大限に高めます。

September 30, 2025
航空業界の新市場への参入方法:部品サプライヤーのための完全ガイド
新たな航空市場への参入をお考えですか?サプライヤーが需要分析、PMA部品の管理、そして航空会社との信頼関係構築を行う方法を学びましょう。グローバル成長のための完全ガイドです。

